本文介绍了为什么要使用正则化以及如何在Keras中使用正则化来降低模型过拟合风险。
文章目录
- 1. 权重过大导致的问题
- 2. 正则化
- 3. 正则化使用技巧
- 3.1 在所有模型上使用
- 3.2 标准化输入数据 🐳
- 3.3 训练深层网络时使用
- 3.4 结合使用 L1和L2正则化
- 3.5 在训练好的网络上使用正则化 🐬
- 3.6 其它正则化方法 🐋
- 4. Keras 实现
- 4.1 Keras API
- 4.2 L1 正则化
- 4.3 L2 正则化
- 4.3 L1L2 正则化
- 4.4 自定义正则化函数 🐟
- 5. 网格搜索寻找最佳的正则化参数
代码环境:
python -3.7.6
tensorflow -2.1.0
神经网络学习一组权重,以最佳地将输入映射到输出。具有较大网络权重的网络可能表示网络不稳定,在该网络中,输入的较小变化可能导致输出的较大变化。这可能表明网络过度适合训练数据集,并且在对新数据进行预测时可能表现不佳。
该问题的解决方案是更新学习算法,使网络保持较小的权重,即权重正则化(weight regularization),该方法可以减少训练数据集的过拟合风险并提高模型泛化能力。
1. 权重过大导致的问题
训练神经网络一般使用随机梯度下降(SGD)算法,“训练”即学习权重向量和偏置的过程。
训练周期越长,模型越容易过度适应训练集的特征分布,从而导致过拟合。为了从训练集中提取特征,权重会增大,较大的权重会导致网络不稳定,即使输入数据发生较小的波动或引入随机噪声,也会导致输出有很大差异。也就就是说,模型在训练集上表现很好,但是在新数据集上表现很差,即泛化能力很差。
通常认为这样的模型具有较大的方差和较小的偏差。即模型对训练数据集中的某些样本敏感,比如收集数据过程中引入的噪声。
权重较大的模型比权重较小的模型更为复杂,虽然拟合能力很强,但很容易导致过拟合。根据奥卡剃刀定律:“如无必要,勿增实体”,在应用过程中,一般从较简单的模型开始建模。
另一个可能的问题是,可能有许多输入变量,每一个都与输出变量有不同程度的相关性。有时可以使用方法来帮助选择输入变量,但通常变量之间的相互关系并不明显。
对于不太相关或不相关的模型输入,使用较小的权重甚至零权重可以使得模型专注于学习。这也可以减少模型容量,提高泛化能力,避免陷入局部最优。
2. 正则化
正则化又称为惩罚,即通过选择解决学习问题的最小向量来抑制权重向量的任何不相关分量。常用的正则化有L1正则化,又称为稀疏正则化;L2正则化,又称为权重衰减正则化。L1和L2分别表示L1范数和L2范数。其计算公式如下:
l1l_1l1 范数表示向量的各个元素的绝对值之和。其公式为:
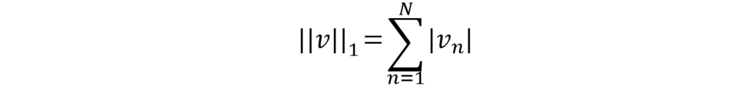
l2l_2l2 范数表示向量的各个元素的平方和再开平方。

其中,vvv 表示一个 NNN 维向量。范数(Norm) 是一个表示向量“长度”的函数,为向量空间内的所有向量赋予非零的正长度或大小。
加入正则化后,最优化目标函数变为:

其中 L(⋅)L(·)L(⋅) 为损失函数,NNN 为训练样本的数量,f(⋅)f(·)f(⋅) 为待学习的神经网络,θθθ 为其参数,lpl_plp 表示范数,通常为 l1l_1l1 范数和 l2l_2l2 范数,λ表示正则化系数。
L1 正则化鼓励模型将权重设置为0或1,从而使模型稀疏。L2 正则化又称为 岭回归(ridge regression) 或 Tikhonov 正则化。L2 是更常用的正则化方法。
通过之前的机器学习基石课程中知道,L2正则化中包含一个拉格朗日乘子系数 α\alphaα,称为惩罚项或正则化项,控制对模型权重惩罚的力度,其值介于0和1之间。如果 α\alphaα 选择的大小合适,权重衰减会抑制静态噪声对目标的某些影响。越大的惩罚项表示对模型的拟合能力限制越大。
权重的向量范数通常是逐层计算的,而不是整个网络中的。尽管默认情况下通常在每个层上使用相同的 α\alphaα 值,但这在选择所使用的正则化类型(例如,输入层使用L1,其它层使用L2)的类型方面提供了更大的灵活性,并且在 α\alphaα 值方面具有灵活性。
在神经网络的情况下,有时需要为网络的每一层使用系数不同的惩罚项。因为搜索多个合适的超参数很耗费计算资源,所以在所有层上使用相同的权重衰减只是为了减小搜索空间的大小,但仍然是合理的。
3. 正则化使用技巧
3.1 在所有模型上使用
权重正则化是一种通用方法。它可以与大多数的神经网络模型一起使用,尤其是多层感知器,卷积神经网络和长短期记忆递归神经网络等最常见的网络类型。对于LSTM,可能需要对输入层和LSTM层使用不同的惩罚项。
3.2 标准化输入数据 🐳
当输入变量具有不同的比例时,网络权重的比例将相应地变化。这在使用权重正则化时引入了一个问题,必须添加权重的绝对值或平方值以用于惩罚。可以通过标准化或标准化输入变量来解决此问题。
常用的做法是将原始数据减去均值,再除以标准差。
3.3 训练深层网络时使用
对于较大的网络(更多的层或更多的节点),更容易导致过拟合。因此使用正则化来降低过拟合风险。
3.4 结合使用 L1和L2正则化
因为这两个正则化方法各有其特点,所以结合使用不失为一种提高模型性能的方法。
3.5 在训练好的网络上使用正则化 🐬
例如,可以先不使用正则化训练模型,然后再使用正则化更新模型,以减小已经表现良好的模型的权重大小。
3.6 其它正则化方法 🐋
权重惩罚的另一种可能类型是:
e∣x∣–1e^{|x|}–1e∣x∣–1
它虽然不像L1那样强烈,却鼓励零权重,同时也像L2一样强力惩罚较大的权重(但更强)。

4. Keras 实现
4.1 Keras API
tensorflow.keras 提供了三个正则化关键字参数,分别是:
kernel_regularizer:正则化器在层的内核上添加惩罚项;bias_regularizer:正则化器对层的偏差添加惩罚项;activity_regularizer:正则化器对层的输出添加惩罚项。
简单示例:
from tensorflow.keras import layers
from tensorflow.keras import regularizerslayer = layers.Dense(units=64,kernel_regularizer=regularizers.l1_l2(l1=1e-5, l2=1e-4),bias_regularizer=regularizers.l2(1e-4),activity_regularizer=regularizers.l2(1e-5)
)
4.2 L1 正则化
tf.keras.regularizers.l1(l=0.01)
【The L1 regularization penalty is computed as: loss = l * reduce_sum(abs(x))】
参数说明:
l: Float; L1 regularization factor.
4.3 L2 正则化
tf.keras.regularizers.l2(l=0.01)
【The L2 regularization penalty is computed as: loss = l * reduce_sum(square(x))】
参数说明:
l: Float; L2 regularization factor.
4.3 L1L2 正则化
tf.keras.regularizers.l1_l2(l1=0.01, l2=0.01)
4.4 自定义正则化函数 🐟
1.简单方法
def my_regularizer(x):return 1e-3 * tf.reduce_sum(tf.square(x))
2.Regularizer 子类
如果需要通过各种参数(例如l1和中的l2参数l1_l2)配置正则化,则应实现为tf.keras.regularizers.Regularizer 的子类。
class MyRegularizer(regularizers.Regularizer):def __init__(self, strength):self.strength = strengthdef __call__(self, x):return self.strength * tf.reduce_sum(tf.square(x))
5. 网格搜索寻找最佳的正则化参数
在掉头发调参的时候,如果确定正则化可以提高模型性能,那么就需要通过网格搜索来确定最佳的正则化参数。
一般的做法的是,首先在0.0到0.1之间的各个数量级上进行网格搜索,然后在找到某个级别后,再对该级别进行网格搜索。
from sklearn.datasets import make_moons
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.regularizers import l2
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 150
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
values = [1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6]all_train, all_test = list(), list()for param in values:model = Sequential()model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(param)))model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])model.fit(trainX, trainy, epochs=4000, verbose=0)_, train_acc = model.evaluate(trainX, trainy, verbose=0)_, test_acc = model.evaluate(testX, testy, verbose=0)print('Param: %f, Train: %.3f, Test: %.3f' % (param, train_acc, test_acc))all_train.append(train_acc)all_test.append(test_acc)plt.semilogx(values, all_train, label='train', marker='o')
plt.semilogx(values, all_test, label='test', marker='o')
plt.legend()
plt.show()
输出:
Param: 0.100000, Train: 0.967, Test: 0.829
Param: 0.010000, Train: 1.000, Test: 0.943
Param: 0.001000, Train: 1.000, Test: 0.943
Param: 0.000100, Train: 1.000, Test: 0.929
Param: 0.000010, Train: 1.000, Test: 0.914
Param: 0.000001, Train: 1.000, Test: 0.914

可以看出,0.1的正则化参数模型表现比较差;0.01是比较好的正则化参数。
参考:
https://machinelearningmastery.com/weight-regularization-to-reduce-overfitting-of-deep-learning-models/
https://machinelearningmastery.com/how-to-reduce-overfitting-in-deep-learning-with-weight-regularization/
https://keras.io/getting_started/
https://keras.io/api/layers/regularizers/







 京公网安备 11010802041100号
京公网安备 11010802041100号