一个衡量图像分割精度的重要指标,mIOU可解释为平均交并比,即在每个类别上计算Iou值(真正样本数量 / (真正样本数量+假负样本数量+假正样本数量))

优点:在不做下采样的情况下,加大感受野
缺点:1. 网格效应,如果仅仅多次堆叠多个空洞率为2 的 3*3卷积核,会发现并不是所有输入像素点都会得到计算,也就是卷积核不连续。在逐像素的预测任务中,这是致命的。
如何克服网格效应?
当填充为0 步幅为1:

步幅为s:在行列之间插入 s-1行或列


CenterNet是anchor-free,与yolov3相比,速度相同的情况下,CenterNet精度比yolov3高好几个点,不需要NMS,直接检测目标中心点和大小。
算法流程:
CSP是一种思想,与resnet、densenet类似。它将feature map拆分两个部分,一部分进行卷积操作、另一个部分与上一部分卷积操作的结果进行cat。解决了三个问题:
Faster R-CNN是anchor-based和two-stage类型检测器,分为四个部分
Cascade R-CNN 在Faster R-CNN上改进,通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同,Cascade R-CNN的几个检测网络是基于不同IOU阈值确定的正负样本上训练得到的。简单的来说cascade R-CNN是由一系列检测模型组成,每个检测模型都基于不同IOU阈值的正负样本训练得到,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,界定正负样本的IOU阈值是不断上升的。
在使用线性回归的时候,基本假设是噪声服从正态分布,当噪声符合正态分布时,因变量则符合正态分布,因此使用mse的时候实际上是假设y服从正态分布。
在CNN中,由于输入图片通过CNN提取特征后,输出尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进一步计算(图像分割),小分辨率到大分辨率操作为上采样。
参数量:

FLOPs:

add和concat分支操作统称为shortcut,add是在ResNet中提出的,增加信息的表达。concat操作是Inception首次使用,被DenseNet发扬光大,保留了一些原始的特征,增加特征的数量,使得有效信息流继续向后传递。
恢复出原始的某一层所学到的特征,因此引入了λ和β,让我们网络可以学习恢复出原始网络所要学习的特征分布。比如数据分布不平衡。
V1:googlenet某些大卷积核换成小卷积
V2:输入的时候加入BN,训练起来收敛更快,可以减少dropout的使用
V3:GoogleNet里面一些7x7的卷积变成 1x7和7x1两层串联,同理3x3。这样加速了计算,增加网络的非线性、减少过拟合的概率。
V4:原来的inception加上resnet的方法
交叉熵损失函数关于输入权重的梯度表达式不含激活函数梯度,而均方误差损失函数中存在激活函数的梯度(预测值接近1或0,会导致其梯度接近0),由于常用的sigmoid/tanh存在梯度饱和区,使得MSE对权重的梯度很小。
泛化误差 = 方差 + 偏差 + 噪声
降低方差(过拟合)的方法:
数据:
网络结构:
正则化L1、L2、BN
dropout
宏观:
降低偏差(欠拟合)的方法:
网络中间:
宏观:
算法的具体步骤描述:
优点:
缺点:
one-stage算法正负样本严重不均衡,two-stage算法利用RPN网络,将正负样本控制在1:3左右
原理:
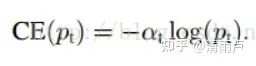
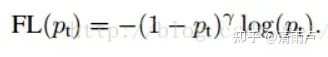
综合:两个参数α和λ协调来控制, 本文作者采用α=0.25,λ=2 效果最好
原理:在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性
常用的正则化手段:
多个sigmoid与一个softmax都可以进行多分类,如果多个类别之间是互斥,就应该使用softmax,即这个东西只可能是几个类别中的一种。如果多个类别之间不是互斥的,使用多个sigmoid。

max pooling:下一层的梯度会原封不动地传到上一层最大值所在位置的神经元,其他梯度为0
average pooling:下一层的梯度会平均地分配到上一层的对应相连区块的所有神经元
pooling作用:
增大感受野 2. 平移不变性 3. 降低优化难度
缺点:造成梯度稀疏,丢失信息
Recall = R=TP/(TP+FN) Precision:P=TP/(TP+FP)
ROC:常用于评价二分类的优劣
AUC:被定义为ROC曲线下的面积,取值范围0.5到1之间 AUC计算公式:https://blog.csdn.net/ustbbsy/article/details/107025087
F1-score:又称调和平均数,precision和recall是相互矛盾的,当recall越大时,框就越多,导致precision就会越小,反之亦然。通常使用F1-score来调和precision和recall,F1 score结果取决于precision和recall。

pytorch的多GPU处理api:torch.nn.DataParallel(module, device_ids),其中module是要执行的模型,而device_ids则是指定并行GPU id 列表
并行处理机制是,首先将模型加载到主GPU上,然后再将模型复制到各个指定的从GPU中,然后输入数据按照batch维度进行划分,每个GPU分配到的数据为batch/gpu个数。每个GPU将针对各自的输入数据独立进行训练,最后将各个GPU的loss进行求和,再用反向传播更新单个GPU上的模型参数,再将更新后的模型参数复制到剩余指定的GPU中,这样就完成了一次迭代计算。
模型误差 = 方差+ 偏差+不可避免的误差
偏差:预测值和真实值之间的差距。偏差越大,越偏离真实数据
方差:描述的是预测值的变化范围,离散程度。方差越大,数据分布越分散。
KL散度也叫相对熵,用于度量两个概率分布之间的差异程度。

KL散度又叫相对熵, KL散度 = 信息熵 - 交叉熵
神经网络在做非线性变换前的激活输入值随着网络深度加深,其分布逐渐发生偏移(內部协变量偏移)。之所以训练收敛慢,一般是整体分布逐渐往非线性函数的区间两端靠近,导致反向传播底层网络训练梯度消失。BN就是通过一定的正则化手段,每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布。

其中γ和β分别是缩放因子和偏移量,因为减去均值除以方差未必是最好的分布。所以要加入两个可学习变量来完善数据分布以达到比较好的效果。
训练阶段:BN层对每个batch的训练数据进行标准化,即用每一批数据的均值和方差
测试阶段:只输入单个测试样本,因此这个时候用的均值和方差是整个数据集训练后的均值和方差,可以通过滑动平均法求得。简单来说,均值就是直接计算所有batch 均值的平均值,然后对于标准偏差采用每个batch方差的无偏估计。
因为用整个数据集的均值和方差容易过拟合,对于BN,其实就是对每一batch数据标准化到一个相同的分布,而不同的batch数据均值和方差会有一定的差异,这个差异能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
γ和β是需要学习的参数,在CNN中,某一层的batch大小为M,那么做BN的参数量为M*2
优点:
缺点:
传统NMS缺点:
思路:不要直接删除所有IOU大于阈值的框,而是降低置信度。
(1)线性加权

(2)高斯加权
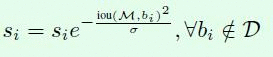
两种改进的思想都是降低框的置信度,从而在第一阶段就被筛选出去。考虑了iou和置信度的关系。
假设:如果不使用残差模块,输出为5.1,期望输出为5,如果想要学习输出为5,这个变化率比较低,学习起来是比较困难的。
但是如果设计一个H(X) = F(x)+5=5.1,使得F(x)=0.1,那么学习目标就让0.1变成0,这个是比较简单的,即引入残差模块后的映射对输出变化更加敏感了。
进一步理解:如果F(x) = 5.1,现在继续训练模型,使得映射函数=5。变化率为(5.1-5)/5.1 = 0.02,如果不⽤残差模块的话可能要把学习率从0.01设置为0.0000001。层数少还能对付,⼀旦层数加深的话可能就不太好使了。
resnet真正起作用的层只在中间,深层作用比较小。(在深层网络只有恒等映射在学习,等价于很多小网络在ensemble)
v1网络结构在VGG基础上使用depthwise 卷积(空间信息)和pointwise 卷积(通道信息)构成,在保证不损失太大精度的同时,大幅降低模型参数量。
v2网络结构使用linear bottleneck(线性变换)来代替原本的非线性激活函数,实验证明使用linear bottleneck 可以在小网络中较好地保留有用特征信息。Inverted Residuals 与resnet的通道间操作正好相反。由于v2使用linear bottleneck结构,使其提取的特征维度整体偏低(relu在低维数据下会出现很多0),如果只是使用低维的feature map效果并不好。因此我们需要高维的feature map来进行补充。
v3在整体上有两大创新:1.由资源受限的NAS执行模块级搜索;由netadapt执行局部搜索,对各个模块确定之后网络层的微调。2. 网络结构改进:进一步减少网络层数,并引入h-swish激活函数。作者发现swish激活函数能有效提高网络的精度,然而swish计算量太大了。

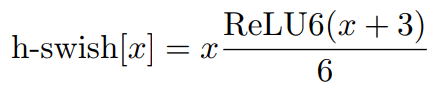
**特点:**1. VIT直接将标准的transformer结构直接用于图像分类,其模型结构中不含CNN。2.为了满足transformer输入结构要求,将图片打成patch输入到网络中。在最后的输出端,使用了Class Token形式进行分类预测。3. transformer结构vit在大规模数据集上预训练过后,再迁移学习,可以在特定任务上达到SOTA性能。可以具体分成如下几个部分:(1)图像分块嵌入(2)多头注意力结构(3)多层感知机结构(4)使用droppath,class Token, positional encoding
EfficientNet是通过网络搜索从深度、宽度和输入图片分辨率三个角度共同调节搜索得来得模型,这三个维度并不是相互独立的,对于输入图像分辨率更高的情况,需要有更深的网络来获得更大的感受视野,并且需要有更多的通道来获取更精确的特征。
EfficientNet模型的内部是通过多个MBConv卷积模块实现的,实验证明depthwise 卷积在大模型中依旧非常有效的,因为depthwise 卷积较于标准卷积有更好的特征提取表达能力。使用了DropConnect方法来代替传统dropout来防止过拟合,dropConnect与dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机丢弃,而是对隐层节点的输入进行随机丢弃。


装饰器允许通过将现有函数传递给装饰器,从而向现有函数添加一些额外的功能,该装饰器将执行现有函数的功能和添加的额外功能。
import logging
def use_log(func):
def wrapper(*args, **kwargs):
logging.warning('%s is running' % func.__name__)
return func(*args, **kwargs)
return wrapper
@use_log
def bar():
print('I am bar')
------------结果如下------------
WARNING:root:bar is running
I am bar
在python中,用一个变量给另外一个变量赋值,其实就是给当前内存中的对象增加一个“引用”而已。
**注意:**浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含其他对象的对象,如列表、类实例等。而对于数字、字符串以及其他原子类型,没有拷贝一说,产生的都是原对象的引用。
解释语言的优点是可移植性好,缺点是运行需要解释环境,运行起来比编译语言要慢,占用的资源也要多一点,代码效率低
编译语言的优点是运行速度快,代码效率高,编译后程序不可以修改,保密性好。缺点是代码需要经过编译才能运行,可移植性较差,只能在兼容的操作系统上运行。

在python中,使用引用计数进行垃圾回收;同时通过标记-清除算法解决容器对象可能产生的循环引用问题,最后通过分代回收算法提高垃圾回收效率
首先,xrange和range函数的用法完全相同,不同的地方是xrange函数生成的不是一个list对象,而是一个生成器。要生成很大的数字序列,使用xrange会比range的性能优很多,因为不需要一上来就开辟很大的内存空间。在python3中,xrange函数被移除了,只保留了range函数,但是range函数的功能结合了xrange和range。之前python2,range中是list类型,python3中是range类型。










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有