作者:瑞景地产王琴 | 来源:互联网 | 2023-10-11 19:11
最优化问题在机器学习中有非常重要的地位,很多机器学习算法最后都归结为求解最优化问题。在各种最优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。
最优化问题是求解函数极值的问题,包括极大值和极小值。微积分为我们求函数的极值提供了一个统一的思路:找函数的导数等于0的点,因为在极值点处,导数必定为0。这样,只要函数的可导的,我们就可以用这个万能的方法解决问题,幸运的是,在实际应用中我们遇到的函数基本上都是可导的。
在机器学习之类的实际应用中,我们一般将最优化问题统一表述为求解函数的极小值问题,即:

其中
可导函数在某一点处取得极值的必要条件是梯度为0,梯度为0的点称为函数的驻点,这是疑似极值点。需要注意的是,梯度为0只是函数取极值的必要条件而不是充分条件,即梯度为0的点可能不是极值点。
至于是极大值还是极小值,要看二阶导数/Hessian矩阵,Hessian矩阵我们将在后面的文章中介绍,这是由函数的二阶偏导数构成的矩阵。这分为下面几种情况:
如果Hessian矩阵正定,函数有极小值;如果Hessian矩阵负定,函数有极大值;如果Hessian矩阵不定,则需要进一步讨论
这和一元函数的结果类似,Hessian矩阵可以看做是一元函数的二阶导数对多元函数的推广。一元函数的极值判别法为,假设在某点处导数等于0,则:
如果二阶导数大于0,函数有极小值;如果二阶导数小于0,函数有极大值;如果二阶导数等于0,情况不定
直接求函数的导数/梯度,然后令导数/梯度为0,解方程,问题不就解决了吗?事实上没这么简单,因为这个方程可能很难解。对于有指数函数,对数函数,三角函数的方程,我们称为超越方程,求解的难度并不比求极值本身小。精确的求解不太可能,因此只能求近似解,这称为数值计算。工程上实现时通常采用的是迭代法,它从一个初始点
这张图中的函数有3个局部极值点,分别是A,B和C,但只有A才是全局极小值,梯度下降法可能迭代到B或者C点处就终止。
鞍点 :指梯度为0,Hessian矩阵既不是正定也不是负定,即不定的点,鞍点处附近存在有正有负的的二阶导,即鞍点的hessian矩阵是不定的,在最优化问题中,只有hessian矩阵不定时才会出现鞍点(半正定也不会)!。下面是鞍点的一个例子,假设有函数:
在这里,梯度下降法遇到了鞍点,认为已经找到了极值点,从而终止迭代过程,而这根本不是极值点。对于怎么逃离局部极小值点和鞍点,有一些解决方案,在这里我们暂时不细讲,以后有机会再专门写文章介绍。对于凸优化问题,不会遇到上面的局部极小值与鞍点问题,即梯度下降法一定能找到全局最优解。
梯度下降法有大量的变种,它们都只利用之前迭代时的梯度信息来构造每次的更新值,最流行的:动量优化,Nesterov 加速梯度,AdaGrad,RMSProp, Adam 优化.详情参见:快速优化器
黑塞矩阵
黑塞矩阵(Hessian Matrix,是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。黑塞矩阵常用于牛顿法解决优化问题,利用黑塞矩阵可判定多元函数的极值问题。在工程实际问题的优化设计中,所列的目标函数往往很复杂,为了使问题简化,常常将目标函数在某点邻域展开成泰勒多项式来逼近原函数,此时函数在某点泰勒展开式的矩阵形式中会涉及到黑塞矩阵。
在数学中, 海森矩阵(Hessian matrix或Hessian)是一个自变量为向量x的实值函数f的二阶偏导数组成的方块矩阵, 此函数如下:  ,如果f的所有二阶导数都存在, 那么f的海森矩阵:
,如果f的所有二阶导数都存在, 那么f的海森矩阵:
 (1)
(1)
将二元函数的泰勒展开式推广到多元函数,则在X(0)点处的泰勒展开的矩阵形式为:


黑塞矩阵是由目标函数f在点X处的二阶偏导数组成的n∗n阶对称矩阵。
Hessian矩阵性质:
(1)如果是正定矩阵,则临界点处是一个局部极小值
(2)如果是负定矩阵,则临界点处是一个局部极大值
(3)如果是不定矩阵,则临界点处不是极值
判断一个矩阵是否是正定方法 :
1、顺序主子式:实对称矩阵为正定矩阵的充要条件是的各顺序主子式都大于零。
2、特征值:矩阵的特征值全大于零,矩阵为正定,矩阵的特征值全非负,矩阵为半正定。矩阵的特征值全小于零,矩阵为负定。否则是不定的。
from:https://blog.csdn.net/u010700066/article/details/81836166

二次规划的全局最优:https://blog.csdn.net/nickkissbaby_/article/details/89419423
牛顿法
除了前面说的梯度下降法,牛顿法也是机器学习中用的比较多的一种优化算法。 但对于非线性优化问题, 牛顿法提供了一种求解的办法. 假设任务是优化一个目标函数 f, 求函数 f的极大极小问题, 可以转化为求解函数 f的导数f′=0的问题, 这样求可以把优化问题看成方程求解问题(f′=0).
牛顿法的基本思想是利用迭代点处的一阶导数(梯度)和二阶导数(Hessen矩阵)对目标函数进行二次函数近似,然后把二次模型的极小点作为新的迭代点(f′=0的点),并不断重复这一过程,直至求得满足精度的近似极小值。它使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快,而且能高度逼近最优值。
1、基本牛顿法的原理
考虑同样的一个无约束最优化问题:

牛顿法的每次迭代就是让一阶导为零,当且仅当 Δx无线趋近于0。即:

拟牛顿法(Quasi-Newton Methods)
拟牛顿法是求解非线性优化问题最有效的方法之一,拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代
我们尽可能地利用上一步的信息来选取
从而得到

这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
DFP方法
记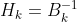 ,DFP公式为:
,DFP公式为:
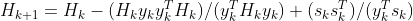 。
。
DFP方法是秩-2更新的一种,由它产生的矩阵B_k是正定的,而且满足这样的极小性: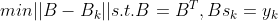 。
。
from:http://www.cnblogs.com/shixiangwan/p/7532830.html
坐标下降法
坐标上升与坐标下降可以看做是一对,坐标上升是用来求解max最优化问题,坐标下降用于求min最优化问题,但是两者的执行步骤类似,执行原理相同。
例如要求接一个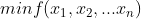 的问题,其中各个
的问题,其中各个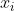 是自变量,如果应用坐标下降法求解,其执行步骤就是:
是自变量,如果应用坐标下降法求解,其执行步骤就是:
1.首先给定一个初始点,如 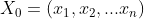
2.for dim=1:n
固定;(其中i是除dim以外的其他所有维度)
以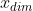 为自变量求取使得f取得最小值的;
为自变量求取使得f取得最小值的;
end
3.循环执行步骤2,直到f的值不再变化或变化很小。
其关键点就是每次只变换一个维度,而其他维度都用当前值进行固定,如此循环迭代,最后得到最优解。


![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)








 京公网安备 11010802041100号
京公网安备 11010802041100号