作者:顾旭东-夏天 | 来源:互联网 | 2023-10-10 15:19
贝叶斯分类器:先验概率P(c)类c下单词总数整个训练样本的单词总数类条件概率P(tk|c)(类c下单词tk在各个文档中出现过的次数之和1)(类c下单词总数|V|)V是
贝叶斯分类器:
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|)
V是训练样本的单词表(即抽取单词,单词出现多次,只算一个),|V|则表示训练样本包含多少“个”单词。P(tk|c)可以看作是单词tk在证明d属于类c上提供了多大的证据,而P(c)则可以认为是类别c在整体上占多大比例(有多大可能性)。
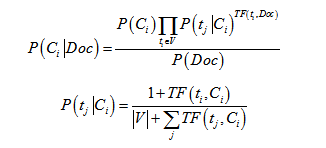
注:在实际计算过程,特征维度较,单个概率较小,连乘的结果会造成精度丢失,因此采用对数函数对概率进行放大,而且不需要计算P(Doc),即:
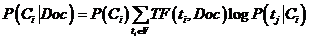
预测算法是根据上述公式计算argmax{P(Ci|Doc)}
from scipy import sparse,io
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from numpy import *
import warnings
warnings.filterwarnings("ignore")class Naivebayes:N = [] k = 0 n = 0 m = 0 category = [] log_probability_c = [] log_probability_t_c=[] def __init__(self, X, Y):if len(X) != len(Y):print 'samples\' length not equal labels\' length'elif len(Y) == 0:print 'samples\' size is zero'else:self.m = len(Y)self.n = len(X[0])D = []for i in range(self.m):if Y[i] not in self.category:self.category.append(Y[i])D.append([])D[-1].append(X[i])else:D[self.category.index(Y[i])].append(X[i])for i in range(len(self.category)):self.log_probability_c.append(len(D[i]))self.log_probability_c = log(self.log_probability_c)self.k = len(self.category)self.N = zeros((self.k, self.n))for i in range(self.k):self.N[i] = array(D[i]).sum(0)self.log_probability_t_c = self.N + 1s = self.log_probability_t_c.sum(1)self.log_probability_t_c = log(self.log_probability_t_c / s.reshape(len(s), 1))def predict(self, x):p = self.log_probability_c + x.dot(self.log_probability_t_c.transpose())i = p.argmax(1)label = []for j in range(len(i)):label.append(self.category[i[j]])return labelif __name__ == '__main__':data = io.loadmat('SetMat1.mat')vectormat = data['trainSet']labeled_names = data['train_labeled'][0]labeled_names1 = data['test_labeled'][0]vectormat1 = data['testSet']nb = Naivebayes(vectormat, labeled_names)labels = nb.predict(vectormat1)calculate_result(labeled_names1,labels)c = zeros((10,10), dtype=int)for i in range(len(labels)):c[labeled_names1[i]-1][labels[i]-1] = c[labeled_names1[i]-1][labels[i]-1] + 1print c
运行结果
中间数据采用的是TF\IDF值,依据词频做了简单特征筛选
predict info:
accuracy:0.779
precision:0.759
recall:0.779
f1-score:0.735
使用Bool型特征(one-hot)则有明显提高
count_vec = CountVectorizer(binary = True,decode_error=’replace’)
predict info:
accuracy:0.849
precision:0.835
recall:0.849
f1-score:0.824
[[ 705 0 3 5 0 0 2 0 4 0][ 0 1 0 3 51 0 0 0 1 0][ 13 0 165 0 0 0 0 3 8 0][ 30 0 3 1051 0 0 1 0 2 0][ 0 1 0 5 126 0 1 4 12 0][ 0 0 0 1 1 40 86 0 3 0][ 0 0 1 1 0 8 166 0 3 0][ 3 0 49 1 11 0 0 16 9 0][ 0 0 1 7 3 0 11 0 95 0][ 0 1 0 3 64 0 0 1 2 0]]





![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号
京公网安备 11010802041100号