本文目录一览:
1、request库用python3怎么伪装header爬取知乎
2、python爬取知乎首页问题
3、Python爬虫可以爬取什么
4、Python爬取知乎与我所理解的爬虫与反爬虫
5、如何使用python爬取知乎数据并做简单分析
python网页抓取功能非常强大,使用urllib或者urllib2可以很轻松的抓取网页内容。但是很多时候我们要注意,可能很多网站都设置了防采集功能,不是那么轻松就能抓取到想要的内容。
python爬取知乎首页问题
唔 可能是你没有登录成功啊
因为发现-知乎这个链接是不用登录就能抓的
但是这个知乎没有登录不行
看了下知乎登录不是这么简单的 你没有登录成功
Python爬虫可以爬取什么
Python爬虫可以爬取的东西有很多,Python爬虫怎么学?简单的分析下:
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
安居客、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
拉勾网、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。
爬虫是入门Python最好的方式,没有之一。Python有很多应用的方向,比如后台开发、web开发、科学计算等等,但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习Python数据分析、web开发甚至机器学习,都会更得心应手。因为这个过程中,Python基本语法、库的使用,以及如何查找文档你都非常熟悉了。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。比如有人认为学爬虫必须精通 Python,然后哼哧哼哧系统学习 Python 的每个知识点,很久之后发现仍然爬不了数据;有的人则认为先要掌握网页的知识,遂开始 HTMLCSS,结果入了前端的坑,瘁……
但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现,但建议你从一开始就要有一个具体的目标。
在目标的驱动下,你的学习才会更加精准和高效。那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。这里给你一条平滑的、零基础快速入门的学习路径。
1.学习 Python 包并实现基本的爬虫过程
2.了解非结构化数据的存储
3.学习scrapy,搭建工程化爬虫
4.学习数据库知识,应对大规模数据存储与提取
5.掌握各种技巧,应对特殊网站的反爬措施
6.分布式爬虫,实现大规模并发采集,提升效率
一
学习 Python 包并实现基本的爬虫过程
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。这样下来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、腾讯新闻等基本上都可以上手了。
当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化,这样,知乎、时光网、猫途鹰这些动态的网站也可以迎刃而解。
二
了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。
开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为csv这样的文件。
当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
三
学习 scrapy,搭建工程化的爬虫
掌握前面的技术一般量级的数据和代码基本没有问题了,但是在遇到非常复杂的情况,可能仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。
scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而它最让人惊喜的还是它超高的性能,让你可以将爬虫工程化、模块化。
学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。
四
学习数据库基础,应对大规模数据存储
爬回来的数据量小的时候,你可以用文档的形式来存储,一旦数据量大了,这就有点行不通了。所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。
MongoDB 可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。
因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。
五
掌握各种技巧,应对特殊网站的反爬措施
当然,爬虫过程中也会经历一些绝望啊,比如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬虫的手段,当然还需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。
往往网站在高效开发和反爬虫之间会偏向前者,这也为爬虫提供了空间,掌握这些应对反爬虫的技巧,绝大部分的网站已经难不到你了.
六
分布式爬虫,实现大规模并发采集
爬取基本数据已经不是问题了,你的瓶颈会集中到爬取海量数据的效率。这个时候,相信你会很自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握 Scrapy + MongoDB + Redis 这三种工具。
Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。
所以有些东西看起来很吓人,但其实分解开来,也不过如此。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
你看,这一条学习路径下来,你已然可以成为老司机了,非常的顺畅。所以在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这种简单的入手),直接开始就好。
因为爬虫这种技术,既不需要你系统地精通一门语言,也不需要多么高深的数据库技术,高效的姿势就是从实际的项目中去学习这些零散的知识点,你能保证每次学到的都是最需要的那部分。
当然唯一麻烦的是,在具体的问题中,如何找到具体需要的那部分学习资源、如何筛选和甄别,是很多初学者面临的一个大问题。
以上就是我的回答,希望对你有所帮助,望采纳。
Python爬取知乎与我所理解的爬虫与反爬虫
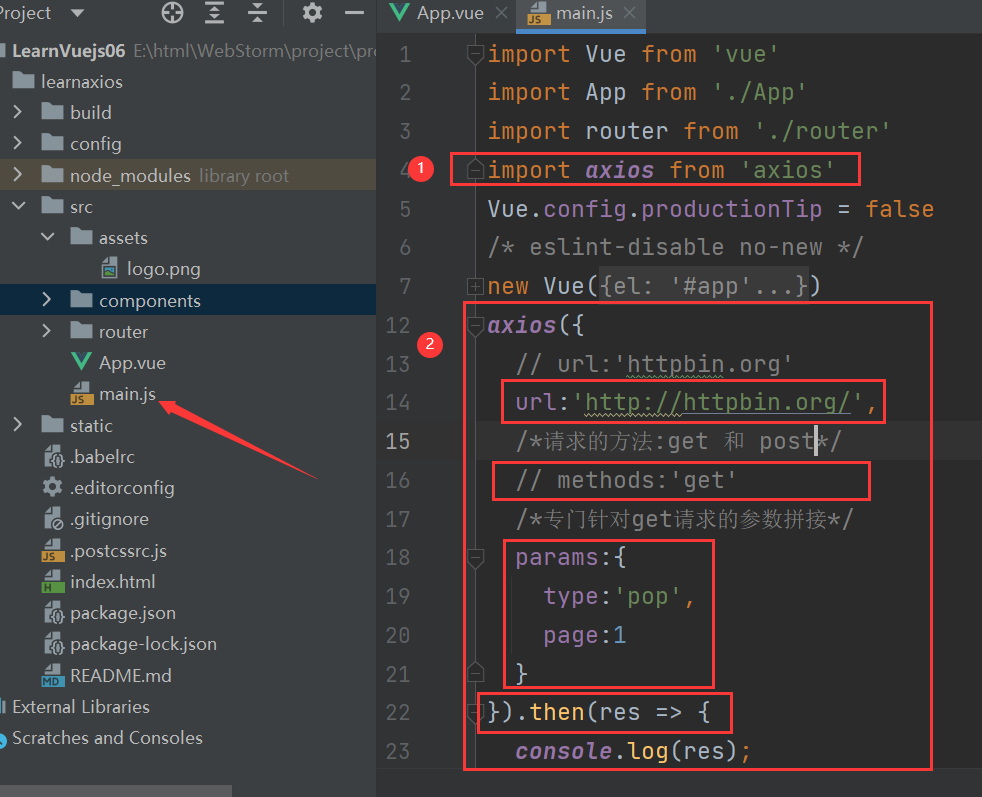
关于知乎验证码登陆的问题,用到了Python上一个重要的图片处理库PIL,如果不行,就把图片存到本地,手动输入。
通过对知乎登陆是的抓包,可以发现登陆知乎,需要post三个参数,一个是账号,一个是密码,一个是xrsf。
这个xrsf隐藏在表单里面,每次登陆的时候,应该是服务器随机产生一个字符串。所有,要模拟登陆的时候,必须要拿到xrsf。
用chrome (或者火狐 httpfox 抓包分析)的结果:
所以,必须要拿到xsrf的数值,注意这是一个动态变化的参数,每次都不一样。
拿到xsrf,下面就可以模拟登陆了。
使用requests库的session对象,建立一个会话的好处是,可以把同一个用户的不同请求联系起来,直到会话结束都会自动处理COOKIEs。
注意:COOKIEs 是当前目录的一个文件,这个文件保存了知乎的COOKIE,如果是第一个登陆,那么当然是没有这个文件的,不能通过COOKIE文件来登陆。必须要输入密码。
这是登陆的函数,通过login函数来登陆,post 自己的账号,密码和xrsf 到知乎登陆认证的页面上去,然后得到COOKIE,将COOKIE保存到当前目录下的文件里面。下次登陆的时候,直接读取这个COOKIE文件。
这是COOKIE文件的内容
以下是源码:
运行结果:
反爬虫最基本的策略:
爬虫策略:
这两个都是在http协议的报文段的检查,同样爬虫端可以很方便的设置这些字段的值,来欺骗服务器。
反爬虫进阶策略:
1.像知乎一样,在登录的表单里面放入一个隐藏字段,里面会有一个随机数,每次都不一样,这样除非你的爬虫脚本能够解析这个随机数,否则下次爬的时候就不行了。
2.记录访问的ip,统计访问次数,如果次数太高,可以认为这个ip有问题。
爬虫进阶策略:
1.像这篇文章提到的,爬虫也可以先解析一下隐藏字段的值,然后再进行模拟登录。
2.爬虫可以使用ip代理池的方式,来避免被发现。同时,也可以爬一会休息一会的方式来降低频率。另外,服务器根据ip访问次数来进行反爬,再ipv6没有全面普及的时代,这个策略会很容易造成误伤。(这个是我个人的理解)。
通过COOKIE限制进行反爬虫:
和Headers校验的反爬虫机制类似,当用户向目标网站发送请求时,会再请求数据中携带COOKIE,网站通过校验请求信息是否存在COOKIE,以及校验COOKIE的值来判定发起访问请求的到底是真实的用户还是爬虫,第一次打开网页会生成一个随机COOKIE,如果再次打开网页这个COOKIE不存在,那么再次设置,第三次打开仍然不存在,这就非常有可能是爬虫在工作了。
反爬虫进进阶策略:
1.数据投毒,服务器在自己的页面上放置很多隐藏的url,这些url存在于html文件文件里面,但是通过css或者js使他们不会被显示在用户看到的页面上面。(确保用户点击不到)。那么,爬虫在爬取网页的时候,很用可能取访问这个url,服务器可以100%的认为这是爬虫干的,然后可以返回给他一些错误的数据,或者是拒绝响应。
爬虫进进阶策略:
1.各个网站虽然需要反爬虫,但是不能够把百度,谷歌这样的搜索引擎的爬虫给干了(干了的话,你的网站在百度都说搜不到!)。这样爬虫应该就可以冒充是百度的爬虫去爬。(但是ip也许可能被识破,因为你的ip并不是百度的ip)
反爬虫进进进阶策略:
给个验证码,让你输入以后才能登录,登录之后,才能访问。
爬虫进进进阶策略:
图像识别,机器学习,识别验证码。不过这个应该比较难,或者说成本比较高。
参考资料:
廖雪峰的python教程
静觅的python教程
requests库官方文档
segmentfault上面有一个人的关于知乎爬虫的博客,找不到链接了
")
如何使用python爬取知乎数据并做简单分析
一、使用的技术栈:
爬虫:python27 +requests+json+bs4+time
分析工具: ELK套件
开发工具:pycharm
数据成果简单的可视化分析
1.性别分布
0 绿色代表的是男性 ^ . ^
1 代表的是女性
-1 性别不确定
可见知乎的用户男性颇多。
二、粉丝最多的top30
粉丝最多的前三十名:依次是张佳玮、李开复、黄继新等等,去知乎上查这些人,也差不多这个排名,说明爬取的数据具有一定的说服力。
三、写文章最多的top30
四、爬虫架构
爬虫架构图如下:
说明:
选择一个活跃的用户(比如李开复)的url作为入口url.并将已爬取的url存在set中。
抓取内容,并解析该用户的关注的用户的列表url,添加这些url到另一个set中,并用已爬取的url作为过滤。
解析该用户的个人信息,并存取到本地磁盘。
logstash取实时的获取本地磁盘的用户数据,并给elsticsearchkibana和elasticsearch配合,将数据转换成用户友好的可视化图形。
五、编码
爬取一个url:
解析内容:
存本地文件:
代码说明:
* 需要修改获取requests请求头的authorization。
* 需要修改你的文件存储路径。
源码下载:点击这里,记得star哦!https : // github . com/forezp/ZhihuSpiderMan六、如何获取authorization
打开chorme,打开https : // www. zhihu .com/,
登陆,首页随便找个用户,进入他的个人主页,F12(或鼠标右键,点检查)七、可改进的地方
可增加线程池,提高爬虫效率
存储url的时候我才用的set(),并且采用缓存策略,最多只存2000个url,防止内存不够,其实可以存在redis中。
存储爬取后的用户我说采取的是本地文件的方式,更好的方式应该是存在mongodb中。
对爬取的用户应该有一个信息的过滤,比如用户的粉丝数需要大与100或者参与话题数大于10等才存储。防止抓取了过多的僵尸用户。
八、关于ELK套件
关于elk的套件安装就不讨论了,具体见官网就行了。网站:https : // www . elastic . co/另外logstash的配置文件如下:
从爬取的用户数据可分析的地方很多,比如地域、学历、年龄等等,我就不一一列举了。另外,我觉得爬虫是一件非常有意思的事情,在这个内容消费升级的年代,如何在广阔的互联网的数据海洋中挖掘有价值的数据,是一件值得思考和需不断践行的事情。








 京公网安备 11010802041100号
京公网安备 11010802041100号