离过年时间也不久了,还是预订春节火车票了,现在有好多平台都可以帮助大家抢购火车,下面小编给大家介绍用python抢过年的火车票附源码,对pthon抢火车票相关知识感兴趣的朋友一起学习吧
前言:大家跟我一起念,Python大法好,跟着本宝宝用Python抢火车票
首先我们需要splinter
安装:
pip install splinter -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
然后还需要一个浏览器的驱动,当然用chrome啦
下载地址:
http://chromedriver.storage.googleapis.com/index.html?path=2.20/
根据下载的自己的电脑系统选择下载包,我的windows就用win32了
解压后直接放到C:\Windows\System32目录下,你当然也可以给这个驱动程序弄个环境变量。
注意:我下的驱动版本是2.19的,根据自己需要下载相应版本,我的2.20版本有报错
首先简单的测试一下吧,推荐ipython代替python自带的交互界面
from splinter.browser import Browser
b = Browser(driver_name="chrome")
b.visit("http://www.baidu.com") ###注意不要去掉http://
然后牛刀小试一下吧,用百度搜索一些东西。比如splinter
在上面我们已经打开百度的网址了
然后我们输入一些像搜索的内容吧
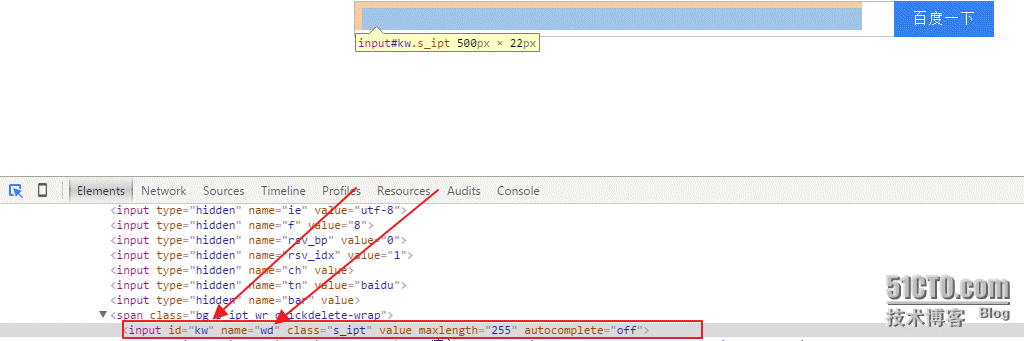
由上可以发现,该输入框的name=wd,通过fill似乎只能通过name填充
官方说明: Fill the field identified by ``name`` with the content specified by ``value``.
那就在输入框搜索splinter,当然也可以输入中文,但是最好指定Unicode编码,如u”我”
代码如下:
b.fill("wd","splinter")
有意思的事,你会发现你都不需要点击“百度一下”就到搜索页面了
但是,如果多次搜索,我们还是需要点击“百度一下”的
下面就不在带着大家找这些元素的id,value什么的了,通过chrome的F12找自己需要的吧
那么把点击栏find出来吧
我们发现,百度搜索栏的value=”百度一下”,id=”su”
所以把这个按钮提取出来
button = b.find_by_value(u"百度一下")
或者
button = b.find_by_id(u"su")
怎么点击呢?简单如下
代码如下:
button.click()
这有什么用?
我们找找页面里有没有我想找的东西吧,比如找找有没有这个地址“splinter.cobrateam.info”
b.is_text_present("splinter.cobrateam.info")
如果该页面存在,则返回True,反之亦然
怎么退出呢?
b.quit()
好吧,上面就是参照官方文档写的一个简单的入门教程了,下面我们进入正题吧~~~
个人是觉得授人以鱼不如授人以渔的,所以我尽量讲解所有的内容,而非发个代码,让大家copy一下,然后不求甚解。
值得注意的是,我不会去说什么怎么破解验证码以及有什么漏洞可以利用什么的,抢过票的都知道,快一点是一点,而我要做的是就能将机器能做的交给机器做,比如点击,查询,选择等,所以希望必中的还是绕过此文吧。笔者水平也就这么一点点。
首先我们用ipython讲解一下思路
开始当然是导入啦。。
from splinter.browser import Browser
b = Browser(driver_name="chrome")
url = “https://kyfw.12306.cn/otn/leftTicket/init”
b = Browser(driver_name="chrome")
b.visit(url)
第一步手动登陆,能通过下面的代码填充表单,但是我跳不过验证码,暂时没有精力去研究那东西,多多见谅,所以还是等手动选择验证码的。
b.find_by_text(u"登录").click()
b.fill("loginUserDTO.user_name","xxxx")
b.fill("userDTO.password","xxxx")
第二部选择出发地点日期等
通过COOKIEs选择出发地点,日期及目的地
首先瞧瞧我们的COOKIEs当然是没有的出发日期什么的
至于你的出发地点及目的地对于的COOKIEs值是什么,就得靠自己去copy了,我帮不了
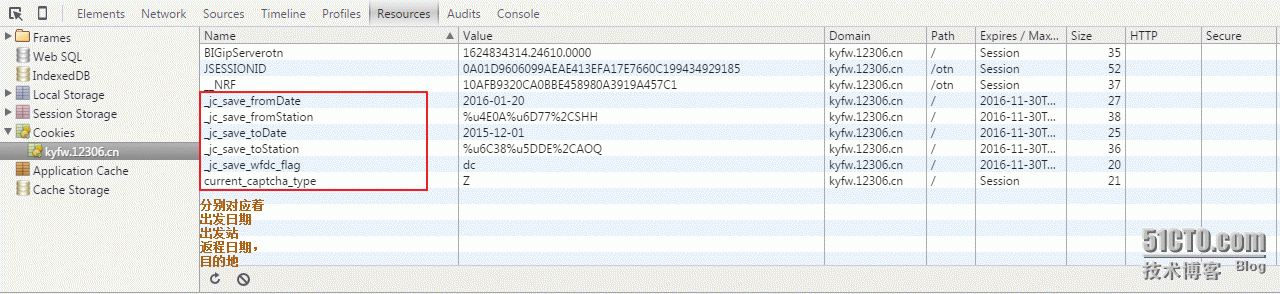
怎么有的这些值?
先将地点日期输进去查询一下,然后chrome按F12 找到这一部分即可
打开浏览器跳到这个页面当然是没有我们需要的信息的,比如下面这样
b.COOKIEs.all()
{u'BIGipServerotn': u'1977155850.38945.0000',
u'JSESSIONID': u'0A01D97598F459F751C4AE8518DBFB300DA7001B67',
u'__NRF': u'95D48FC2E0E15920BFB61C7A330FF2AE',
u'current_captcha_type': u'Z'}
然后我们需要添加出发地,这个得自己去查了,是简单的url加密
b.COOKIEs.add({"_jc_save_fromStation":"%u4E0A%u6D77%2CSHH"})
添加出发日期
b.COOKIEs.add({"_jc_save_fromDate":"2016-01-20"})
添加目的地
b.COOKIEs.add({u'_jc_save_toStation':'%u6C38%u5DDE%2CAOQ'})
注:如果是修改的话,还是调用add方法,如果传入的字典key值已存在则替换
比如,将目的地改为其他地方xxxx,如下即可
b.COOKIEs.add({u'_jc_save_toStation':'xxxxxx'})
然后在看看现在的COOKIEs值
b.COOKIEs.all()
{u'BIGipServerotn': u'1977155850.38945.0000',
u'JSESSIONID': u'0A01D97598F459F751C4AE8518DBFB300DA7001B67',
u'__NRF': u'95D48FC2E0E15920BFB61C7A330FF2AE',
u'_jc_save_fromDate': u'2016-01-20',
u'_jc_save_fromStation': u'%u4E0A%u6D77%2CSHH',
u'_jc_save_toStation': u'%u6C38%u5DDE%2CAOQ',
u'current_captcha_type': u'Z'}
既然COOKIEs已经准备完毕,reload一下,开始查询吧
b.reload()
b.find_by_text(u"查询").click()
是不是发现,地点日期都填上了,很酷有木有
到这一步我们得确认的是,自己已经登录了。一切准备就绪了,就可以刷票了。
值得说明的是,上面的步骤都能手工完成。
下面我们需要用组合BeautifulSoup来判断预订可不可以点,当然你也可以选择单点某一趟
反正我只想买高铁的,既然这样,下面两种方法,一是单点一趟,而是轮循着点很多趟,不放过任何机会。
先说第一个方法吧,这个比较简单,不需要用到其他库,单用splinter就够了,就先从简单的说起吧。
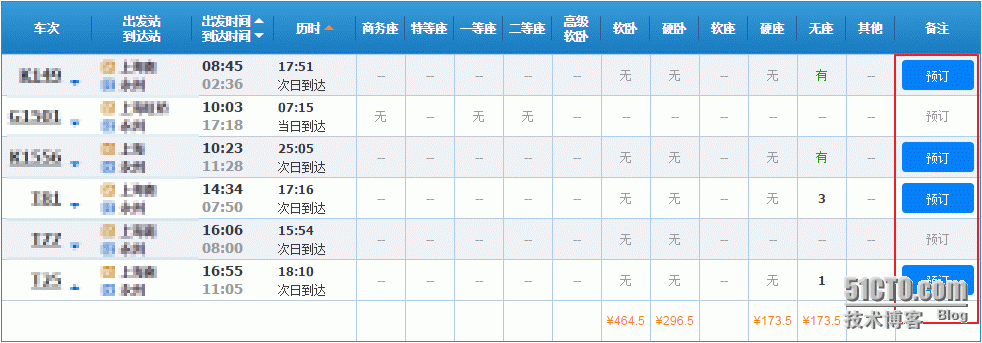
从我自己坐的火车线路来看,一共六趟,我只想做高铁,那么我一直点高铁的那一趟预订是不是就够了,当然是!!
一共六个预订,我的预订在第二个,索引值自然在1了啦。(会python的不会问我为什么的吧!!!)
b.find_by_text(u"预订")[1].click()
然后如果预订成功
应该跳转到选择乘客的位置,
我们就需要按需选择乘客了
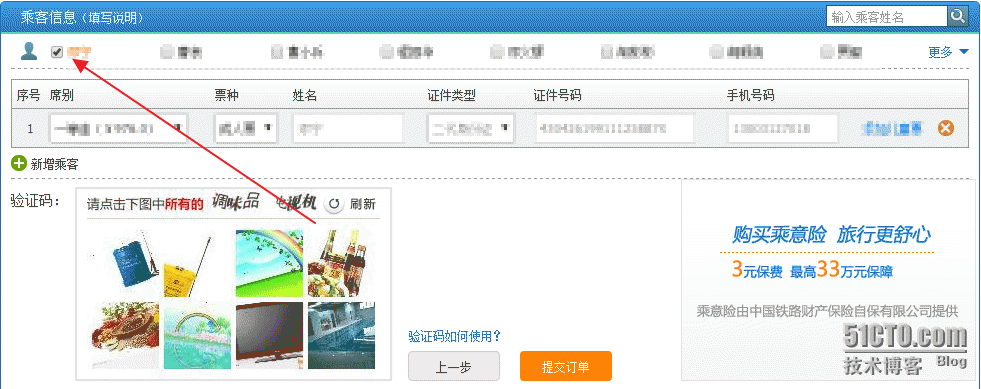
b.find_by_text(u"你的姓名")[1].click()
然后第一种方法基本讲解完毕。
上面的步骤摞在一起其实不过100行。
然后应该有第三种方法,就是利用默认的自动查询,默认是5秒刷新一次,但是大家都知道,春运期间5秒的区间太长了,怎么办呢?
Chrome的F12一下,点击Console
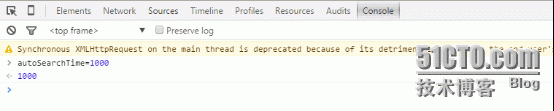
输入autoSearchTime=xxx
默认是毫秒为单位也就是说,默认5000ms,但是不要修改太小,会被侦测到然后报网络繁忙!!!我改成1000ms似乎只能刷十到十五次就报网络繁忙了。
其实,用Python刷票也是为了,没抢到,把刷新页面定向抢票的进程挂起,我们就不用时时刻刻去刷了,至于源码,留驱动都在下面的链接了~~代码还有很多不足,以及写的不够优雅,大家可以参考一下,根据实际情况随便修改~留下的邮箱应该都发完了,一个个发真的发不过来~~
需要源码的朋友可以点击下载了:http://pan.baidu.com/s/1gdTu7cR









 京公网安备 11010802041100号
京公网安备 11010802041100号