每天给你送来NLP技术干货!
来源:算法让生活更美好
前言

今天介绍一篇最新的NER预训练模型paper~
有关于在预训练模型上面训练命名实体识别(NER)有关的任务,这方面的研究还不多,注意不是NER fintune,是NER pretrain,主要的原因就是这面的数据集很少,即使有一个的数据集,但是其标注的质量也不高,为此本文主要贡献就是制作了一个比较大的且高质量的NER数据,进而在上面训练得到了一个NER的预训练模型NER-BERT ,实验证明好于BERT,感兴趣的小伙伴可以看看~~
NER-BERT :https://arxiv.org/pdf/2112.00405v1.pdf
Corpus Construction

这部分主要介绍怎么制作一个高质量的NER大数据集。主要从四个方面进行介绍(1)介绍一下当前已有的一些数据集的局限性或者说缺点。(2)实体类型的整合(3)低质量样本的过滤(4)不同实体类型之间样本数的balance。
下面我们一个一个看:
(1) Data sources for per-taining
想要得到一个大的NER数据集,容易想到的一个方法就是:整合当前已有的一些现成的NER数据集。但是这面临一些问题,首先这些现有的数据集通常都比较小,通常少于10K样本量,和训练bert的语料比起来基本不够看;再者这些数据集标注的schemes通常有一些gap,比如WNUT2017数据集中的corporation,group和其他大多数数据集中的organization就存在这个问题,想要统一这些schemes是比较困难的;最后这些数据集的实体类别通常也比较单一,比如基本上就是location,person,organization。对于预训练模型来说这些信息还不够丰富。
(2) Entity Categorization
这里主要用到的是DBpedia Ontology数据集,因为其包含着丰富的实体类型多达320多种,关于这个数据集更详细的信息可以看
Pablo Mendes, Max Jakob, and Christian Bizer. 2012. Dbpedia: A multilingual cross-domain knowledge base. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), pages 1813–1817.
具体做法是将Wikipedia 文章切分成句子,然后抽取anchor的连续单词,anchor可以理解为有超链接的部分。然后看其是否在DBpedia Ontology中,如果在那就正好进行标识,如果不在就给一个特殊标识比如“ENTITY”,注意这里只是对anchor进行匹配,而不是句子中的所有单词,因为有的单词可能偶然被匹配上了,但是却不是实体,另外连续单词是实体的可能性更高。
既然都是匹配DBpedia Ontology,那么就保证了标注的统一性。
(3)Data Filtering
为了进一步提高数据集的质量,这里使用了一些过滤逻辑,尽可能的过滤掉一些低质量的样本。
首先是过滤掉那些稀疏的实体类别,因为模型很难学习到这部分表征,相反其存在可能给模型的学习带来噪声。
其次是过滤掉那些只有“ENTITY”实体的句子,这部分的样本其实是非常多的,但是我们还是希望模型更能从包含确切实体类别的样本中学习知识。
最后是分配一个概率去过滤句子,具体来说就是
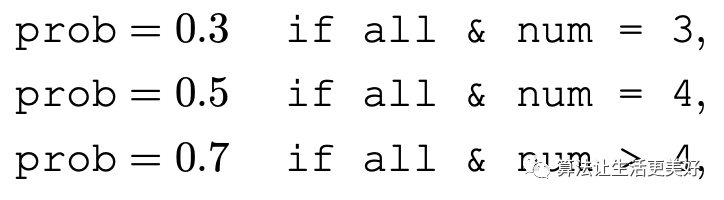
all代表句子出现的所有实体都是频次top20的实体。
num代表ENTITY实体的个数。
然后根据概率去过滤句子,可以看到num越大被过滤掉的机率越大。
(4)Data Balancing
各个实体类别间的数据量不平衡可能导致模型学习结果偏差,为此这里采用了boost进行抽样,抽样的概率正比于 , 是实体类别数量, 效果如下:
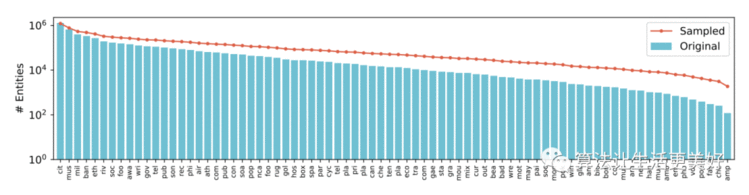
可以看到红线在一定程度上缓解了不平衡问题。
最后制作的数据集如下,这里截取了一部分实体类别,具体可以看附录B,一共315种。


NER-BERT

这部分主要介绍怎么利用上述语料预训练模型,以及怎么进行下游的finetun
(1)Pre-training
这里很简单就是直接使用用bert热启,然后任务是预测sequence labeling ,注意没有mask。说白了就是加一个entity tagging head即可。
当然了可以使用上述数据集预训练任何语言模型进行实验。
(2)Fine-tuning
类似之前的做法,替换掉预训练的entity tagging head,加一个当前目标域的head,进行fine-tune即可。
实验结果

(1)整体效果
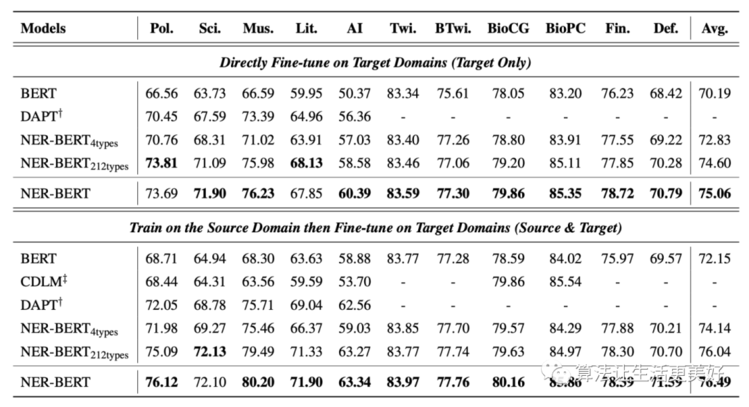
这里的CDLM,DAPT是另外两种baseline方法。 和 是为了对比丰富实体类别带来的收益,比如4types就是将原先的315种归纳出person、location、 organization和ENTITY四种,ENTITY可以看成是一个other类即不属于前三者的那些实体都归到这一类,同理212types是归纳出212类。
从上面可以看到细粒度的实体类别还是带来一些收益的,且NER-BERT方法都好于baseline。
(2)few-shot
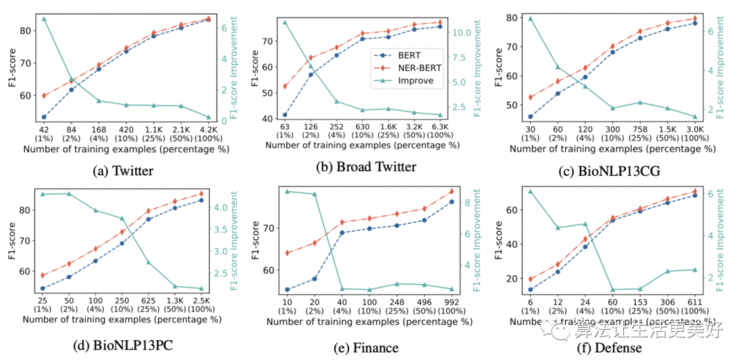
可以看到在小样本上NER-BERT都显著提高了performance。
(3)Visualization
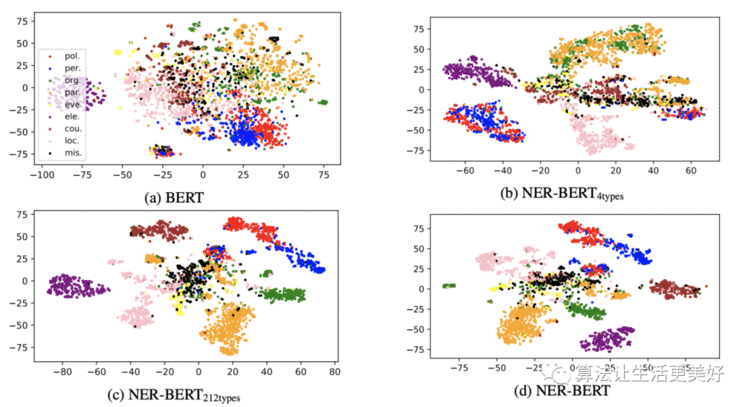
为了更好的证明模型学到了实体类别信息,作者将每个实体的第一个token的embedding抽取出来,然后使用tSNE映射到二维进行可视化,可以看到原始BERT基本是揉在了一起,没有明显的边界, 而 开始出现了一些边界,但是其还是不能很好的区分橘黄色的party和绿色的organization,因为其毕竟只在person、location、 organization和ENTITY四种上训练的,当然了 和 就表现的好多了。
关于各个领域比如音乐等等更详细的实验结果和可视化,大家感兴趣的话可以去看paper附录~
总结

(1)本篇的贡献就是一个数据集和一个预训练模型,都还没开源。
(2)要说收获,看完paper我们的收获可能就是:这里制作数据集最重要的trick其实还是要先有一个大字典,然后进行正则匹配,比如paper中利用的DBpedia Ontology数据集,那如果我们想在中文上面借鉴一下呢?是不是可以去找个类似的中文数据集。
(3)看到本篇不禁想到了ERNIE模型,ERNIE模型最最要的trick就是MASK实体,那其实其也是需要一个类似这样的数据集。
拼到最后拥有一个好的数据集才是王道~~
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!










 京公网安备 11010802041100号
京公网安备 11010802041100号