作者:Li-zHihuAn | 来源:互联网 | 2022-09-22 11:44
这篇文章主要介绍了Ubuntu中配置TensorFlow使用环境的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
一、TensorFlow简介
TensorFlow™是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。
二、安装Anaconda
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
获取Anaconda
在官网下载链接下载Python3.7版本的安装包
下载好以后的文件是Anaconda3-2020.02-Linux-x86_64.sh
开始安装
使用终端进入到保存Anaconda文件的目录下,使用下面命令开始安装
bash Anaconda3-2020.02-Linux-x86_64.sh
开始安装后会让咱们检查Anaconda License,若想跳过,则按Q跳过,之后会询问我们是否同意(Do you approve the license terms?),输入yes然后回车继续
接下来会询问咱们要把Anaconda安装到哪个路径,若有指定,输入路径并回车继续,若无指定,将会安装到默认目录家目录,回车继续。
等到下一个提示确定的时候,是问咱们要不要在~/.bashrc文件中加入环境变量,输入yes回车继续,等滚屏结束,咱们的Anaconda就安装完毕了。
三、TensorFlow的两个主要依赖包
Protocol Buffer
首先使用apt-get安装必要组件
$ sudo apt-get install autoconf automake libtool curl make g++ unzip
然后cd到合适的目录使用git clone功能获取安装文件
$ git clone
$ https://github.com/protocolbuffers/protobuf.git
$ cd protobuf
$ git submodule update --init --recursive
$ ./autogen.sh
开始安装
$ ./configure
$ make
$ make check
$ sudo make install
$ sudo ldconfig # refresh shared library cache.
在安装结束后,使用如下命令,看到版本号则安装成功
Bazel
安装准备
在安装Bazel之前,需要安装JDK8,具体安装方法请参考如下链接
jdk8安装方法
然后安装其他的依赖工具包
$ sudo apt-get install pkg-config zip g++ zlib1g-dev unzip
获取Bazel
在发布页面获取bazel-0.4.3-jdk7-installer-linux-x86_64.sh,
然后通过这个安装包安装Bazel
$ chmod +x bazel-0.4.3-jdk7-installer-linux-x86_64.sh
$ ./bazel-0.4.3-jdk7-installer-linux-x86_64.sh --user
安装完成后继续安装其他TensorFlow需要的依赖工具包
$ sudo apt-get install python3-numpy swig python3-dev python3-wheel
在完成后,在~/.bashrc中添加环境变量
export PATH"$PATH:$HOME/bin"
然后使用$ source ~/.bashrc激活
然后在终端输入bazel出现版本号的话,则安装成功。
四、安装CUDA和cuDNN
如果计算机上有安装NVIDIA的GPU并安装驱动的话,可以使用CUDA和cuDNN进行GPU运算
CUDA
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
获取并安装CUDA
在官网获取合适版本的CUDA Toolkit安装包

使用如下命令,安装cuda
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
$ sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb
$ sudo dpkg -i cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb
$ sudo apt-key add /var/cuda-repo-10-2-local-10.2.89-440.33.01/7fa2af80.pub
$ sudo apt-get update
$ sudo apt-get -y install cuda
测试CUDA
在安装完毕后要确认安装情况就进入例子目录进行编译
$ cd /usr/local/sample
$ make all
此时有可能编译出错,错误信息为提示找不到nvscibuf.h,就使用gedit工具打开Makefile文件,把第41行改为
FILTER_OUT := 0_Simple/cudaNvSci/Makefile
然后再次make all进行编译,编译成功后后会提示Finished building CUDA samples
这时候进入/usr/local/cuda/extras/demo_suite目录下,找到deviceQuery可执行文件,并执行,将会输出GPU相关信息。
这是博主的GPU信息
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1060 6GB"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 6075 MBytes (6370295808 bytes)
(10) Multiprocessors, (128) CUDA Cores/MP: 1280 CUDA Cores
GPU Max Clock rate: 1759 MHz (1.76 GHz)
Memory Clock rate: 4004 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1, Device0 = GeForce GTX 1060 6GB
Result = PASS
此时,CUDA安装完毕。
cuDNN(CUDA安装完成时才可用)
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如加州大学伯克利分校的流行caffe软件。简单的,插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是调整性能,同时还可以在GPU上实现高性能现代并行计算。
获取cuDNN
在官网链接注册完成并验证邮箱后,点击Download cuDNN下载
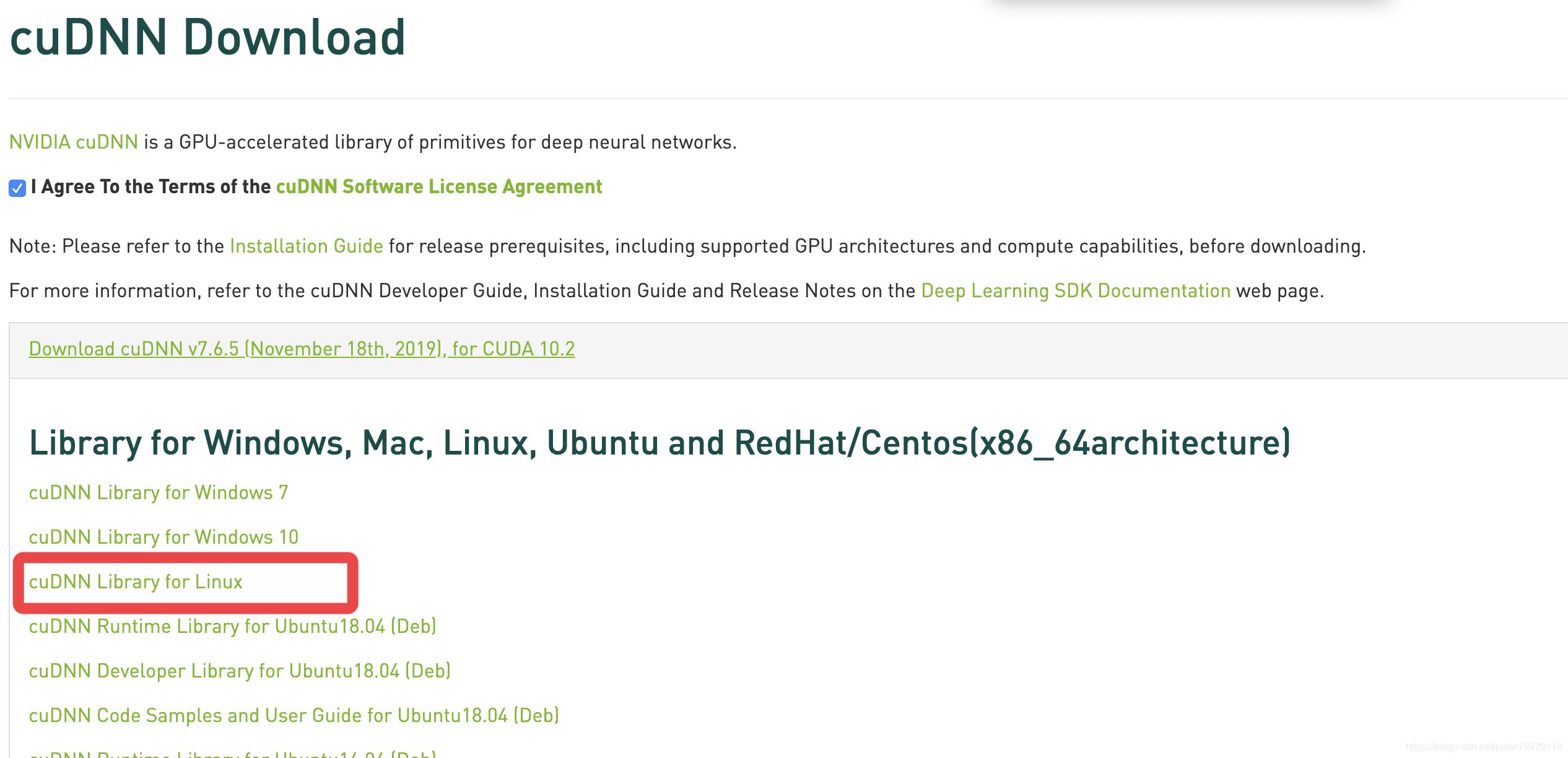
记得在同意前面打勾勾~
现在最新版本的是CUDA 10.2,cuDNN 7.6.5.32,得到的文件是cudnn-10.2-linux-x64-v7.6.5.32.tgz
下载完毕后,进入下载目录,使用如下命令进行解压
$ tar -zxvf cudnn-10.2-linux-x64-v7.6.5.32.tgz
会生成一个名为cuda的文件夹,进入该文件夹
然后使用复制操作完成安装
sudo cp lib64/libcudnn* /usr/local/cuda/lib64/
sudo cp include/cudnn.h /usr/local/cuda/include
操作完成后,进入cuDNN的目录更新库文件的软链接
$ cd /usr/local/cuda/lib64
$ sudo chmod +r libcudnn.so.7.6.5
$ sudo ln -s libcudnn.so.7.6.5 libcudnn.so.7
$ sudo ln -s libcudnn.so.7.6.5 libcudnn.so
$ sudo ldconfig
若软链接时报错,则把-s改成-sf即可
接下来在~/.bashrc中添加环境变量
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:usr/local/cuda-10.2/extras/CUPTI/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda-10.2
export PATH=/usr/local/cuda-10.2/bin:$PATH
至此,CUDA与cuDNN安装完成。
五、正式开始安装TensorFlow
在开始安装前,首先安装pip
$ sudo apt-get install python3-pip python3-dev
在完成后输入pip回车会输出相关命令
在pip安装完成后,输入如下命令开始安装最新的TensorFlow。
若无GPU,则安装CPU版本TensorFlow
$ pip install tensorflow-cpu
安装完成后,使用Python测试第一个TensorFlow程序
>>> import tensorflow as tf
>>> tf.add(1, 2).numpy()
3
>>> hello = tf.constant('Hello, TensorFlow!')
>>> hello.numpy()
b'Hello, TensorFlow!'
有生成上述结果时,TensorFlow安装成功。
至此,TensorFlow使用环境,安装完成。
到此这篇关于Ubuntu中配置TensorFlow使用环境的方法的文章就介绍到这了,更多相关Ubuntu配置TensorFlow内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号