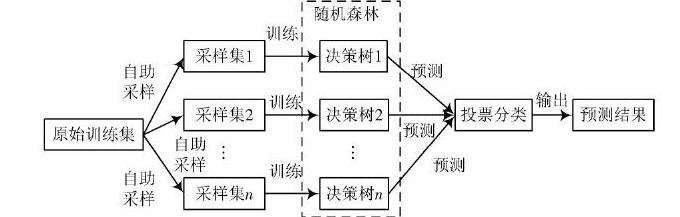
1.需求的提出
业务需求的提出,需要明确需求的价值,需求的背景和应用的场景以及需求方对于最后结果的大概期望。
2.数据集的构建
数据集的来源数据分为两种情况:其一、是预定义收集的数据,是指在产品的设计初期,即考虑到下游对数据的使用,所以对数据的收集的格式进行了一定的规范,比如图像的大小,识别目标的位置,识别目标的图像的占比等。其二、是未预定义收集的数据,即是产品设计初期,未考虑到数据的相关问题,造成收集的数据质量无法保证。
大部分要构建数据集的源数据一般都是未经预定义产生的,所以会产生数据非目标性干扰因素大,比如:要识别的目标占整体图像像素比不到十分之一,数据质量差等问题,比如:图像目标比较扭曲,这些都是模型误差的主要来源,另外,各分类类别数据不平衡也是导致模型过拟合的一个重大问题,所以图像识别任务,也包括其他数据挖掘的任务,都是需要在产品最初的设计时需要考虑的一个问题,这样就可以大大避免上述问题遗留到后面的任务当中,如果没有考虑到此一点,也可以在对模型应用后对数据的收集方式进行调整。
了解完数据的情况后,一般需要对数据进行人工标注,人工标注数据需要制定相关标注的统一标准,以尽量减少每个人理解不一致造成的误差,另外,标注的数据需要进行一定的抽样检查,以保证数据标注的质量。
3.数据输入和处理
数据的输入分为小数据量的数据和大数据量的数据两种情况,小数据量的数据直接全量读入内存就可以按一定batch进行模型的训练,大数据量的数据无法一次全量读入内存当中,需要采用生产者、消费者模式进行数据的读取和使用,在数据的输入过程当中,也是进行数据增强的时机,此时可通过数据增强,对不平衡的数据样本进行扩充,采用数据裁剪,数据反转等措施增加样本量,以提升模型的性能。
4.模型的选择
模型的选择建议遵循奥卡姆剃刀原则,即优先使用最简单的模型来解释数据,对于数据量小的数据,可优先选择迁移学习,更容易达到预期的效果。
5.模型的训练
模型的训练主要是对参数的选择和模型网络结构的调整,当然这些都是以对模型的评价的结果的评判来进行优化的,另一方面,模型的性能好坏也取决于数据增强的方法,所以数据增强的方法也是模型训练的时候进行调整的重要手段。
6.模型的评价
模型评价的方法比较多,可根据实际情况进行调整。
7.模型的压缩和导出
训练完成后的模型可能比较大,无法满足一些情况下的使用,可通过模型压缩的方法对模型进行压缩,参数固化,以及最后的模型导出。
8.模型的部署和应用
模型可通过容器化部署,以隔离和减少环境搭建部署造成的问题。
9.效果评价
模型部署后,模型产生的数据应当进行合理的规划和保存,根据模型产生的数据分析的结果对于数据的收集,数据的输入和处理以及模型的训练等进行优化和调整,是进行下一次迭代的主要依据。
致命问题:
业务线和数据部门之间割裂,各自为政,业务产品设计阶段未考虑数据部门的数据使用,造成数据部门数据质量下降,工作难以取得成效。另一方面,模型部署后业务线对数据结果未有任何反馈,造成模型效果难以提升。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有