刘云翔 陈斌 周子宜


摘 要: 肝癌是一种我国高发的消化系统恶性肿瘤,患者死亡率高,威胁极大。而其预后情况通常只能通过医生的专业知识和经验积累来粗略判断,准确率较差。因此文中在分析随机森林算法的基本原理的基础上,提出一种改进的基于随机森林的特征筛选算法,并应用Python编程设计了一个能够预处理数据、调用这些算法、控制各参数并展现测试结果的系统,最终将该系统应用于肝癌预后预测,比较分析了不同的算法、参数、内部策略对预测精度和计算性能的影响。研究结果表明,随机森林相比剪枝过的决策树具备更好的泛化能力和训练速度,改进的特征筛选算法能够在保证预测精度的前提下显著缩小特征集。
关键词: 随机森林算法; 特征筛选; 肝癌预后预测; 决策树; 预测精度; 特征集
中图分类号: TN911?34; TP3?05; TP312 文献标识码: A 文章编号: 1004?373X(2019)12?0117?05
Abstract: Liver cancer is a malignant tumor of the digestive system highly occurred in China, which causes high mortality of patients and great threat to their lives, and its prognosis conditions are often roughly judged by doctors with their professional knowledge and experience accumulation, which has poor accuracy. Therefore, on the basis of analyzing the basic principle of the random forest algorithm, an improved feature selection algorithm based on the random forest is proposed in this paper. The Python programming design is applied to design a system that can preprocess data, recall the algorithms, control various parameters and display test results. The system is applied to the prognosis prediction of the liver cancer. The influences of different algorithms, parameters and internal strategies on the prediction accuracy and computing performance are compared and analyzed. The research results show that in comparison with the pruned decision tree, the random forest has a better generalization ability and training speed, and the improved feature selection algorithm can significantly reduce the feature set on the premise of guaranteeing the prediction accuracy.
Keywords: random forest algorithm; feature selection; liver cancer prognosis prediction; decision tree; prediction accuracy; feature set
0 引 言
肝癌是一种我国高发的消化系统恶性肿瘤,患者死亡率在恶性肿瘤中高居第三,威胁极大。该疾病的预后情况通常只能通过医生的专业知识和经验积累来粗略判断,准确率较差,对医生和患者都造成了不利影响。目前国内外对该方面进行预测的系统性研究甚少,大多局限于某些具体指标对预后产生的意义,更没有相应的模型或软件。但是国内尚无成熟的原发性肝癌数据库,这可能和肝癌数据分散,难以大批量获得有关。目前国内将数据挖掘应用于肝癌预后预测研究主要的尝试有申羽等人运用朴素贝叶斯算法[1]和于长春等人应用改进的神经网络算法[2]对原发性肝癌预后预测进行应用研究。随着医学上的数据采集设备不断更新换代,基于大样本的数据挖掘技术将逐步在医学应用中崭露头角,显现出了重要的实用价值和广阔的发展前景。
本文将随机森林算法应用于原发性肝癌的数据分析,以期在临床上能够借助计算机进行预后预测,帮助选择治疗方案。此外,还改进并验证了一种基于随机森林的特征筛选算法,以降低模型训练的开销和数据采集的难度。本文采用Python语言实现了上述算法的各个细节,组织系统界面,最终进行大量的测试,详细分析不同参数和内部策略对性能、输出造成的影响,对模型选择提供了建议。
本文數据来自第二军医大学东方肝胆医院,共有588个病例和3个类别,在专业人员的帮助下去除了很多无关指标,每例剩余39个可用指标。
1 随机森林算法原理
随机森林是以决策树为基学习器的集成学习方法,它包含多棵随机产生的决策树并将它们的预测结合输出[3?4]。随机森林采取了Bagging思想和特征子空间思想,比单一决策树有更好的抗噪性,并且不易过拟合,可以显著提高泛化能力[3]。随机森林在Bagging思想的样本扰动基础上,又加入了属性扰动,即特征子空间思想:在各决策树的每个节点上选取最佳划分特征时,候选特征集都是从该节点的特征集中随机抽取的一个子集,而不再是该处的整个特征集。特征子集的大小k决定了随机程度,通常取[k=M]或[k=log2M+1],其中M是当前节点的特征总数。特别地,当[k=1]时,每个特征都是随机选取的;而当[k=M]时,建立的是普通决策树。
由于每棵决策树的训练集和节点上的特征子集都是独立抽取,所以它们的预测结果也是相互独立的。根据Bagging思想,随机森林在分类时用简单投票法取各决策树的多数预测结果。随机森林构造的是多棵“随机”的决策树,其中单棵的泛化能力通常低于在同样训练集上构造的普通决策树,然而在集成后整体的性能往往会好于只用Bagging方法建立的随机森林,因为各基学习器之间有更大的差异性,可得随机森林中每一棵“随机”决策树的构建算法如下:
初始化每个节点抽取的特征子集大小m
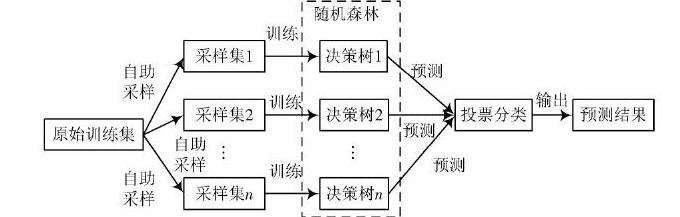
由于各决策树构建过程的随机性,随机森林被证明不会过拟合[4],故每棵树都尽可能地生长而不需要剪枝。与此同时,各分类器同质且相互独立,因此随机森林的建立可以方便地并行完成,速度较快。图1为随机森林的基本流程。
图1 随机森林的基本流程
2 基于袋外误差的特征选择
对于高维数据,一般要进行降维或特征选择,目的是降低模型学习的难度[5?8]。而冗余特征的存在使得特征选择更有必要性,去除这些不相关的特征不但能降低学习的开销,还能给数据采集提供便利。常见的特征选择方式有三类:过滤式、包裹式和嵌入式。过滤式方法在建立学习器之前就对数据集进行特征选择,再用筛选后的特征训练学习器;包裹式方法在候选特征子集上训练学习器,用学习器的性能来评价所选的特征集;而嵌入式方法在训练学习器的同时就能完成特征选择。本节中随机森林的特征选择算法是一种基于袋外误差的包裹式方法。
2.1 特征重要性
随机森林定义了特征的重要性度量,计算某特征X重要性的步骤如下:
1) 对于随机森林中的决策树[Ti],计算它在自己袋外数据上的分类错误数[Ei]。
2) 在该决策树的袋外数据中对X的取值进行随机扰动,重新计算其分类错误数[EXi]。
3) 令[i=1,2,…,n],重复以上两步,其中n是随机森林包含的决策树个数。
4) 特征X的重要性定义为:
这样定义的依据是:如果对某个特征加入噪声后模型的袋外误差显著提升,则说明该特征对预测结果的影响较大,从而有较高的重要性。
2.2 改进的特征选择算法
2010年Genuer R等人和2014年姚登举等人曾提出用随机森林进行特征选择的基本方法[5?6],本文在此基础上设计一种更加快捷的特征选择算法,根据各轮筛选造成的误差增量(相对筛选前)来判断是否要继续筛选,一旦它超过指定阈值就退出迭代,并将上一轮筛选所得的特征集作为结果。這样做的依据是,对于在不断缩减的特征集上训练出的模型,它们的泛化性能一般呈降低趋势,而其降低程度可以作为特征集的评价标准。该策略的实质是在给定误差范围内优先选择最小的特征子集,而不是测试精度最高的,从而能够尽早停止筛选,节省大量时间。不将误差增量阈值简单置为0的原因是,除了剔除不相关特征之外还希望去除一些弱相关特征,而且这样也能容许每次测试的微小偏差。试验结果表明,筛选后的特征集其实并不会产生像阈值那样大的误差增量,在其上的测试精度可以与筛选前持平甚至更高。
由于交叉验证的过程中会产生多个随机森林,故选择其中测试精度最高的一个来计算当前轮次的特征重要性顺序。计算特征重要性的流程图如图2所示。
图2 计算特征重要性的流程图
3 在肝癌数据上的应用和分析
3.1 数据概览和预处理
训练和测试数据为肝癌病例588例,由第二军医大学东方肝胆医院提供,在专业人士的帮助下去除了许多无关指标,并将所有记录数值化。每个病例剩余39个匿名指标,类标签有3种:
1) 恶性肿瘤,包含246例(41.8%);
2) 正常,包含193例(32.8%);
3) 良性病变,包含149例(25.3%)。
由于隐私保护、记录丢失等客观原因,样本集缺失值较多,共693处,缺失值超过5个的样本被程序自动丢弃,剩余519例。此外,每个样本包含6个离散型指标,下标分别为:0,16,17,18,19,20。
本文测试过程中的操作平台的配置为i7?3930k、16 GB内存,开发和测试环境为WIN7 64 bit、Anaconda 5.1.0,其中Python解释器版本3.6.5(64 bit),预处理数据结果如图3所示。
3.2 模型评估方法
由于是分类问题,故模型的损失函数为0?1损失,而模型的测试误差是其在测试集上的平均损失[9?11]。设模型f的输入是X,Y是对应X的真实值,测试样本容量为N,则损失函数L、测试误差e和测试精度r的形式化定义如下:
图3 读取的文件
模型的复杂度可以直接由代码段在同1台计算机上的运行时间衡量,也可以通过决策树的叶节点个数来比较。记录的运行时间由Python计时器获得[9]。



![详解 Python 的二元算术运算,为什么说减法只是语法糖?[Python常见问题]](https://img1.php1.cn/3cd4a/24cea/ae9/99a758096bea3e3d.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号