数据仓库(Data Warehouse)是一个面向主题的、集成的、稳定的且随时间变化的数据集合,用于 支持管理人员的决策
数据库:传统的关系型数据库主要应用在基本的事务处理,例如银行交易之类的场景 数据库支持增删改查这些常见的操作。
数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对数据库而言,数据仓库分析的数据规模要大得多。但是数据仓库只支持查询操作,不支持修改和删除
OLTP(Online transaction processing)::操作型处理,称为联机事务处理,也可以称为面向交易的 处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为 关心操作的响应时间、数据的安全性、完整性等问题
OLAP(Online analytical processing):分析型处理,称为联机分析处理,一般针对某些主题历史数 据进行分析,支持管理决策,OLAP侧重于分析
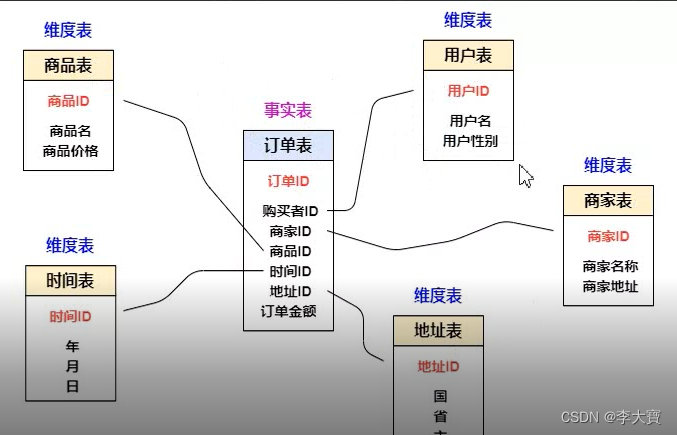
事实表是指保存了大量业务数据的表,或者说保存了一些真实的行为数据的表,例如:销售商品所产生的订单数据
维度其实指的就是一个对象的属性或者特征,例如:时间维度,地理区域维度,年龄维度,可以这样理解,其是事实表中的一个字段的值
第一范式(1NF):数据库表的每一列都是不可分割的原子数据项
如下的地址字段显然是不符合第一范式的,因为这里面的地址信息是可以拆分为省份+城市+街道 信息的
第二范式(2NF): 数据库表中每一列都和主键相关,不能只和主键的某一部分相关(针对联合主键而言) 也就是说一个表中只能保存一种类型的数据,不可以把多种类型数据保存在同一张表中
比如:这个表里面除了存储的有学生的班级信息,还有学生的考试成绩信息 根据我们刚才的分析,它是满足第一范式的,但是违背了第二范式,数据库表中的每一列并不是都和主键 相关 所以我们为了让这个表满足第二范式,可以这样拆分: 拆成两个表,一个表里面保存学生的班级信息,一个表里面保存学生的考试成绩信息
第三范式(3NF): 要求一个数据库表中不包含已在其它表中包含的非主键字段,就是说,表中的某些字段信息,如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键 join就用外键join)。
1、范式建模法(3nf):在关系型数据库中,大部分采用的是三范式建模法
2、维度建模法:以分析决策的需求出发构建模型,构建的模型为分析需求服务
分为 星型模型、雪花模型和星座模型
3、实体建模法:将任何一个业务过程划分为3部分:实体、事件、说明
星型模型:以事实表为中心,所有维度表直接连接在事实表上,像星星一样
1、维度表只和事实表关联,维度表之间没有关联
2、每个维度主键为单列,且该主键放置在事实表中,作为两边连接的外键
3、以事实表为中心,维表围绕核心呈星型分布
星型模型如下图
这里面的中间的订单表是事实表,外面的四个是维度表。
雪花模式的维度可以拥有其他维度表
雪花模型如下:
星座模型:基于多张事实表、而且共享维度信息
在实际工作中我们多采用星型模型,因为数据仓库主要是侧重于做数据分析,对数据的查询性能要求比较 高,所以星型模型是比较好的选择,在实际工工作中我们会尽可能的多构建一些宽表,提前把多种有关联 的维度整合到一张表中,后期使用时就不需要多表关联了,比较方便,并且性能也高。
数据仓库在构建过程中通常都需要进行分层处理。业务不同,分层的技术处理手段也不同。对数据进行分 层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控 详细来讲,主要有下面几个原因:
数据仓库一般会分为4层
1. 数据唯一性校验(通过数据采集工具采集的数据会存在重复的可能性)
2. 数据完整性校验(采集的数据中可能会出现缺失字段的情况,针对缺失字段的数据建议直接丢掉,如果可以确定是哪一列缺失也可以进行补全,可以用同一列上的前一个数据来填补或者同一列上的后一个数据来填补)
3. 数据合法性校验-1(针对数字列中出现了null、或者-之类的异常值,全部替换为一个特殊值,例如0或 者-1,这个需要根据具体的业务场景而定)
4. 数据合法性校验-2(针对部分字段需要校验数据的合法性,例如:用户的年龄,不能是负数)
拉链表专门为了解决在数据仓库中数据变化实现数据存储问题,顾名思义,所谓拉链,就是记录历史。记录 一个事物从开始,一直到当前状态的所有历史变化的信息。
1)内部表:默认情况下创建的表,hive拥有该表的结构和文件。当删除内部表的时候,它会删除数据及表的元数据 2) 外部表:要创建一个外部表,需要使用External语法关键字,当删除表定义的时候,表中的数据依然存在。 3) 分区表:分区可以理解为分类,通过分区把不同类型的数据放到不同目录,只需要在之前的创建表后面使用partition by加上分区字段就可以了 4) 分桶表:桶表是对数据进行哈希取值,然后放到不同文件中存储。查看每个桶文件中的内容,可以看出是通过对 buckets 取模确定的








 八、针对DWD层在对数据进行清洗的时候,一般需要遵循以下原则
八、针对DWD层在对数据进行清洗的时候,一般需要遵循以下原则










 京公网安备 11010802041100号
京公网安备 11010802041100号