首页
技术博客
PHP教程
数据库技术
前端开发
HTML5
Nginx
php论坛
新用户注册
|
会员登录
PHP教程
技术博客
编程问答
PNG素材
编程语言
前端技术
Android
PHP教程
HTML5教程
数据库
Linux技术
Nginx技术
PHP安全
WebSerer
职场攻略
JavaScript
开放平台
业界资讯
大话程序猿
登录
极速注册
取消
热门标签 | HotTags
深度
人脸识别
ocr
tensorflow
机器人
数据挖掘
人工智能
自然语言处理
图像识别
深度学习
pytorch
nlp
svm
算法
机器学习
自动驾驶
神经网络
当前位置:
开发笔记
>
人工智能
> 正文
【深度学习】常见的梯度下降的方法
作者:一根吃兔子的萝卜 | 来源:互联网 | 2023-05-25 09:32
批量梯度下降(Batch Gradient Descent,BGD) 这个方法是当所有的数据都经过了计算之后再整体除以它,即把所有样本的误差做
批量梯度下降(Batch Gradient Descent,BGD)
这个方法是当所有的数据都经过了计算之后再整体除以它,即把所有样本的误差做平均。这里我想提醒你,在实际的开发中,往往有百万甚至千万数量级的样本,那这个更新的量就很恐怖了。所以就需要另一个办法,随机梯度下降法。
随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法的特点是,每计算一个样本之后就要更新一次参数,这样参数更新的频率
就变高了。
想想看,每训练一条数据就更新一条参数,会有什么好处呢?对,有的时候,我们只需要
训练集中的一部分数据,就可以实现接近于使用全部数据训练的效果,训练速度也大大提
升。
然而,鱼和熊掌不可兼得,SGD 虽然快,也会存在一些问题。就比如,训练数据中肯定会
存在一些错误样本或者噪声数据,那么在一次用到该数据的迭代中,优化的方向肯定不是
朝着最理想的方向前进的,也就会导致训练效果(比如准确率)的下降。最极端的情况
下,就会导致模型无法得到全局最优,而是陷入到局部最优。
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
Mini-batch 的方法是目前主流使用最多的一种方式,它每次使用一个固定数量的数据进行
优化。
这个固定数量,我们称它为 batch size。batch size 较为常见的数量一般是 2 的 n 次方,
比如 32、128、512 等,越小的 batch size 对应的更新速度就越快,反之则越慢,但是更
新速度慢就不容易陷入局部最优。
基于随机梯度下降法,人们又提出了包括 momentum、nesterov momentum 等方法,这部分知识同学们有兴趣点击这里可以自行查阅。
梯度下降的min-batch越大越好么?
batch_size越大显存占用会越多,可能会造成内存溢出问题,此外由于一次读取太多的
样本,可能会造成迭代速度慢的问题。
batch_size较大容易使模型收敛在局部最优点
此外过大的batch_size的可能会导致模型泛化能力较差的问题
batch size太小的话,那么每个batch之间的差异就会很大,迭代的时候梯度震荡就会严重,不利
于收敛。
batch size越大,那么batch之间的差异越小,梯度震荡小,利于模型收敛。
但是凡事有个限度,如果batch size太大了,训练过程就会一直沿着一个方向走,从而陷入局部最
优。
深度学习
写下你的评论吧 !
吐个槽吧,看都看了
会员登录
|
用户注册
推荐阅读
神经网络
微软头条实习生分享深度学习自学指南
本文介绍了一位微软头条实习生自学深度学习的经验分享,包括学习资源推荐、重要基础知识的学习要点等。作者强调了学好Python和数学基础的重要性,并提供了一些建议。 ...
[详细]
蜡笔小新 2023-12-14 20:58:32
神经网络
2018年人工智能大数据的爆发,学Java还是Python?
本文介绍了2018年人工智能大数据的爆发以及学习Java和Python的相关知识。在人工智能和大数据时代,Java和Python这两门编程语言都很优秀且火爆。选择学习哪门语言要根据个人兴趣爱好来决定。Python是一门拥有简洁语法的高级编程语言,容易上手。其特色之一是强制使用空白符作为语句缩进,使得新手可以快速上手。目前,Python在人工智能领域有着广泛的应用。如果对Java、Python或大数据感兴趣,欢迎加入qq群458345782。 ...
[详细]
蜡笔小新 2023-12-14 20:08:28
神经网络
浏览器中的异常检测算法及其在深度学习中的应用
本文介绍了在浏览器中进行异常检测的算法,包括统计学方法和机器学习方法,并探讨了异常检测在深度学习中的应用。异常检测在金融领域的信用卡欺诈、企业安全领域的非法入侵、IT运维中的设备维护时间点预测等方面具有广泛的应用。通过使用TensorFlow.js进行异常检测,可以实现对单变量和多变量异常的检测。统计学方法通过估计数据的分布概率来计算数据点的异常概率,而机器学习方法则通过训练数据来建立异常检测模型。 ...
[详细]
蜡笔小新 2023-12-12 16:22:39
nlp
深度学习中的Vision Transformer (ViT)详解
本文详细介绍了深度学习中的Vision Transformer (ViT)方法。首先介绍了相关工作和ViT的基本原理,包括图像块嵌入、可学习的嵌入、位置嵌入和Transformer编码器等。接着讨论了ViT的张量维度变化、归纳偏置与混合架构、微调及更高分辨率等方面。最后给出了实验结果和相关代码的链接。本文的研究表明,对于CV任务,直接应用纯Transformer架构于图像块序列是可行的,无需依赖于卷积网络。 ...
[详细]
蜡笔小新 2023-12-12 15:26:38
神经网络
腾讯BERT推理模型TurboTransformers的快速推理能力
本文介绍了腾讯最近开源的BERT推理模型TurboTransformers,该模型在推理速度上比PyTorch快1~4倍。TurboTransformers采用了分层设计的思想,通过简化问题和加速开发,实现了快速推理能力。同时,文章还探讨了PyTorch在中间层延迟和深度神经网络中存在的问题,并提出了合并计算的解决方案。 ...
[详细]
蜡笔小新 2023-12-12 13:48:41
神经网络
Python张量流中的device spec make_merged_spec()方法使用说明
本文介绍了在Python张量流中使用make_merged_spec()方法合并设备规格对象的方法和语法,以及参数和返回值的说明,并提供了一个示例代码。 ...
[详细]
蜡笔小新 2023-12-11 12:15:19
神经网络
揭秘阿里云WAF背后神秘的AI智能防御体系
背景应用安全领域,各类攻击长久以来都危害着互联网上的应用,在web应用安全风险中,各类注入、跨站等攻击仍然占据着较前的位置。WAF(Web应用防火墙)正是为防御和阻断这类攻击而存在 ...
[详细]
蜡笔小新 2023-12-11 01:30:52
算法
Python实验报告文档中的文件和数据格式化操作
本文介绍了Python语言程序设计中文件和数据格式化的操作,包括使用np.savetext保存文本文件,对文本文件和二进制文件进行统一的操作步骤,以及使用Numpy模块进行数据可视化编程的指南。同时还提供了一些关于Python的测试题。 ...
[详细]
蜡笔小新 2023-12-10 17:02:16
pytorch
mapreduce数据去重的实现方法
本文介绍了利用mapreduce实现数据去重的方法,同时还介绍了人工智能AI领域中常用的框架和工具,包括Keras、PyTorch、MXNet、TensorFlow和PaddlePaddle,并提供了深度学习实战的代码下载链接。 ...
[详细]
蜡笔小新 2023-12-10 15:56:37
深度学习
GTX1070Ti显卡怎么样?GTX1070Ti显卡首发图赏+参数解读与拆解图
先来简单回顾一下今年的显卡市场,nvidia自从发布了帕斯卡架构新品之后,可以说是一直都主宰着高端游戏显卡市场,虽说amd也憋了一个hbm2的vega64出来,然而即使是最高贵的水 ...
[详细]
蜡笔小新 2023-12-10 14:36:15
神经网络
建立分类感知器二元模型对样本数据进行分类
本文介绍了建立分类感知器二元模型对样本数据进行分类的方法。通过建立线性模型,使用最小二乘、Logistic回归等方法进行建模,考虑到可能性的大小等因素。通过极大似然估计求得分类器的参数,使用牛顿-拉菲森迭代方法求解方程组。同时介绍了梯度上升算法和牛顿迭代的收敛速度比较。最后给出了公式法和logistic regression的实现示例。 ...
[详细]
蜡笔小新 2023-12-09 10:22:15
深度学习
Window10+anaconda+python3.5.4+ tensorflow1.5+ keras(GPU版本)安装教程
Window10+anaconda+python3.5.4+ tensorflow1.5+ keras(GPU版本)安装教程 ...
[详细]
蜡笔小新 2023-10-17 21:10:23
神经网络
aw多模态融合,多模态话语分析
本博文基于《Amalgamationofproteinsequence,structureandtextualinformationforimprovingprote ...
[详细]
蜡笔小新 2023-10-17 19:16:14
神经网络
【论文】ICLR 2020 九篇满分论文!!!
点击上方,选择星标或置顶,每天给你送干货!阅读大概需要11分钟跟随小博主,每天进步一丢丢来自:深度学习技术前沿 ...
[详细]
蜡笔小新 2023-10-17 18:45:53
神经网络
深度学习黑话
OCR:用字符识别方法将形状翻译成计算机文字的过程Matlab:商业数学软件;CUDA:CUDA™是一种由NVIDIA推 ...
[详细]
蜡笔小新 2023-10-17 17:55:01
一根吃兔子的萝卜
这个家伙很懒,什么也没留下!
Tags | 热门标签
深度
人脸识别
ocr
tensorflow
机器人
数据挖掘
人工智能
自然语言处理
图像识别
深度学习
pytorch
nlp
svm
算法
机器学习
自动驾驶
神经网络
RankList | 热门文章
1
被覆_#yyds干货盘点#Object.assign的使用
2
搬水果 在一个果园里,小明已经将所有的水果打了下来,并按水果的不同种类分成了若干堆,小明决定把所有的水果合成一堆。每一次合并,小明可以把两堆水果合并到一起,消耗的体力等于两堆水果的重量之和。当然经过
3
php实现文本数据导入SQLSERVER_PHP教程
4
【优化算法】粒子群优化算法简介
5
匿名对像,,,内部类
6
Unity游戏开发中的人工智能编程
7
Linux断点方法,Linux:断点原理与实现
8
C语言设置变量对齐方法
9
java poi 替换word内容
10
过路费【Floyd】
11
pvmove: it's safe to kill and restart pvmove while data migration goes
12
golang unicode转utf8
13
HDU 1159 最基础的dp LCS问题
14
显示一个div宽度100%带有边距 - Display a div width 100% with margins
15
ubuntu安装opencv,cmake出现以下代码错误,求解决
PHP1.CN | 中国最专业的PHP中文社区 |
DevBox开发工具箱
|
json解析格式化
|
PHP资讯
|
PHP教程
|
数据库技术
|
服务器技术
|
前端开发技术
|
PHP框架
|
开发工具
|
在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |
京公网安备 11010802041100号
|
京ICP备19059560号-4
| PHP1.CN 第一PHP社区 版权所有
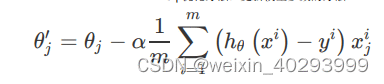








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 