作者:无与伦比的美丽MJ | 来源:互联网 | 2023-09-04 15:32
CVPR2018:RobustFacialLandmarkDetectionviaaFully-ConvolutionalLocal-GlobalContextNet
CVPR2018:Robust Facial Landmark Detection via a Fully-Convolutional Local-Global Context Network
https://blog.csdn.net/alfred_torres/article/details/83591985 https://blog.csdn.net/u013548568/article/details/80648439
目录 摘要 简介 Local-global context network Preprocessing Network Architecture Local-context subnet Kernel convolution Global-context subnet Loss From heatmaps to coordinates 实验
摘要 全卷积神经网络在提取局部特征上很棒,但是感受野受限制,对于全局特征表现不好。现在的一些方法通过引入级联网络、池化、或者一个数据驱动的模型来解决这个问题。
本文中,我们提出了一种新的方法,直接将全局语义特征引入到全卷积神经网络中。一个关键的概念是implicit核,这个卷积核可以将局部信息模糊化,然后通过一个dilate卷积加强成一个全局信息网络。卷积核对于网络的收敛很关键,因为他可以平滑梯度,减少过拟合。
在预处理阶段,拟合了一个基于PCA的2D模型,来对输出进行滤波。实验正面了方法的有效性。
简介 作者总结了全卷积神经网络的优点和缺点:优点:
不受限于图像分辨率。 不需要region of interest,不需要先进行face detect。 对于没有人脸或者多张人脸的情况,都可以处理。 对于剪裁、遮挡的人脸也可以处理。 参数量比有全连接层的少。 缺点:
因为感受野小,不能得到全局信息。 主要贡献
提出一个卷积神经网络使用的卷积核 利用dilated convolutions空洞卷积扩大感受野 在300-W和Menpo数据集上验证了方法的有效性 验证了本文提出的关键点定位方法不依赖于人脸检测先验信息 Local-global context network Preprocessing 首先将训练和测试图片crop到正方形,在rescale到96*96。作者将图片都转换为了灰度图,作者发现结果和RGB差不多,甚至有时候更好,这可能是因为三通道容易过拟合。
Network Architecture
local-context, fully-convolutional network convolution with a (customizable) static kernel Global-context, dilated fully-convolutional network Square error-like loss versus kernel-convolved labels Local-context subnet 该子网络作为局部特征提取器,提取一些底层的局部landmark特征,上述图片中,该子网络是一个15层的CNN,和一个1*1的linear convolution。
Kernel convolution Local-context subnet被kernel卷积。kernal卷积是一个group=1的group convolution,等同于channel-wise的convolution。他在训练和测试的时候都会被用到。
像素之间的平方差现在关联了预测和ground truth之间的距离 global-context子网络可以利用dilated,而不是dense convolution Global-context subnet 该全局子网络的目的是整合local子网络的信息。作者使用了dilated卷积来增大感受野。
Loss 对N个landmark点的每一个都设置了一个权重,根据是否标注以及是否在界内外。n l 表示local的第n个通道,On g 表示local的第n个通道,,K是kernel,Gn 是gt map
From heatmaps to coordinates 从热度图到最终的坐标,一般来讲会直接取最大值,但是这种每张map最大值的情形仅仅适用于关键点比较少的情况(疑问脸),然后如果事先确定一个阈值,仅仅在阈值以上的情形是要求取最大,这种情形又是会引进outliers。作者设计了一个2D-PCA based的模型
实验

















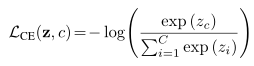


 京公网安备 11010802041100号
京公网安备 11010802041100号