点击左上方蓝字关注我们

本文由小米公司算法工程师吕荣荣、王鹏程投稿,该团队目前在千言&百度飞桨实体链指常规赛leaderboard中排名第一。
大数据时代,信息爆炸性增长,直接导致了信息过载。那么在无用的信息之中找到有用的信息,就少不了智能的信息理技术帮忙。比如,作为人工智能领域处理大规模文本数据的核心技术的自然语言处理(NLP),它在信息检索、智能问答、智能推荐等众多领域扮演着重要的角色,实体链指(Entity Linking,EL)则是其中最热门的研究课题之一。本次百度举办的“千言数据集:面向中文短文本的实体链指任务”,数据来源于真实的搜索 query、微博、对话内容、文章/视频/图片的标题等,旨在将实体链指技术实践于更多的现实场景。
赛题背景
我们都知道,自然语言具有多样性和歧义性,这使得机器在理解文本的时候更加困难。人与人之间表达的差异性和选择性使得同一意义可以有多种不同表达方法进行表达,比如“李白”、“李太白”、“青莲居士”都可以指大诗人李白,这就是语言的多样性。同一个词语、词组、句子在不同的上下文中有多种不同的意义,比如“李白:结婚当天,他就回到了岗位上... ...”、“王者荣耀25号李白和兰陵王皮肤迎来优化,有公孙离祁雪灵祝的玩家血赚”、“诗仙李白传奇十三(年少辉煌,帝王之梦)”这三条资讯中的“李白”分别对应了三个不同的实体。针对自然语言表达的多样性与歧义性问题,实体链指技术提供了如下的解决方案:通过将自然语言中的文本和知识库中的实体进行链接,从而帮助机器消除歧义,更好的理解。
实体链指任务大致可以分两大类:
End-to-End :先从text中提取mention,在KB中对应到候选实体构成entities,然后对entities中的entity进行消歧,最终映射到正确的entity上;
Linking-only 直接将text和mention作为输入,后续处理和类1相同。其中,text表示输入的文本;mention表示实体指称,自然文本中表达实体的语言片段;KB表示知识库,由三元组构成;entity表示实体,知识库的基本单元;entities表示候选实体集,由知识库中与实体指称有所关联的实体组成。
在该比赛中,输入是中文短文本以及该短文本中的实体指称集合,要求输出中文短文本的实体链指结果。每个结果包含:实体mention、在中文短文本中的位置偏移、其在给定知识库中的id,如果为NIL情况,需要再给出实体的上位概念类型。所以,我们可以判断这是一个Linking-only类的实体链指问题,专注于中文短文本场景下的多歧义实体消歧技术。另外,需要对新实体(NIL实体)的上位概念类型判断,这就还需要处理不可链接实体预测问题(Unlinkable Mention Prediction)和实体类别预测问题。不过,我们都知道,无论如何是不可能建立一个能穷举万物的KB,所以现实场景下,必定会存在不可链接实体预测问题。对不可链接实体预测问题,也比较贴合现实环境下的业务场景。
数据分析
本次比赛的知识库来自百度百科知识库。知识库中,平均每个实体包含6.8个二元组。实体样例如图1所示:

图1 知识库中实体样例
除了知识库外,还提供了标注样本集,数据均通过百度众包标注生成。标注数据集中每条数据的格式如图2所示:

图2 标注数据样本格式
数据集中包括训练数据7万条,验证数据1万条,A榜的测试数据1万条,B榜的测试数据2.5万条。训练数据中包含mention共26万个,也就是每条训练样本中,待消歧的mention约3个左右。其中,链接到KB中的实体的mention有23万个,占比88.7%,链接到NIL实体的mention有3万个,占比11.3%。验证数据中包含mention共3万个,每条样本待消歧的mention也是约3个左右。其中,链接到KB中的实体的mention有2.6万个,占比80.44%,链接到NIL实体的mention有0.6万个,占比19.56%。因此,要在该比赛中取得更好的成绩,除了做好KB中实体消歧的任务,针对NIL实体的判断及其类型的预测的任务也至关重要。
对于标注数据中的mention,我们统计了每个mention在KB中通过“alias”字段关联到的候选实体个数。这里统计了一下训练数据集中每个mention的同名实体个数占比情况,可以发现每个mention都存在大量的候选实体,即存在大量的一词多义现象。比如在KB中别名为“李白”的实体就有29个。统计数据如图3所示,一词多义的情况占比达74.07%,超过10个同名实体的占比达18.98%,这其中还不包括大量链接到NIL实体的mention。

图3 候选实体个数分布图
对于标注数据中mention链接到的实体的类别,我们统计了其在24个类别上的分布情况。由图4可以看出,训练数据和验证数据中,全量实体的类别分布大致相同,但是NIL实体的类别分布和全量实体的却相差较大。这一点在后续做实体分类的时候,需要特别注意,因为任务是要求给出NIL实体的类别。

图4 标注数据中mention的类别分布
模型思路介绍
由前面的赛题背景和数据分析,我们可以大致确定解决该任务的方法。首先利用候选实体生成技术为每个实体指称生成对应候选实体集,然后利用文本上下文信息和知识库的信息找到与实体指称相匹配的实体,如果没有找到相匹配的实体,则将该实体指称标记为 NIL实体(代表知识库中没有对应实体),并预测其类型。所以该比赛可以拆分成三个子任务:实体分类、候选实体获取、实体消歧。整体框架图如图5所示:

图5 实体链指模块框架图
实体分类
实体分类,指在给定上位概念类型体系的基础上,预测mention在text中的上位概念类型。实体分类模块的实现主要基于多种预训练模型进行微调。我们利用标记符标记出mention再text中的位置,经过 BERT 编码,取[CLS]的向量,经过全连接层,最后 softmax 激活得到指称项的类别概率分布。模型结构如图6所示:

图6 基于BERT的实体分类模型图
本次比赛我们直接使用的PaddleHub中的文本分类模型,代码如下:

由上文中的数据分析可知,训练集合中mention关联到KB中的实体的类别与关联到NIL实体的类别分布不同,直接与NIL部分的数据一起训练会导致模型整体预测NIL实体类别的准确率下降,而直接用NIL部分的数据训练则有些训练数据较少的类会训练的不充分。所以我们采用二次训练的方法,第一次的时候使用了训练集中非NIL的部分,训练两个epoch,然后再在这个基础上去训练关联到NIL实体的样本数据。
最后对基于多个预训练模型训练出来的模型进行融合。模型融合的方法是使用多折的方法训练了一个基于MLP的分类模型。
候选实体获取
候选实体获取是对于文本中的每个mention,过滤掉知识库中的不相关实体并检索所有可能的实体,组成候选实体集。该任务中,经过回测,通过知识库的alias字段,基于名称字典的技术在给定的标注数据集中,除了NIL实体外,正确关联实体可以全部召回。
比赛中对新实体(NIL 实体)的上位概念类型判断的要求,就是不可链接实体预测问题。处理不可链接实体预测问题的常用方法有:
NIL Threshold:通过一个置信度的阈值来判断;
Binary Classification:训练一个二分类的模型,判断top1 entity是否真的是文中的mention想要表达的实体;
Rank with NIL:在rank的时候,在候选实体中加入NIL entity,构成完备侯选实体集,再排序选择top1 Entity。
本设计方案采用第三种方法,将NIL实体加入候选实体集,构成完备候选实体集。这样组成的完备候选实体集中,必有一个正确的实体和文本中的指称项关联。训练时,指称项的类别来自标注文本中kb_id对应的实体类型,预测时,指称项的类别由实体分类模块预测得到。完备候选实体集公式如下:

其中表示完备候选实体集,表示利用alias从KB中检索的候选实体集,表示实体分类预测结果构成的NIL_Type实体。
实体消歧
候选实体消歧主要任务是对于给定的文本及其实体指称,判断候选实体获取技术得到的候选实体集中真正对应的那个实体。
首先,知识库中每个实体的对应着多个“属性-属性值”对,我们需要将所有的“属性-属性值”都拼成一个字符串,当作该实体的完整描述了。由于 type 字段,义项描述和摘要字段的信息更重要,描述文本中都按照 type、义项描述、摘要和 data 中其他 predicate、object 对的顺序进行拼接。如下图生成的实体描述为:

然后,需要将实体指称的首位位置标记出来,方便模型判断是文本中的指称项和实体进行匹配。这里直接利用两个标记符,将实体指称的位置标记出来。
最后,考虑到BERT模型在特征学习上的强大表现,我们采用了基于BERT的中文语义匹配模型作为实体消歧模型。模型将处理过的文本作为text_a,处理过的实体描述文本作为text_b,预测句子对的匹配度。其中正样本中的text_b是标注数据中的实体描述文本,负样本的text_b为动态负采样得到的实体描述文本。
这里动态负采样是一种采样策略。由上面的数据分析部分可知,文本存在大量歧义性,每个实体指称都关联着大量的候选实体,而其中正确的候选实体只有一个。如果正确关联的实体作为正样本,其余实体作为负样本,那么该任务就是一个不均衡二分类问题,正负样本比例不均衡。动态负采样包括每次训练时使用的负样本随机采样和每次用比较难的负样本。这里我选择每次采样比较难的负样本,以此来提升模型的学习效率和模型泛化性。就像小时候做数学题一样,为模型整理一个错题集,来高效的学习那些比较难的样本。理论上,正样本的关联概率要高于负样本。所以,我们预测每一个候选实体的关联概率,然后进行排序,排序靠前的候选实体,正确的继续作为正样本,而预测关联概率高但是并不是关联实体的实体作为负样本。这样不断的学习、预测、动态采样负样本继续学习,提升模型的学习效率和学习能力,从而提升模型的效果。这里初始化采样时,是根据侯选实体的实体知名度进行排序,采样top N个实体作为负样本的。
这里实体消歧模块的实现也是基于多种预训练模型进行微调,模型结构如图7所示:

图7 基于BERT的实体消歧模型图
基于动态负采样的训练代码如下:

实体消歧不仅要考虑 text 的文本信息、KB 的信息、消歧后的一致性,还需要根据具体的业务场景采用不同的方案,需要灵活的运用linkCount,attributes,context,coherence这四大特征。linkCount指上文提到的“实体知名度”,mention指向候选实体的关联概率。attribute指“实体属性”,实体的流行度、类型及其他属性。context指“上下文”,mention的上下文信息。coherence 指“实体一致性”,mention和其上下文中其他的mention的一致性。结合任务,我们设计了多种特征因子来进行实体消歧。
实体知名度是一个上下文无关特征的统计数值。这里我们基于给定的标注数据进行了统计,表示标注数据中指称项映射到实体的关联概率,公式如下:

实体共现,是上下文有关特征的统计数值。这里我们基于给定的标注数据进行了统计,给出了两种计算方式,公式如下:

表示文本中其他指称项出现在侯选实体描述文本中的关联概率。

表示标注数据中其他指称项出现时指称项和侯选实体的关联概率。
实体类别,文本中实体指称项的类别应和其关联的实体类别相同,是上下文有关特征的特征。这里我们通过候选实体的类型在预测的实体类别中的分布概率,作为该特征值。候选实体的类型映射到指称项类别的预测概率的公司如下:

实体特性,候选实体是否为NIL实体,是上下文独立特征,实体自带属性。公式如下:

其中,c是上下文, 是候选实体,m是实体指称项,是文本中其他实体指称项,是候选实体的类型,是预测的实体指称项的类别,n是候选实体集的个数,E是所有候选实体的集合。
特征因子融合的方法是使用多折的方法训练一个 MLP 的模型。具体的特征如图8:

图8 实体消歧的特征因子列表
实验结果
中文短文本的实体链指比赛,限定在给定的标注数据和知识库中。标注数据均通过百度众包标注生成,准确率95%以上。
指称项分类模型训练中使用二次训练的方法F1提升了约1%,模型融合后在dev数据上F1值达到了89.55%。具体参数和验证数据集下的结果如图9所示:

图9 验证数据的实体分类结果
使用多折的方法训练了一个MLP的模型对这些特征因子进行融合,融合后在dev数据上F1值达到了89.26%。具体参数和验证数据集下的结果如图10所示:

图10 验证数据的实体链指结果
对验证集的数据简单进行分析,模型消歧的错误主要有四类:
fp_nil_ni:标注数据为NIL_TYPE,预测也为NIL_TYPE,但是类别预测错误。
fp_nil_id:标注数据为NIL_TYPE,被错误预测为KB中的实体。
fp_id_id:标注数据为KB中的实体,预测也为KB中的实体,但实体ID预测错误。
fp_id_nil:标注数据为KB中的实体,被错误预测为NIL_TYPE。
不同模型下,错误分布如图11所示。我们对比单个模型预测结果最好的ERNIE和模型融合后的结果进行对比:

图11 不同模型的错误分布
可以看出,相比单个模型的实体链指结果,模型融合后,标注数据为KB中的实体,被错误预测为NIL_TYPE的错误(fp_id_nil)得到明显的改进,说明了多特征因子融合的有效性。
总结与讨论
本文对实体链指任务做了一些探索。利用实体指称类型预测,构建NIL_type实体,解决无链接指代预测问题,同时利用BERT、动态负采样、特征融合等训练方法极大地提高了实体消歧的准确率。
在实验时,我们也对比了用标记符突出mention的方式和将mention起始和结束位置向量融合到cls的方式,在基于BERT的实体分类和实体消歧的微调任务上,效果均没有什么区别。再次感慨BERT模型的强大特征抽取能力。
还有很多待优化的点,比如当前方法没有充分利用其它指称项的侯选实体信息,对其他指称项信息的利用仅仅停留在名称层面。另外,可以利用一些特征,如:实体类别、实体知名度等,先对候选实体进行一次排序,选择排序topN的候选实体进行下一步的消歧,这样分层消歧在候选实体过多的情况下不仅可以提高准确率,还能提高消歧效率。
本次比赛的所有代码均基于飞桨的PaddleHub包开发,可以方便的使用大规模预训练模型快速完成迁移学习。百度AI Studio是针对AI学习者的在线一体化学习与实训社区,提供了大量的数据集、使用教程、项目分享文章等,感兴趣的可以学习。
除PaddleHub外,飞桨还有专用于NLP领域的library-PaddleNLP。PaddleNLP集成了NLP领域主流预训练训练模型和众多场景,内置了丰富的数据集。
PaddleNLP GitHub传送门:
https://github.com/PaddlePaddle/PaddleNLP
最后,该参赛系统实际上是从小米手机和AIoT设备上的SLU(Spoken Language Understanding)中实体链接技术方案改造而来的,需要感谢小米AI实验室-知识图谱部门给我们提供的历练平台,也要感谢主办方给我们提供的竞赛机会,让我们技术方法可以在公开的千言数据集上得到验证。
除了实体链指任务,千言项目还有情感分析、阅读理解、开放域对话、文本相似度、语义解析、机器同传、信息抽取等方向持续打榜中。
千言官网传送门:
https://www.luge.ai/
参考文献
[1]Shen W, Wang J, Han J. Entity linking with a knowledge base: Issues, techniques, and solutions[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 27(2): 443-460.
[2]Ganea O E, Hofmann T. Deep joint entity disambiguation with local neural attention[J]. arXiv preprint arXiv:1704.04920, 2017.
[3]Le P, Titov I. Improving entity linking by modeling latent relations between mentions[J]. arXiv preprint arXiv:1804.10637, 2018.
[4]Raiman J, Raiman O. Deeptype: multilingual entity linking by neural type system evolution[J]. arXiv preprint arXiv:1802.01021, 2018.
[5]Sil A, Kundu G, Florian R, et al. Neural cross-lingual entity linking[J]. arXiv preprint arXiv:1712.01813, 2017.
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END



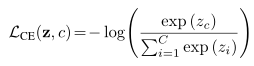






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有