作者:AIHFKYH_986 | 来源:互联网 | 2023-09-12 19:46
文章虽短,但都是干货。来和大家聊一个很重要,也是企业现在普遍的痛点:业务部门会抱怨报表数据不够及时和准确,IT部门则会抱怨业务部门需求太多太急,这种矛盾在大部分企业都会存在,这些问
文章虽短,但都是干货。
来和大家聊一个很重要,也是企业现在普遍的痛点:
业务部门会抱怨报表数据不够及时和准确,IT部门则会抱怨业务部门需求太多太急,这种矛盾在大部分企业都会存在,这些问题的解决不是仅靠资源的投入、技术的提升能解决的,往往涉及到企业组织、机制和流程等更深层次的问题。

那如何提升做报表的效率?我从4个方面提出了建议。
1、组织优化:在业务部门建立小IT团队
业务部门提报表需求,IT部门实现报表需求的“授人以鱼”的传统支撑模式速度是很难起来的,因为管理成本太高(比如需求分析、流程审批、资源分配、运维调度等等),如果业务部门能自己进行报表开发,则可以从根本上解决问题。
业务部门不可能成为IT部门,但业务部门却可以拥有自己的小IT团队,从而自给自足的解决报表开发问题,这个在数据中台建立起来后变得非常现实。
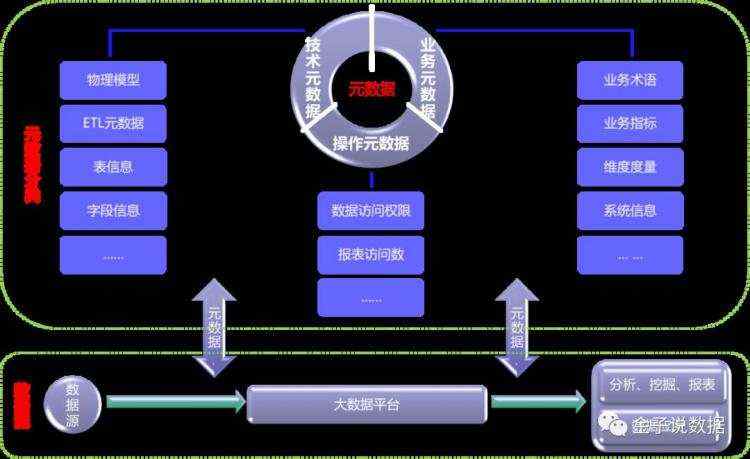
数据中台可以为业务部门的小IT团队提供三种能力:数据仓库模型、开发工具和BI工具。其中数据仓库模型解决报表数据生成效率问题,数据开发工具解决业务人员操控数据的问题,BI工具解决业务人员设计和发布报表的问题。
中台确保了业务部门的小IT既不会导致IT系统的重复建设问题,也能给予业务部门足够的自由度和自主权。
现实中最大的挑战其实不在技术上,而是在观念上,让业务人员自力更生并不是那么容易,即使你提供了很好的平台或工具,但的确“在业务部门建立小IT”是很好的方法。
正如现在的HRBP一样,ITBP也该出现了

FineReport做的报表
2、业务归口:实现报表的集中管理
报表的口径混乱导致业务部门花费巨大的精力去核对数据,IT部门为了配合数据核对也需要投入巨大的成本,这是企业报表支撑效率低下的一个原因,我们不是在做报表的路上,就是在核对报表的路上。
报表口径混乱的根源当然不是IT问题,而是业务问题。公司的某个业务也许可以归口到某个部门管理,但并不代表这个业务的报表有了归口部门管理,任何跟这个业务相关的组织或个人都是有权利向IT部门提出该业务的报表需求的,这是成千上万报表产生的一个原因,也是口径混乱的根源。
比如集团总部要看省公司维度的的报表,而省公司要看地市公司维度,虽然大家关注的是同一个业务,但你会发现IT不得重复去实现一遍。
但只要有重复实现就会产生不一致问题,因为不同的组织或个人对于同一事务的理解肯定有偏差,特别是业务口径,一字之差,谬以千里,即使业务口径一致,实现方式的不同也会导致不一致。
企业与其花费巨大的精力去核对报表,还不如针对每个业务的报表去明确下归口管理部门,跟IT部门做个协同,比如不允许IT部门接收非归口管理部门的报表需求,在这个前提下IT部门去开展报表治理的工作才有些意义,否则垃圾还在不停的进来,怎么治?

现实中IT往往成了背锅侠,这是挺扯淡的事情,只能说IT在很多企业太弱势了,业务部门从来就不曾真正的解决问题,它永远是要求当下IT必须给我正确的数据,至于如何才能从根本上解决问题,下次再说吧。
3、指标统一:实现报表的中台能力
有了报表的业务归口的前提,才轮得上去谈技术的解决方案。有人总是强调指标的神奇作用,但如果没有业务管理上的支持,说用指标的方式来提升报表的开发效率也是美丽的泡沫,长远来讲难以坚持。
从纯技术的角度讲,报表都是由指标组成,只要指标能够标准化,理论上任何新增报表都可以由标准化的指标组装生成,这是典型的中台化的思想。可惜的是,指标不是功能,其牵涉的维度和粒度太多,变化太快,基于指标搭建的这个报表中台就有点脆弱。

报表的中台化实现方案可以参考阿里的的数据中台,其对于指标的实现有严格的控制,但前提是需要公司顶层的支持,因为整个数据的支撑模式将发生巨大的变化,开始的时候成本是巨大的,而未来则是不确定的。
比如当业务人员提一张报表需求的时候,IT会先评估下是否有现成的指标可以支撑,如果没有,则要先实现这些指标,而为了确保这些指标的共享性,指标的设计和实现过程将花费更多的时间和精力。
但企业有多大的耐心呢?
在市场响应的及时性和IT的可复用性之间,你觉得它会做出何种选择?因此笔者看到了太多指标化神坛的垮掉。
无论如何,指标化是提升报表效率的利器,如果你能坚持到最后,那一定是很好的,但千万要获得企业的支持,这不是IT部门能自己搞定的事情,更不能两边骑墙。

4、人才引入:拓展做报表的边界
再好的组织、机制、技术的设计,如果没有优秀的人去落地实施,一切就都成了空。要提升报表效率的最简单方法就找靠谱的人去做。
比如报表数据稽核吧,专家和新人的效率就不可同日而语,在最危急的时候,leader总是想到团队最靠谱的人来搞定数据质量问题。
因此,要提升做报表的效率,你首先得看看最优秀的人是否被安放在了这个岗位上,牛逼的表哥做报表能做出不同的境界。
他不仅可以快速的领会业务人员的意图,准确的进行报表的评估及高效的进行数据质量稽核等等,还会主动进行报表体系架构的调整、数据模型的优化及脚本效率的提升等等。
但在一支数据团队,我们往往不愿意把最优秀的人放去做报表,即使他现在在做报表,你也会把他调离去做更高level的事情。
现在提做大数据,大家首先想到的就是平台、建模、挖掘及应用,没有人会将报表当成自己未来的专业。
倒并不是说报表不重要,而是做报表往往处于价值创造的中间地带,其在业务上的贡献大多被过顶传球了,很难有亮点可言,而在技术上的贡献,似乎也很少。
这里笔者要为报表的价值和内涵证明一下。

从价值的角度看,报表是衡量企业运营正常与否的晴雨表,在企业的决策支持方面发挥着巨大作用,其重要性往往远超那些模型和标签,只是大家习惯了而已。
事实上,只要报表效率提升那么一点点,其创造的价值就会很大,比如财务报表提个速,虽然可能是润物细无声的。
从内涵的角度看,表哥往往将自己局限在了设想的专业领域,但事实上,要做好报表,牵扯到了组织、机制、流程、中台、技术等各个方面的问题,正如我前面提到的内容一样,我们还有太多技术含量很高的事情要去做,只是挑战都很大。
谁都会做报表,但要做好的确很难。
目前市面上很流行的帆软公司的软件——finereport,功能算是前沿的,可做BI报表和大屏,包括数据整合、建模、分析、可视化制作图表,很适合企业使用。难度不算太大,而效果也不错。









 京公网安备 11010802041100号
京公网安备 11010802041100号