作者:-____Ddddear_534 | 来源:互联网 | 2023-09-15 18:35
Executor 线程池
newCachedThreadPool : 可缓存线程池,当前Pool规模长度超过处理需求回收空线程,不足时可以创建新的线程,无规模限制。
newFixedThreadPool: 固定长度的线程池。控制并发数,达到max之后线程池规模不变。
newScheduledThreadPool: 固定长度的线程池,计划类的线程池,可以设置执行先后,延迟、定时执行等。
newSingleThreadPool:单线程线程池,只能执行一个任务,串行执行。
线程池常用的方法:
1.submit():将线程放入线程池。excute(无返回值)或者 submit(有返回值)----更适合生产者和消费者模式,若线程无返回结果,那么就阻塞当前线程等待线程池结果返回。
2.excute(): 往线程池中添加线程,可能立刻运行,也可能不会。无法预知线程开始、结束时间。
3.shutdown(): 调用此方法之后,表明当前线程已不再接受添加新的线程。
4.shutdownNow(): 不论当前是否有线程执行,马上关闭线程。
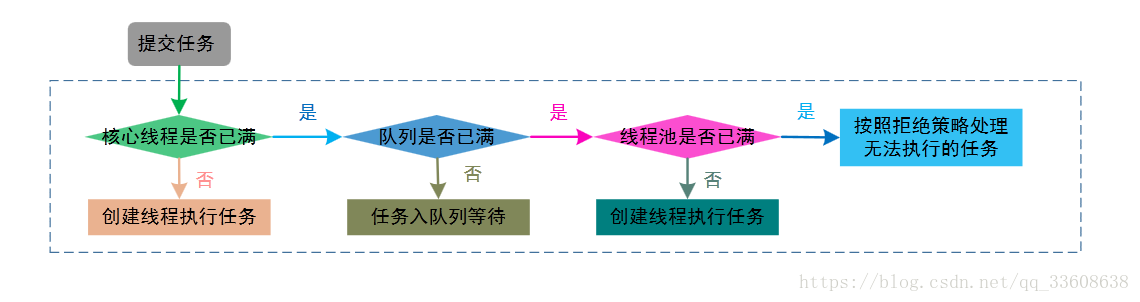
一、线程池创建
先看一下ThreadPoolExecutor参数最全的构造方法:
①corePoolSize:线程池的核心线程数,说白了就是,即便是线程池里没有任何任务,也会有corePoolSize个线程在候着等任务。
②maximumPoolSize:最大线程数,不管你提交多少任务,线程池里最多工作线程数就是maximumPoolSize。
③keepAliveTime:线程的存活时间。当线程池里的线程数大于corePoolSize时,如果等了keepAliveTime时长还没有任务可执行,则线程退出。
⑤unit:这个用来指定keepAliveTime的单位,比如秒:TimeUnit.SECONDS。
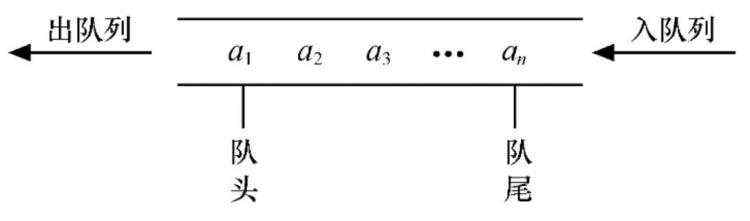
⑥workQueue:一个阻塞队列,提交的任务将会被放到这个队列里。
⑦threadFactory:线程工厂,用来创建线程,主要是为了给线程起名字,默认工厂的线程名字:pool-1-thread-3。
⑧handler:拒绝策略,当线程池里线程被耗尽,且队列也满了的时候会调用。
以上就是创建线程池时用到的参数,面试中经常会有面试官问道这个问题。











 京公网安备 11010802041100号
京公网安备 11010802041100号