2019独角兽企业重金招聘Python工程师标准>>> 
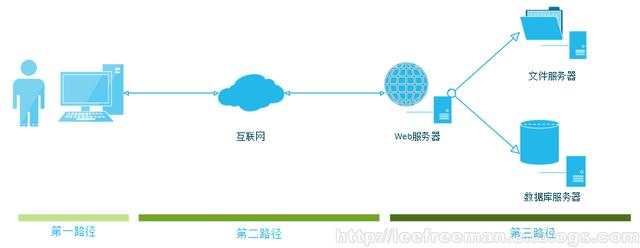
| 高并发访问的核心原则其实就一句话“把所有的用户访问请求都尽量往前推”。 如果把来访用户比作来犯的"敌人",我们一定要把他们挡在800里地以外,即不能让他们的请求一下打到我们的指挥部(指挥部就是数据库及分布式存储)。 如:能缓存在用户电脑本地的,就不要让他去访问CDN。 能缓存CDN服务器上的,就不要让CDN去访问源(静态服务器)了。能访问静态服务器的,就不要去访问动态服务器。以此类推:能不访问数据库和存储就一定不要去访问数据库和存储。 说起来很轻松,实际做起来却不容易,但只要稍加努力是可以做到的,Google的日独立IP过亿不也做到了么?我们这几千万的PV站比起Google不是小屋见大屋了。我们还是先从我们的小屋搭起吧!哈哈!下面内容的介绍起点是千万级别的PV站,也可以支持亿级PV的网站架构。 高性能高并发高可扩展网站架构访问的几个层次: 有人会问,我们老是说把用户对业务的访问往前推,到底怎么推啊?推到哪呢?下面,老男孩就为大家一一道来。 第一层:首先在用户浏览器端,使用Apache的mod_deflate压缩传输,再比如:expires功能、deflate和expires功能利用的好,就会大大提升用户体验效果及减少网站带宽,减少后端服务器的压力。当然,方法还有很多,这里不一一细谈了。 提示:有关压缩传输及expires功能nginx/lighttpd等软件同样也有。 第二层:页面元素,如图片/js/css等或静态数据html,这个层面是网页缓存层,比如CDN(效果比公司自己部署squid/nginx要好,他们更专业,价格低廉,比如快网/CC等(价格80元/M/月甚至更低)而且覆盖的城市节点更多),自己架设squid/nginx cache来做小型CDN是次选(超大规模的公司可能会考虑风险问题实行自建加购买服务结合),除非是为前端的CDN提供数据源服务,以减轻后端我们的服务器数据及存储压力,而不是直接提供cache服务给最终用户。taobao的CDN曾经因为一部分图片的次寸大而导致CDN压力大的情况,甚至对图片尺寸大的来改小,以达到降低流量及带宽的作用。 提示:我们也可以自己架设一层cache层,对我们购买的CDN提供数据源服务,可用的软件有varnish/nginx/squid等cache,以减轻第三层静态数据层的压力。在这层的前端我们也可以架设DNS服务器,来达到跨机房业务拓展及智能解析的目的。 第三层:静态服务器层一般为图片服务器,视频服务器,静态HTML服务器。这一层是前面缓存层和后面动态服务器层的连接纽带,大公司发布新闻等内容直接由发布人员分发到各cache节点(sina,163等都是如此),这和一般公司的业务可能不一样。所以,没法直接的参考模仿,比如人人的SNS。 我们可以使用Q队列方式实现异步的分发访问,同时把动态发布数据(数据库中的数据)静态化存储。即放到本层访问,或通过其他办法发布到各cache节点,而不是直接让所有用户去访问数据库,不知道大家发现了没有,qq.com门户的新闻评论多的有几十万条,如果所有用户一看新闻就加载所有评论,那数据库不挂才怪。他们的评论需要审核(美其名约,实际是异步的方式,而且,评论可能都是静态化的或类似的静态化或内存cache的方式),这点可能就是需要51cto.com这样站点学习的,你们打开51CTO的一篇博文,就会发现下面的评论一直都显示出来了,也可能是分页的。不过,应该都是直接读库的,一旦访问量大,数据库压力大是必然。这里不是说51cto网站不好,所有的网站都是从类似的程序架构开始发展的。CU也可能是如此。 提示:我们可以在静态数据层的前端自己架设一层cache层,对我们购买的CDN提供数据源服务,可用的软件有varnish/nginx/squid 等cache。在这层的前端我们也可以架设DNS服务器,来达到跨机房业务拓展及智能解析的目的。 第四层:动态服务器层:php,java等,只有透过了前面3层后的访问请求才会到这个层,才可能会访问数据库及存储设备。经过前三层的访问过滤能到这层访问请求一般来说已非常少了,一般都是新发布的内容和新发布内容第一次浏览如;博文(包括微博等),BBS帖子。 特别提示:此层可以在程序上多做文章,比如向下访问cache层,memcache,memcachedb,tc,mysql,oracle,在程序级别实现分布式访问,分布式读写分离,而程序级别分布式访问的每个dbcache节点,又可以是一组业务或者一组业务拆分开来的多台服务器的负载均衡。这样的架构会为后面的数据库和存储层大大的减少压力,那么这里呢,相当于指挥部的外层了。 第五层:数据库cache层,比如:memcache,memcachedb,tc等等。 根据不同的业务需求,选择适合具体业务的数据库。对于memcache、memcachedb ttserver及相关nosql数据库,可以在第四层通过程序来实现对本层实现分布式访问,每个分布式访问的节点都可能是一组负载均衡(数十台机器)。 第六层:数据库层,一般的不是超大站点都会用mysql主从结构,如:163,sina,kaixin都是如此,程序层做分布式数据库读写分离,一主(或双主)多从的方式,访问大了,可以做级连的主从及环状的多主多从,然后,实现多组负载均衡,供前端的分布式程序调用,如果访问量在大,就需要拆业务了,比如:我再给某企业做兼职时,发现类似的51cto的一个站点,把www服务,blog服务,bbs服务都放一个服务器上,然后做主从。这种情况,当业务访问量大了,可以简单的把www,blog,bbs服务分别各用一组服务器拆分开,这种方式运维都会的没啥难度。当然访问量在大了,可以继续针对某一个服务拆分如:www库拆分,每个库做一组负载均衡,还可以对库里的表拆分。需要高可用可以通过drbd等工具做成高可用方式。对于写大的,可以做主主或多主的MYSQL REP方式,对于ORACLE来说,来几组oracle DG(1master多salve方式)就够了,11G的DG可以象mysqlrep一样,支持读写分离了。当然可选的方案还有,mysql cluster 和oracle 的RAC,玩mysqlcluster和oracleRAC要需要更好更多的硬件及部署后的大量维护成本,因此,要综合考虑,到这里访问量还很大,那就恭喜了,起码是几千万以上甚至上亿的PV了。 象百度等巨型公司除了会采用常规的mysql及oracle数据库库外,会在性能要求更高的领域,大量的使用nosql数据库,然后前端在加DNS,负载均衡,分布式的读写分离,最后依然是拆业务,拆库,。。。逐步细化,然后每个点又可以是一组或多组机器。 特别提示:数据库层的硬件好坏也会决定访问量的多少,尤其是要考虑磁盘IO的问题,大公司往往在性价比上做文章,比如核心业务采用硬件netapp/emc及san光纤架构,对于资源数据存储,如图片视频,会采用sas或固态ssd盘,如果数据超大,可以采取热点分取分存的方法:如:最常访问的10-20%使用ssd存储,中间的20-30%采用sas盘,最后的40-50%可以采用廉价的sata。 第七层:千万级PV的站如果设计的合理一些,1,2个NFSSERVER就足够了。我所维护(兼职)或经历过的上千万PV的用NFS及普通服务器做存储的还有大把,多一些磁盘,如SAS 15K*6的,或者用dell6850,搞几组 NFS存储,中小网站足够了。当然可以做成drbd+heartbeat+nfs+a/a的方式。 如果能达到本文设计要求的,中等规模网站,后端的数据库及存储压力会非常小了。 象门户网站级别,如sina等,会采用硬件netapp/emc等等硬件存储设备或是san光纤同道,甚至在性价比上做文章,比如核心业务采用硬件netapp/emc及san光纤架构,对于资源数据存储,如图片视频,会采用sas或固态ssd盘,如果数据超到,可以采取热点分取分存的方法:如:最常访问的10-20%使用ssd存储,中间的20-30%采用sas盘,最后的40-50%可以采用廉价的sata。 象百度等巨型公司会采用hadoop等分布式的存储架构,前端在加上多层CACHE及多及的负载均衡,同样会根据业务进行拆分,比如爬虫层存储,索引层存储,服务层存储。。。可以更细更细。。。为了应付压力,什么手段都用上了。 特殊业务,如人人,开心网,包括门户网站的评论,微博,大多都是异步的写入方式,即无论读写,并发访问数据库都是非常少量的。 以上1-7层,如果都搭好了,这样漏网到第四层动态服务器层的访问,就不多了。一般的中等站点,绝对不会对数据库造成太大的压力。程序层的分布式访问是从千万及PV向亿级PV的发展,当然特殊的业务 还需要特殊架构,来合理利用数据库和存储 |











 京公网安备 11010802041100号
京公网安备 11010802041100号