转自个人微信公众号【Memo_Cleon】的统计学习笔记:R笔记:单因素方差分析 | 事后两两多重比较 | 趋势方差分析。
示例来源:李康,贺佳等.医学统计学(第6版).北京:人民卫生出版社,2013.
评价某药物耐受性及安全性的I期临床实验中,将符合纳入标准的30名健康自愿者随机分为3组,每组10名,各组注射剂量分别为0.5U、1U、2U,观察49小时部分凝血活酶时间(s)。不同剂量组的部分凝血活酶时间是否不同?
很明显,剂量可以看做是研究因素,有3个水平,这种完全随机设计的资料首先考虑的就是方差分析。如果方差分析有统计学意义,我们可能还会进一步通过两两比较考察到底是那两组有统计学差异。此外,本例中分组因素为有序变量,我们可能还想知道部分凝血活酶时间是否会随着给药剂量的增加而呈现某种变化趋势,此时我们可以进行趋势检验,检验是否满足线性、二次、三次等多项式变化。对于分组变量和因变量都是分类资料的趋势检验,我们曾在[线性趋势检验]中做过介绍,当前示例是分组变量有序、结局变量为连续的资料,我们可以采用趋势方差检验,即在方差分析中采用多项式对比检验。当然,方差分析也有自己的适用条件:独立性、正态性(各水平因变量服从正态分布,准确地说应该是模型残差服从正态分布)、方差齐性(各水平的总体具有相同的方差),需要进行评估。
当前示例R操作使用了RStudio,下载地址:https://rstudio.com/products/rstudio/download/。RStudio是R语言的一种集成开发环境(IDE),可以更方便的实现R语言操作并增添了很多功能,使用前要首先安装R。
【1】数据导入。不同类型的数据载入涉及到不同的程序包,相同数据类型的导入也有不同的包,excel数据的载入可参见《为什么是R?》,SPSS数据的载入可参见《方差齐性检验》《正态分布的检验》,STATA数据的载入可参见《描述性统计分析》。本例我们使用的是RStudio,导入可以使用菜单操作
Files >> Import Dataset >> From Excel…
自动生成相应命令如下:
library(readxl)
fdata <- read_excel("D:/Temp/fdata.xlsx")
【2】单因素方差分析。R中方差分析有两类方法&#xff0c;一种是采用直接使用方差分析&#xff0c;另外一种是采用线性回归模型。
方差分析的函数比较经典的是aov {stats}&#xff1a;aov(formula, data &#61; NULL, projections &#61; FALSE, qr &#61; TRUE,contrasts &#61; NULL, ...)。
本例命令清单如下&#xff1a;
library(stats)
Fa<-aov(time~dose,data&#61;fdata)
summary(Fa)
结果显示可以认为3个给药剂量的部分凝血活酶时间不同&#xff08;F&#61;6.524&#xff0c;P&#61;0.00488<0.05&#xff09;。
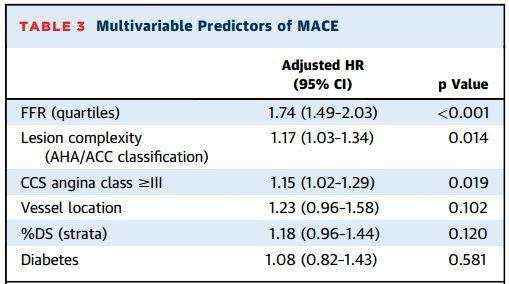
我们也可以采用拟合线性模型的方式来进行方差分析。不论是t检验、方差分析&#xff0c;还是非参数检验&#xff0c;其实都是线性回归的特殊形式而已&#xff0c;感兴趣的可以去阅读Jonas Kristoffer Lindeløv的文章&#xff1a;Common statistical tests are linear models (or: how to teach stats)&#xff0c;我们贴出文章的一张总结表&#xff1a;
线性回归用到函数lm&#xff0c;lm {stats}&#xff1a;used to fit linear models. It can be used to carry out regression, single stratum analysis of variance and analysis of covariance (although aov may provide a more convenient interface for these).
Usage:lm(formula, data, subset, weights, na.action, method &#61; "qr", model &#61; TRUE, x &#61; FALSE, y &#61; FALSE, qr &#61; TRUE,singular.ok &#61; TRUE, contrasts &#61; NULL, offset, ...)
本例采用命令
lrfit<-lm(time~dose,data&#61;fdata)
summary(lrfit)
结果如下&#xff0c;剂量0.5U的部分凝血活酶时间平均值为33.62&#xff0c;统计学上不为0&#xff08;t&#61;40.209&#xff0c;P<0.001&#xff09;&#xff1b;1U与0.5U相比&#xff0c;部分凝血活酶时间更长&#xff08;比0.5U长4.21s&#xff09;&#xff0c;具有统计学意义&#xff08;t&#61;3.56&#xff0c;P&#61;0.0014<0.05&#xff09;;2U与0.5U相比&#xff0c;部分凝血活酶时间更长&#xff08;比0.5U长1.48s&#xff09;&#xff0c;但差异没有有统计学意义&#xff08;t&#61;1.252&#xff0c;P&#61;0.2214>0.05&#xff09;。整体分析结果跟上述方差分析结果是一致的&#xff1a;可以认为3个给药剂量的部分凝血活酶时间不同&#xff08;F&#61;6.524&#xff0c;P&#61;0.00488<0.05&#xff09;。
【3】两两比较。方差分析后如果发现各组之间存在显著的统计学意义&#xff0c;接下来我们可能想知道哪几个组间会存在差异&#xff0c;这就涉及到两两比较&#xff08;或者叫多重比较&#xff09;。多重比较的方法有很多&#xff0c;比如SPSS中提供的两两多重比较方法如下&#xff1a;
这些在R中都不是事儿&#xff0c;因为R有包&#xff0c;“包”治百病&#xff01;比如&#xff1a;
pairwise.t.test {stats}&#xff1a;Calculate pairwise comparisons between group levels with corrections for multiple testing.
Usage: pairwise.t.test(x, g, p.adjust.method &#61; p.adjust.methods,pool.sd &#61; !paired, paired &#61; FALSE,alternative &#61; c("two.sided", "less", "greater"),...)
TukeyHSD {stats}&#xff1a;Create a set of confidence intervals on the differences between the means of the levels of a factor with the specified family-wise probability of coverage. The intervals are based on the Studentized range statistic, Tukey&#39;s ‘Honest Significant Difference’ method.
Usage: TukeyHSD(x, which, ordered &#61; FALSE, conf.level &#61; 0.95, ...)
PostHocTest {DescTools}&#xff1a;A convenience wrapper for computing post-hoc test after having calculated an ANOVA.仅用于R3.6.3及以上版本。
Usage: PostHocTest(x, which &#61; NULL,method &#61; c("hsd", "bonferroni", "lsd", "scheffe", "newmankeuls", "duncan"),conf.level &#61; 0.95, ordered &#61; FALSE, ...)
glht {multcomp}&#xff1a;General linear hypotheses and multiple comparisons for parametric models, including generalized linear models, linear mixed effects models, and survival models.
Usage&#xff1a;glht(model, linfct, ...)
我们以aov {stats}方差分析后的两两为例&#xff0c;上述几种方法的命令及结果如下&#xff1a;
pairwise.t.test(fdata$time, fdata$dose, p.adj &#61; "bonf") ##p.adj方法有"holm", "hochberg", "hommel", "bonferroni", "BH", "BY","fdr", "none"&#xff0c;当前命令以bonferroni进行校正
结果显示&#xff0c;给药剂量0.5U与1U相比&#xff0c;部分凝血活酶时间的差异具有统计学意义&#xff08;P&#61;0.0042<0.05&#xff09;,而0.5U与2U、1U与2U剂量相比&#xff0c;差异并不明显。
TukeyHSD(Fa, "dose", ordered &#61; TRUE)
plot(TukeyHSD(Fa, "dose"))
结果显示&#xff0c;只有给药剂量0.5U与1U相比&#xff0c;部分凝血活酶时间的差异具有统计学意义&#xff08;P&#61;0.0039<0.05&#xff09;,95%CI图中&#xff0c;置信区间没有重合的表示有统计学差异。
library(DescTools)
PostHocTest(Fa,,method &#61; c("lsd"))
采用lsd法的两两差异比较结果跟采用bonferroni的结果有所不同&#xff0c;具体结果如下&#xff1a;
glht {multcomp}函数可用于多种模型&#xff0c;如aov、lm、glm等&#xff0c;但需要将要比较的变量指定为因子变量。命令清单与结果如下&#xff0c;具体结果就不再赘述了。
Dose<-factor(fdata$dose) #采用glht函数需要首先将要比较的变量指定为因子变量
Fc<-aov(fdata$time~Dose)
library(multcomp)
summary(glht(Fc, linfct&#61;mcp(Dose&#61;"Tukey")))
上述命令清单也可以用比对系数的形式进行&#xff0c;命令如下&#xff1a;
contrast<-rbind("0.5U vs 1U" &#61; c(1,-1,0),"0.5U vs 2U" &#61; c(1,0,-1),"1U vs 2U" &#61; c(0,1,-1))
multic<-glht(Fc, linfct&#61;mcp(Dose&#61;contrast))
summary(multic)
通过系数的赋值&#xff0c;可以比较任何两个水平&#xff0c;或者一个跟多个水平的和进行比较。如只想比较0.5U和2U的命令为&#xff1a;summary(glht(Fc, linfct&#61;mcp(Dose&#61;rbind("0.5U vs 2U" &#61; c(1,0,-1)))))
glht {multcomp不仅可用于aov方差分析后的两两比较&#xff0c;也可以用于lm、glm等模型后的多重比较。
Dose<-factor(fdata$dose)
lrfitc<-lm(fdata$time~Dose)
summary(glht(lrfitc, linfct&#61;mcp(Dose&#61;"Tukey")))
【4】趋势方差检验。给药剂量0.5U、1U、2U为有序变量&#xff0c;我们可以考察随着给药剂量的增加&#xff0c;部分凝血活酶时间呈二次项变化趋势还是呈线性趋势。在R中要进行趋势方差分析&#xff0c;需要先将分析的变量设置为有序因子&#xff0c;然后采用正交多项式的对照&#xff0c;就可以进行趋势分析&#xff08;线性、二次、三次等&#xff09;&#xff0c;但比较遗憾的是只能用于等距水平的有序因子。本例实际上不等距&#xff0c;因此仅做演示。在SPSS中&#xff0c;一般线性模型中的单变量分析&#xff08;Univariate&#xff09;的Polynomial也提供了同样的等距有序因子的趋势分析&#xff0c;而One-Way ANOVA的Polynomial比对可进行等距和不等距的因子分析。
Dose_ord<-factor(fdata$dose,order&#61;TRUE,levels&#61;c("0.5U", "1U", "2U")) #设置有序因子
lrfit_ord<-lm(fdata$time~Dose_ord,contrasts &#61; "contr.poly") #contr.poly用于趋势分析&#xff08;线性、二次、三次等&#xff09;和等距水平的有序因子
summary(lrfit_ord)
plot(Dose_ord, fdata$time) #用图形展示变化趋势&#xff0c;或者使用命令&#xff1a;boxplot(time~dose,data&#61;fdata)
结果显示二次项(quadratic)结果的系数&#xff08;Dose_ord.Q&#xff09;具有统计学意义&#xff0c;表明二次项的系数不为0&#xff0c;即随着给药剂量的增加&#xff0c;部分凝血活酶时间呈二次项变化趋势&#xff0c;大体呈先升后降的趋势&#xff0c;后面的趋势图也证实的确如此。但需要说明的是本例0.5U、1U、2U并不等距&#xff0c;contr.poly是被就、强制呈等距来进行分析&#xff0c;因此结论应谨慎。
统计分析方法都有自己的适用条件&#xff0c;方差分析要求独立、正态和方差齐同&#xff0c;最后我们评估一下下正态性和方差齐性。
【5】正态分布检验。本例采用shapiro检验&#xff0c;其他方法可参见《正态分布的检验》。
library(stats)
by(fdata$time,fdata$dose,shapiro.test) #对fdata中的time变量按dose分组进行shapiro检验
结果显示3个变量均P均&#xff1e;0.05&#xff0c;都满足正态分布。
【6】方差齐性检验。本例采用levene检验&#xff0c;其他方法可参见《方差齐性检验》。
library(car)
library(carData)
leveneTest(time~dose,data&#61;fdata,center&#61;mean) #levene方差齐性检验&#xff0c;默认以中位值进行检测
结果显示两个水平的均值满足方差齐性&#xff08;F&#61;1.85,P&#61;0.177>0.05&#xff09;。结果后面有一条警示信息&#xff0c;group变量被强制定义为因子。
转自个人微信公众号【Memo_Cleon】的统计学习笔记&#xff1a;R笔记&#xff1a;单因素方差分析 | 事后两两多重比较 | 趋势方差分析。
END











![微信商户扫码支付 java开发 [从零开发]](https://img8.php1.cn/3cdc5/1ea6b/a6e/077c0283247408a9.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号