CPU缓存系统中是以缓存行(cache line)为单位存储的。目前主流的CPU Cache的Cache Line大小都是64Bytes。在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing)。
由于共享变量在CPU缓存中的存储是以缓存行为单位,一个缓存行可以存储多个变量(存满当前缓存行的字节数);而CPU对缓存的修改又是以缓存行为最小单位的,那么就会出现上诉的伪共享问题。
Cache Line可以简单的理解为CPU Cache中的最小缓存单位,今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
由于CPU的速度远远大于内存速度,所以CPU设计者们就给CPU加上了缓存(CPU Cache)。 以免运算被内存速度拖累。(就像我们写代码把共享数据做Cache不想被DB存取速度拖累一样),CPU Cache分成了三个级别:L1,L2,L3。越靠近CPU的缓存越快也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。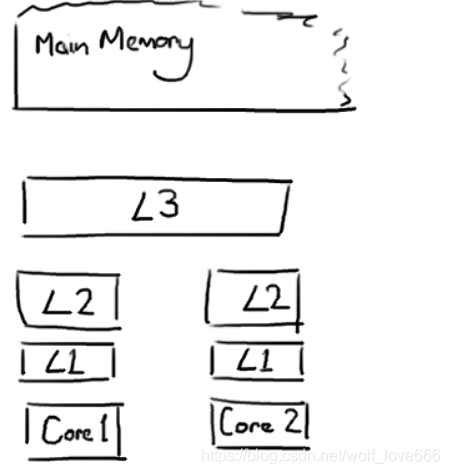
目前常用的缓存设计是N路组关联(N-Way Set Associative Cache),他的原理是把一个缓存按照N个Cache Line作为一组(Set),缓存按组划为等分。每个内存块能够被映射到相对应的set中的任意一个缓存行中。比如一个16路缓存,16个Cache Line作为一个Set,每个内存块能够被映射到相对应的Set
中的16个CacheLine中的任意一个。一般地,具有一定相同低bit位地址的内存块将共享同一个Set。
下图为一个2-Way的Cache。由图中可以看到Main Memory中的Index0,2,4都映射在Way0的不同CacheLine中,Index1,3,5都映射在Way1的不同CacheLine中。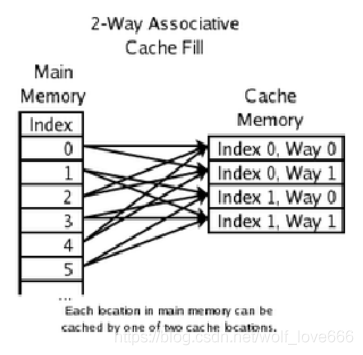
多核CPU都有自己的专有缓存(一般为L1,L2),以及同一个CPU插槽之间的核共享的缓存(一般为L3)。不同核心的CPU缓存中难免会加载同样的数据,那么如何保证数据的一致性呢,就是MESI协议了。
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
I(Invalid):这行数据无效。
那么,假设有一个变量i=3(应该是包括变量i的缓存块,块大小为缓存行大小);已经加载到多核(a,b,c)的缓存中,此时该缓存行的状态为S;此时其中的一个核a改变了变量i的值,那么在核a中的当前缓存行的状态将变为M,b,c核中的当前缓存行状态将变为I。如下图:
为了避免由于false sharing 导致CacheLine从L1,L2,L3到主存之间重复载入,我们可以使用数据填充的方式来避免,即单个数据填充满一个CacheLine。这本质是一种空间换时间的做法。
Java8中已经提供了官方的解决方案,Java8中新增了一个注解:@sun.misc.Contended。加上这个注解的类会自动补齐缓存行,需要注意的是此注解默认是无效的,需要在jvm启动时设置-XX:-RestrictContended才会生效,如果需要自定义宽度可以设置为-XX:ContendedPaddingWidth参数。
x86汇编指令,表示交换加,即先将两个数交换,再将二者之和送给第一个数。
写法:XADD reg/mem, reg
作用:先将两个数交换,然将二者之和送给第一个数。
java.util.concurrency.atomic.LongAdder是Java8新增的一个类,提供了原子累计值的方法。根据文档的描述其性能要优于AtomicLong,下图是一个简单的测试对比(平台:MBP):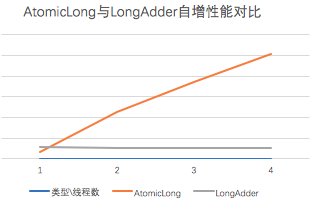
这里测试时基于JDK1.8进行的,AtomicLong 从Java8开始针对x86平台进行了优化,使用XADD替换了CAS操作,我们知道JUC下面提供的原子类都是基于Unsafe类实现的,并由Unsafe来提供CAS的能力。CAS (compare-and-swap)本质上是由现代CPU在硬件级实现的原子指令,允许进行无阻塞,多线程的数据操作同时兼顾了安全性以及效率。大部分情况下,CAS都能够提供不错的性能,但是在高竞争的情况下开销可能会成倍增长,具体的研究可以参考这篇文章, 我们直接看下代码:
public class AtomicLong {
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
}
public final class Unsafe {
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
}
getAndAddLong方法会以volatile的语义去读需要自增的域的最新值,然后通过CAS去尝试更新,正常情况下会直接成功后返回,但是在高并发下可能会同时有很多线程同时尝试这个过程,也就是说线程A读到的最新值可能实际已经过期了,因此需要在while循环中不断的重试,造成很多不必要的开销(在高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,这样导致大大浪费CPU资源,降低了并发性),
而xadd的相对来说会更高效一点,伪码如下,最重要的是下面这段代码是原子的,也就是说其他线程不能打断它的执行或者看到中间值,这条指令是在硬件级直接支持的:
function FetchAndAdd(address location, int inc) {
int value := *location
*location := value + inc
return value
}
而LongAdder的性能比上面那种还要好很多,于是就研究了一下。首先它有一个基础的值base,在发生竞争的情况下,会有一个Cell数组用于将不同线程的操作离散到不同的节点上去(会根据需要扩容,最大为CPU核数),sum()会将所有Cell数组中的value和base累加作为返回值。核心的思想就是将AtomicLong一个value的更新压力分散到多个value中去,从而降低更新热点。
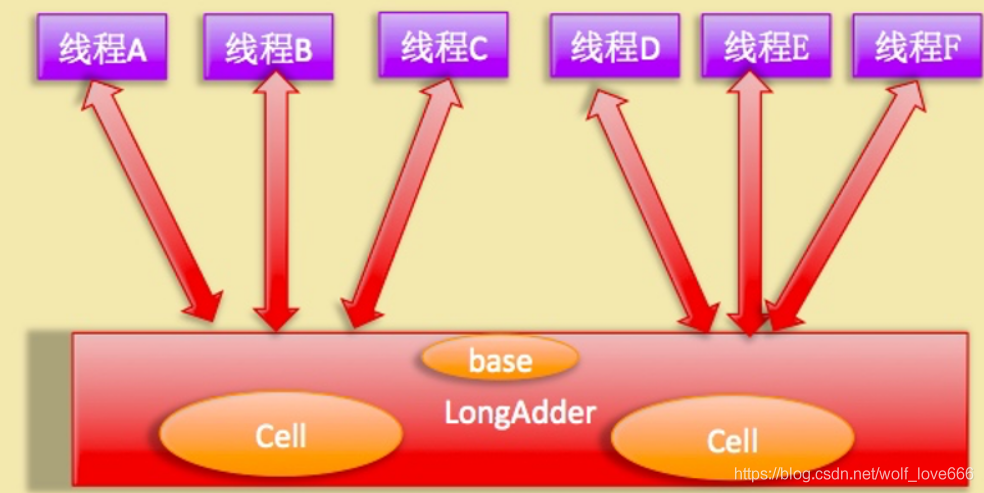
如上图所示,LongAdder则是内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同一个原子变量时候,
如果失败并不是自旋CAS重试,而是尝试获取其他原子变量的锁,最后当获取当前值时候是把所有变量的值累加后再加上base的值返回的。
LongAdder维护了要给延迟初始化的原子性更新数组和一个基值变量base数组的大小保持是2的N次方大小,数组表的下标使用每个线程的hashcode值的掩码表示,数组里面的变量实体是Cell类型。
Cell 类型是Atomic的一个改进,用来减少缓存的争用,对于大多数原子操作字节填充是浪费的,因为原子操作都是无规律的分散在内存中进行的,多个原子性操作彼此之间是没有接触的,但是原子性数组元素彼此相邻存放将能经常共享缓存行,也就是伪共享。所以这在性能上是一个提升。(补充:可以看到Cell类用Contended注解修饰,这里主要是解决false sharing(伪共享的问题),不过个人认为伪共享翻译的不是很好,或者应该是错误的共享,比如两个volatile变量被分配到了同一个缓存行,但是这两个的更新在高并发下会竞争,比如线程A去更新变量a,线程B去更新变量b,但是这两个变量被分配到了同一个缓存行,因此会造成每个线程都去争抢缓存行的所有权,例如A获取了所有权然后执行更新这时由于volatile的语义会造成其刷新到主存,但是由于变量b也被缓存到同一个缓存行,因此就会造成cache miss,这样就会造成极大的性能损失)
LongAdder的add操作图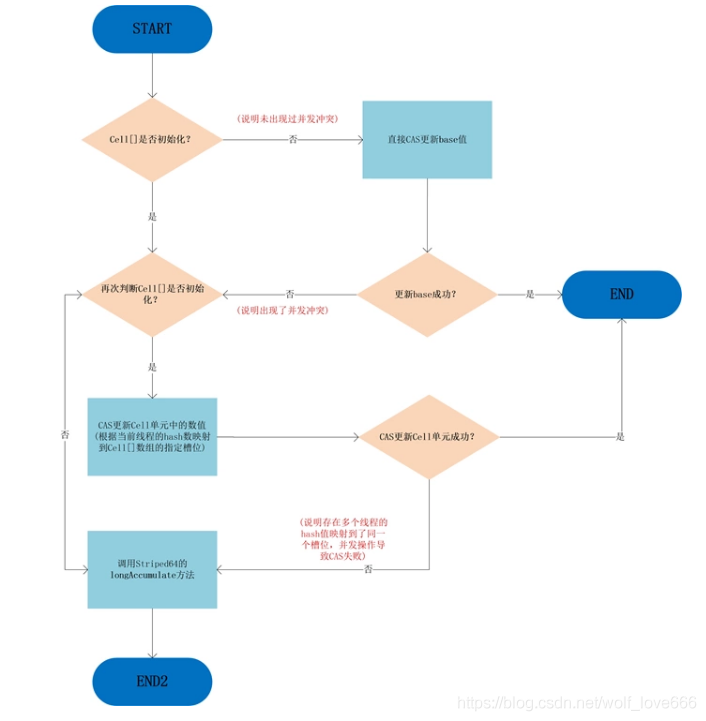
可以看到,只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对Cell[]数组中的单元Cell。
如果Cell[]数组未初始化,会调用父类的longAccumelate去初始化Cell[],如果Cell[]已经初始化但是冲突发生在Cell单元内,则也调用父类的longAccumelate,此时可能就需要对Cell[]扩容了。
另外由于Cells占用内存是相对比较大的,所以一开始并不创建,而是在需要时候再创建,也就是惰性加载,当一开始没有空间时候,所有的更新都是操作base变量。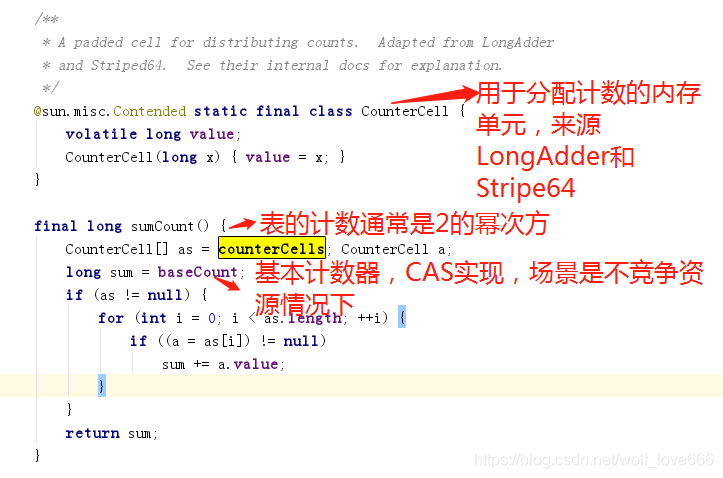
如上图代码:
例如32、64位操作系统的缓存行大小不一样,因此JAVA8中就增加了一个注@sun.misc.Contended解用于解决这个问题,由JVM去插入这些变量,具体可以参考openjdk.java.net/jeps/142 ,但是通常来说对象是不规则的分配到内存中的,但是数组由于是连续的内存,因此可能会共享缓存行,因此这里加一个Contended注解以防cells数组发生伪共享的情况。
为了降低高并发下多线程对一个变量CAS争夺失败后大量线程会自旋而造成降低并发性能问题,LongAdder内部通过根据并发请求量来维护多个Cell元素(一个动态的Cell数组)来分担对单个变量进行争夺资源。

可以看到LongAdder继承自Striped64类,Striped64内部维护着三个变量,LongAdder的真实值其实就是base的值与Cell数组里面所有Cell元素值的累加,base是个基础值,默认是0,cellBusy用来实现自旋锁,当创建Cell元素或者扩容Cell数组时候用来进行线程间的同步。
在无竞争下直接更新base,类似AtomicLong高并发下,会将每个线程的操作hash到不同的cells数组中,从而将AtomicLong中更新一个value的行为优化之后,分散到多个value中
从而降低更新热点,而需要得到当前值的时候,直接 将所有cell中的value与base相加即可,但是跟AtomicLong(compare and change -> xadd)的CAS不同,incrementAndGet操作及其变种可以返回更新后的值,而LongAdder返回的是void。
由于Cell相对来说比较占内存,因此这里采用懒加载的方式,在无竞争的情况下直接更新base域,在第一次发生竞争的时候(CAS失败)就会创建一个大小为2的cells数组,每次扩容都是加倍,只到达到CPU核数。同时我们知道扩容数组等行为需要只能有一个线程同时执行,因此需要一个锁,这里通过CAS更新cellsBusy来实现一个简单的spin lock。
数组访问索引是通过Thread里的threadLocalRandomProbe域取模实现的,这个域是ThreadLocalRandom更新的,cells的数组大小被限制为CPU的核数,因为即使有超过核数个线程去更新,但是每个线程也只会和一个CPU绑定,更新的时候顶多会有cpu核数个线程,因此我们只需要通过hash将不同线程的更新行为离散到不同的slot即可。
我们知道线程、线程池会被关闭或销毁,这个时候可能这个线程之前占用的slot就会变成没人用的,但我们也不能清除掉,因为一般web应用都是长时间运行的,线程通常也会动态创建、销毁,很可能一段时间后又会被其他线程占用,而对于短时间运行的,例如单元测试,清除掉有啥意义呢?
LongAdder源码核心方法:
1.long sum() 方法:返回当前的值,内部操作是累加所有 Cell 内部的 value 的值后累加 base,如下代码,由于计算总和时候没有对 Cell 数组进行加锁,所以在累加过程中可能有其它线程对 Cell 中的值进行了修改,也有可能数组进行了扩容,所以 sum 返回的值并不是非常精确的,
返回值并不是一个调用 sum 方法时候的一个原子快照值。
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i 2.void reset() 方法:重置操作,如下代码把 base 置为 0,如果 Cell 数组有元素,则元素值重置为 0。源码如下:
public void reset() {
Cell[] as = cells; Cell a;
base = 0L;
if (as != null) {
for (int i = 0; i 3.long sumThenReset() 方法:是sum 的改造版本,如下代码,在计算 sum 累加对应的 cell 值后,把当前 cell 的值重置为 0,base 重置为 0。 当多线程调用该方法时候会有问题,比如考虑第一个调用线程会清空 Cell 的值,后一个线程调用时候累加时候累加的都是 0 值。
public long sumThenReset() {
Cell[] as = cells; Cell a;
long sum = base;
base = 0L;
if (as != null) {
for (int i = 0; i 4.long longValue() 等价于 sum(),源码如下:
public long longValue() {
return this.sum();
}
5.void add(long x) 累加增量 x 到原子变量,这个过程是原子性的。源码如下:
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {//(1)
boolean uncOntended= true;
if (as == null || (m = as.length - 1) <0 ||//(2)
(a = as[getProbe() & m]) == null ||//(3)
!(uncOntended= a.cas(v = a.value, v + x)))//(4)
longAccumulate(x, null, uncontended);//(5)
}
}
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
可以看到上面代码,当第一个线程A执行add时候,代码(1)会执行casBase方法,通过CAS设置base为 X, 如果成功则直接返回,这时候base的值为1。
假如多个线程同时执行add时候,同时执行到casBase则只有一个线程A成功返回,其他线程由于CAS失败执行代码(2),代码(2)是获取cells数组的长度,如果数组长度为0,则执行代码(5),否则cells长度不为0,说明cells数组有元素则执行代码(3),
代码(3)首先计算当前线程在数组中下标,然后获取当前线程对应的cell值,如果获取到则执行(4)进行CAS操作,CAS失败则执行代码(5)。
代码(5)里面是具体进行数组扩充和初始化
LongAccumulator类源码分析
LongAdder类是LongAccumulator的一个特例,LongAccumulator提供了比LongAdder更强大的功能,如下构造函数,其中accumulatorFunction是一个双目运算器接口,根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
public LongAccumulator(LongBinaryOperator accumulatorFunction,long identity) {
this.function = accumulatorFunction;
base = this.identity = identity;
}
public interface LongBinaryOperator {
//根据两个参数计算返回一个值
long applyAsLong(long left, long right);
}
上面提到LongAdder 其实就是LongAccumulator 的一个特例,调用LongAdder 相当使用下面的方式调用 LongAccumulator
LongAdder adder = new LongAdder();
LongAccumulator accumulator = new LongAccumulator(new LongBinaryOperator() {
@Override
public long applyAsLong(long left, long right) {
return left + right;
}
}, 0);
LongAccumulator相比LongAdder 可以提供累加器初始非0值,后者只能默认为0,另外前者还可以指定累加规则,比如不是累加而相乘,只需要构造LongAccumulator 时候传入自定义双目运算器即可,后者则内置累加规则。
从下面代码知道LongAccumulator相比于LongAdde的不同在于casBase的时候,后者传递的是b+x,而前者则是调用了r=function.applyAsLong(b=base.x)来计算。
LongAdder类的add源码如下:
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncOntended= true;
if (as == null || (m = as.length - 1) <0 ||
(a = as[getProbe() & m]) == null ||
!(uncOntended= a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
LongAccumulator的accumulate方法的源码如下:
public void accumulate(long x) {
Cell[] as; long b, v, r; int m; Cell a;
if ((as = cells) != null ||
(r = function.applyAsLong(b = base, x)) != b && !casBase(b, r)) {
boolean uncOntended= true;
if (as == null || (m = as.length - 1) <0 ||
(a = as[getProbe() & m]) == null ||
!(uncOntended=
(r = function.applyAsLong(v = a.value, x)) == v ||
a.cas(v, r)))
longAccumulate(x, function, uncontended);
}
}
另外LongAccumulator调用longAccumulate时候传递的是function,而LongAdder是null,从下面代码可以知道当fn为null,时候就是使用v+x 加法运算,这时候就等价于LongAdder,fn不为null的时候则使用传递的fn函数计算,如果fn为加法则等价于LongAdder;
else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))
// Fall back on using base
break;
参考:https://github.com/aCoder2013/blog/issues/22
![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有