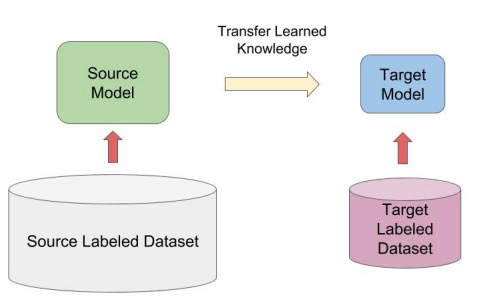
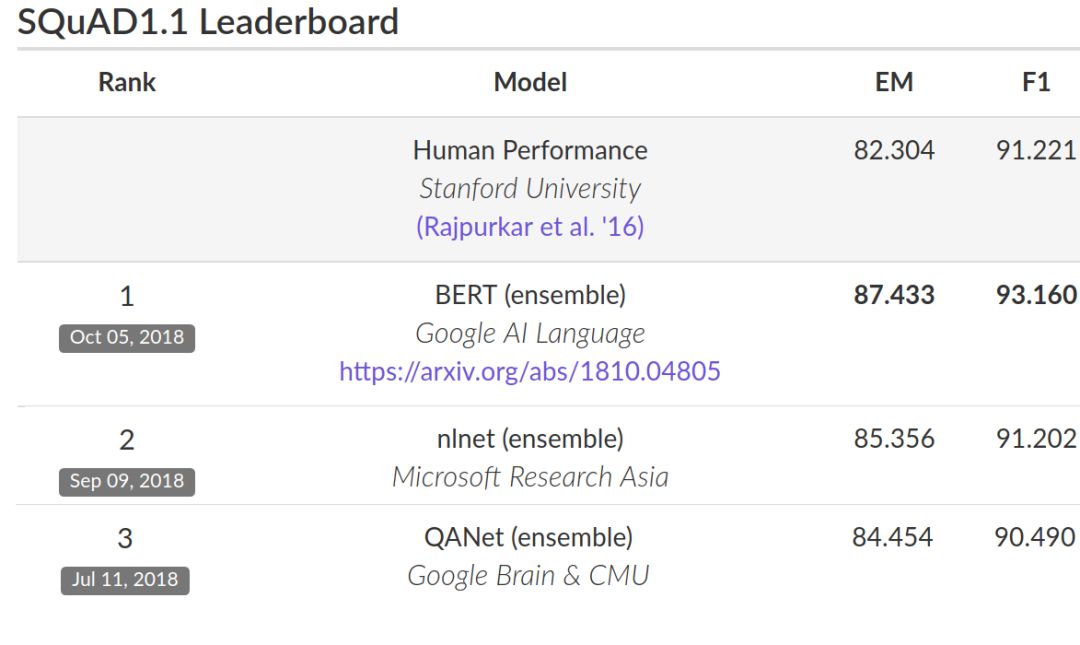
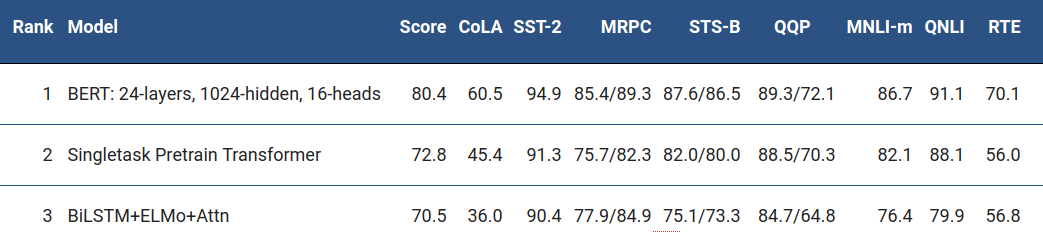
不过话说回来,第一个使用Transformer的预训练模型不是bert,而是GPT。想要进一步了解GPT模型的同学,可以阅读补充资料(OpenAI GPT: Generative Pre-Training for Language Understanding),如果你不了解Transformer结构,我建议你先不要阅读,等阅读完系列文章后,再来品味一下GPT与BERT的不同。
# 导入所需要的包 from functools import partial import argparse import os import random import timeimport numpy as np import paddle import paddle.nn.functional as Fimport paddlenlp as ppnlp from paddlenlp.data import Stack, Tuple, Pad from paddlenlp.datasets import load_dataset from paddlenlp.transformers import LinearDecayWithWarmup
# 将文本内容转化成模型所需要的token id defconvert_example(example, tokenizer, max_seq_length=512, is_test=False):"""Builds model inputs from a sequence or a pair of sequence for sequence classification tasksby concatenating and adding special tokens. And creates a mask from the two sequences passed to be used in a sequence-pair classification task."""encoded_inputs = tokenizer(text=example["text"], max_seq_len=max_seq_length)input_ids = encoded_inputs["input_ids"]token_type_ids = encoded_inputs["token_type_ids"]ifnot is_test:label = np.array([example["label"]], dtype="int64")return input_ids, token_type_ids, labelelse:return input_ids, token_type_ids
# 样本转换函数 trans_func = partial(convert_example,tokenizer=tokenizer,max_seq_length=MAX_LEN) batchify_fn =lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),# inputPad(axis=0, pad_val=tokenizer.pad_token_type_id),# segmentStack(dtype="int64")# label):[data for data in fn(samples)] train_data_loader = create_dataloader(train_ds,mode='train',batch_size=BATCH_SIZE,batchify_fn=batchify_fn,trans_fn=trans_func) dev_data_loader = create_dataloader(dev_ds,mode='dev',batch_size=BATCH_SIZE,batchify_fn=batchify_fn,trans_fn=trans_func) test_data_loader = create_dataloader(test_ds,mode='test',batch_size=BATCH_SIZE,batchify_fn=batchify_fn,trans_fn=trans_func)
# 调用bert的预训练模型 model = ppnlp.transformers.BertForSequenceClassification.from_pretrained('bert-base-chinese', num_classes=len(train_ds.label_list))
# 完成训练设置 num_training_steps =len(train_data_loader)* EPOCHSlr_scheduler = LinearDecayWithWarmup(LR, num_training_steps, WARMUP_STEPS)# Generate parameter names needed to perform weight decay. # All bias and LayerNorm parameters are excluded. decay_params =[p.name for n, p in model.named_parameters()ifnotany(nd in n for nd in["bias","norm"]) ] optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=0.0,apply_decay_param_fun=lambda x: x in decay_params)criterion = paddle.nn.loss.CrossEntropyLoss() metric = paddle.metric.Accuracy()














 京公网安备 11010802041100号
京公网安备 11010802041100号