作者:mobiledu2502909027 | 来源:互联网 | 2023-09-25 21:13
目录IntroductionMethodVisionTransformer(ViT)Fine-tuningandHigherResolutionExperimentsSetupCo
目录 Introduction Method Vision Transformer (ViT) Fine-tuning and Higher Resolution Experiments Setup Comparison to SOTA Pre-training data requirements Scaling study Inspecting ViT Self-Supervision References
Introduction ViT 这篇论文提出,在图像分类任务中,CNN 并非必须的 , pure Transformer 也能取得很好的效果。特别是在大量数据上预训练 后再迁移到中小型数据集上时 (ImageNet, CIFAR-100, VTAB, etc.),相比 SOTA CNNs,ViT 仅需更少的训练资源就能取得更好的效果 Method Vision Transformer (ViT)
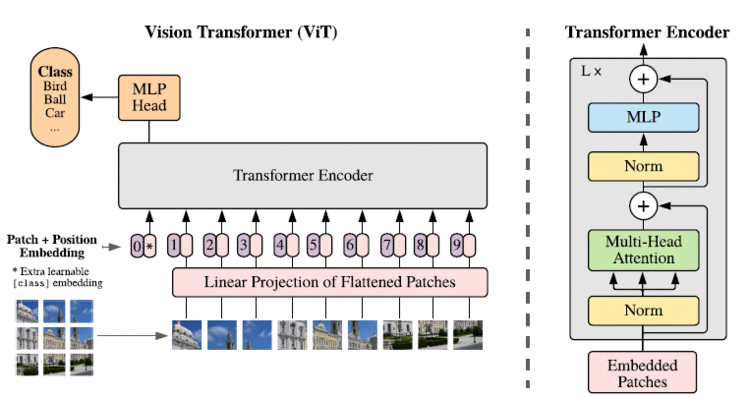
标准的 Transformer 接受 token embeddings 的序列,因此为了能直接将 Transformer Encoder 应用到图像上,我们需要将 2D 图像处理为 1D 向量。一个很直接的想法就是将图片像素经过 Embedding 层后送入 Transformer,但一张图片的像素很多,这样做会导致输入序列长度过长。为此,ViT 将一张图片划分为若干个 P×P=16×16P\times P=16\times 16 P × P = 1 6 × 1 6 ,然后将每个 patch 拉伸为一个向量,送入线性层得到相应的 Embedding。例如,输入图像大小为 224×224×3224\times224\times3 2 2 4 × 2 2 4 × 3 N=2242162=196N=\frac{224^2}{16^2}=196 N = 1 6 2 2 2 4 2 = 1 9 6 16×16×3=76816\times16\times3=768 1 6 × 1 6 × 3 = 7 6 8 D×DD\times D D × D N×D=196×768N\times D=196\times768 N × D = 1 9 6 × 7 6 8 position embeddings 来表示 patches 之间的位置信息 (learnable 1D position embeddings) 为了对图片进行分类,类似于 BERT,ViT 也添加了 [class] token196+1=197196+1=197 1 9 6 + 1 = 1 9 7 yy y classification head 之后就得到了图片的最终类别 (classification head 在预训练时为一个带有一层隐藏层的 MLP,微调时为一个线性层,激活函数为 GELU)
GAP v.s. [CLS] [CLS] 进行分类的消融实验,当使用 GAP 时,ViT 只对最终的 image-patch embeddings 进行全局平均池化,然后使用线性层进行分类 (但注意这种方法需要的学习率与 [CLS] 完全不同)。实验结果表明这两种方法效果是差不多的,但为了使得 ViT 与标准 Transformer 更接近,作者最终采用了 [CLS] 进行分类
Inductive bias (归纳偏置)
ViT 比 CNN 少了很多针对图像的归纳偏置,例如在 CNN 中,locality (i.e. 局部性. 图片上相邻区域会有相近特征) 和 translation equivariance (i.e. 平移等变性. 设 ff f gg g f(g(x))=g(f(x))f(g(x))=g(f(x)) f ( g ( x ) ) = g ( f ( x ) ) 在整个 ViT 中,也只有 positional embedding 使用了针对图像的归纳偏置,除此之外,所有图像的位置信息都必须由模型从头学得 因此由于缺少了归纳偏置,当直接在中等大小数据集 (ImageNet…) 上训练且不进行强正则化时,ViT 性能并没有同等大小的 ResNet 模型好。但如果让 ViT 在更大的数据集上预训练 ,就可以发现大规模训练胜过了归纳偏置 (88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55% on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks ) Hybrid Architecture
除了上述直接将图像划分为若干个 16×1616\times16 1 6 × 1 6 Fine-tuning and Higher Resolution 当把预训练的 ViT 模型在下游任务上微调时,我们需要重新训练 classification head 。如果下游任务图像分辨率更高 ,模型往往会取得更好的效果,此时如果保持 patch size 不变,那么就会得到更大的序列长度,但此时就无法获取有意义的 positional embedding。为此,ViT 对预训练的 positional embedding 进行 2D 插值 Experiments Setup Datasets
ILSVRC-2012 ImageNet dataset (1k classes and 1.3M images)ImageNet-21k (21k classes and 14M images)JFT (18k classes and 303M high-resolution images) 预训练数据集中去除了与下游任务数据集重合的图片
Model Variants
“Base” 和 “Large” 模型与 BERT 一致,此外还添加了 “Huge” 模型. 在之后的模型命名中,我们使用简称,例如 ViT-L/16 表示 16×1616 × 16 1 6 × 1 6 Baseline - ResNet (BiT)
网络使用 ResNet ,但将 Batch Normalization 替换为了 Group Normalization ,并且使用了 standardized convolutions ,这些修改提高了迁移学习的性能。我们将修改后的模型称为 “ResNet (BiT) ”. Comparison to SOTA
可以看到,在 JFT-300M 上预训练的 ViT 在所有 benchmarks 上性能都超越了 ResNet-based baselines,并且相比 CNN,ViT 需要的训练资源更少 Pre-training data requirements 在不同大小的数据集上预训练后,在 ImageNet 上微调
灰色阴影区域代表 BiT 的性能范围 (分别使用了两个不同大小的 BiT 网络)
为了提高模型在小数据集上的性能,实验时使用了 3 种正则化方法 - weight decay, dropout, 和 label smoothing 并对相应的参数进行了优化
使用 JFT 数据集的不同大小的子集进行预训练,在 ImageNet 上微调
实验时不再进行额外的正则化来排除正则化带来的影响
Scaling study 在 JFT-300M 上预训练,迁移到其他数据集上
(1) ViT 在 performance/compute trade-off 上碾压了 ResNet,仅需更少的训练资源就可以达到与 ResNet 相同的性能 (假设在足够大的数据集上预训练) (2) 在训练资源较少时,hybrids 模型性能略微优于 ViT,但差距随着模型参数量的增加而逐渐减小 (3) 随着模型参数量的增大,ViT 性能并没有饱和的迹象,这表明继续增大模型大小可以进一步提高模型性能 Inspecting ViT Patch embedding 层
ViT 的 patch embedding 层将 flattened patches 进行了线性投影,下图显示了学得的 embedding filters 的主成分 。这些主成分似乎形成了一组能表示 patch 纹理结构的基函数 Position embeddings
下图展示了每个 patch 与其余 patch 的余弦相似度。可以看到,空间上更相近的 patches 对应的 position embeddings 也更相似 ,除此之外,在同一行或同一列的 patches 对应的 position embeddings 也更相似 (a row-column structure) Self-attention
Self-attention 使得 ViT 能从最底层开始就整合图片的全局信息,下面的实验探索了 ViT 在多大程度上利用了这种能力。为此,我们计算了每个 Transformer 块的不同 heads 的 mean attention distance (根据每个 head 中不同 patches 之间的空间距离和 attention weight 计算,类似于 CNN 中的感受野),可以发现,有一些 heads 在最底层就已经开始整合图像的全局信息,而另一些 heads 在最底层只负责整合局部信息 (这种局部性在 hybrids 模型中表现得更少,这表明它们的功能可能与 CNN 的较低层相近),并且总体而言,attention distances 随着网络深度的增加而增加 ,表明随着层数的增加,ViT 逐渐关注更高层次的信息 Attention map
这里使用 Attention Rollout 进行可视化。简单地说,就是对 ViT-L/16 的所有 heads 中的 attention weights 计算平均值,然后对于所有层,递归地乘上权重矩阵 Self-Supervision Transformers 在 NLP 领域的成功不仅来源于它强大的可扩展性,更在于它大规模自监督的预训练方式。因此,类似 BERT,我们也尝试了 masked patch prediction ,最终的 ViT-B/16 模型在 ImageNet 上取得了 79.9% 的精度,这比从头训练得到的精度高了 2%,但也比有监督学习精度低了 4%。这表明 ViT 的自监督学习 仍是一个值得探索的方向 References paper : An Image is Worth 16x16 Words: Transformers for Image Recognition at ScaleFine-tuning code and pre-trained models : https://github.com/google-research/vision_transformerViT 论文逐段精读【论文精读】 Intriguing Properties of Vision Transformers



















 京公网安备 11010802041100号
京公网安备 11010802041100号