作者:golanger | 来源:互联网 | 2023-10-10 14:05
卷积神经网络(CNN)模型结构 转载:http:www.cnblogs.compinardp6483207.html 看到的一片不错的文章,先转过来留着,怕以后博主删了
卷积神经网络(CNN)模型结构
转载:http://www.cnblogs.com/pinard/p/6483207.html 看到的一片不错的文章,先转过来留着,怕以后博主删了。哈哈哈
在前面我们讲述了DNN的模型与前向反向传播算法。而在DNN大类中,卷积神经网络(Convolutional Neural Networks,以下简称CNN)是最为成功的DNN特例之一。CNN广泛的应用于图像识别,当然现在也应用于NLP等其他领域,本文我们就对CNN的模型结构做一个总结。
在学习CNN前,推荐大家先学习DNN的知识。如果不熟悉DNN而去直接学习CNN,难度会比较的大。这是我写的DNN的教程:
深度神经网络(DNN)模型与前向传播算法
深度神经网络(DNN)反向传播算法(BP)
深度神经网络(DNN)损失函数和激活函数的选择
深度神经网络(DNN)的正则化
1. CNN的基本结构
首先我们来看看CNN的基本结构。一个常见的CNN例子如下图:

图中是一个图形识别的CNN模型。可以看出最左边的船的图像就是我们的输入层,计算机理解为输入若干个矩阵,这点和DNN基本相同。
接着是卷积层(Convolution Layer),这个是CNN特有的,我们后面专门来讲。卷积层的激活函数使用的是ReLU。我们在DNN中介绍过ReLU的激活函数,它其实很简单,就是
最终我们得到卷积输出的矩阵为一个2×3的矩阵S。
再举一个动态的卷积过程的例子如下:
我们有下面这个绿色的5×5输入矩阵,卷积核是一个下面这个黄色的3×3的矩阵。卷积的步幅是一个像素。则卷积的过程如下面的动图。卷积的结果是一个3×3的矩阵。


上面举的例子都是二维的输入,卷积的过程比较简单,那么如果输入是多维的呢?比如在前面一组卷积层+池化层的输出是3个矩阵,这3个矩阵作为输入呢,那么我们怎么去卷积呢?又比如输入的是对应RGB的彩色图像,即是三个分布对应R,G和B的矩阵呢?
在斯坦福大学的cs231n的课程上,有一个动态的例子,链接在这。建议大家对照着例子中的动图看下面的讲解。
大家打开这个例子可以看到,这里面输入是3个7×7的矩阵。实际上原输入是3个5×5的矩阵。只是在原来的输入周围加上了1的padding,即将周围都填充一圈的0,变成了3个7×7的矩阵。 例子里面使用了两个卷积核,我们先关注于卷积核W0。和上面的例子相比,由于输入是3个7×7的矩阵,或者说是7x7x3的张量,则我们对应的卷积核W0也必须最后一维是3的张量,这里卷积核W0的单个子矩阵维度为3×3。那么卷积核W0实际上是一个3x3x3的张量。同时和上面的例子比,这里的步幅为2,也就是每次卷积后会移动2个像素的位置。 最终的卷积过程和上面的2维矩阵类似,上面是矩阵的卷积,即两个矩阵对应位置的元素相乘后相加。这里是张量的卷积,即两个张量的3个子矩阵卷积后,再把卷积的结果相加后再加上偏倚b。 7x7x3的张量和3x3x3的卷积核张量W0卷积的结果是一个3×3的矩阵。由于我们有两个卷积核W0和W1,因此最后卷积的结果是两个3×3的矩阵。或者说卷积的结果是一个3x3x2的张量。 仔细回味下卷积的过程,输入是7x7x3的张量,卷积核是两个3x3x3的张量。卷积步幅为2,最后得到了输出是3x3x2的张量。如果把上面的卷积过程用数学公式表达出来就是:

5. CNN模型结构小结
理解了CNN模型中的卷积层和池化层,就基本理解了CNN的基本原理,后面再去理解CNN模型的前向传播算法和反向传播算法就容易了。下一篇我们就来讨论CNN模型的前向传播算法。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
3) UFLDL Tutorial
4)CS231n Convolutional Neural Networks for Visual Recognition, Stanford
,
在前面我们讲述了DNN的模型与前向反向传播算法。而在DNN大类中,卷积神经网络(Convolutional Neural Networks,以下简称CNN)是最为成功的DNN特例之一。CNN广泛的应用于图像识别,当然现在也应用于NLP等其他领域,本文我们就对CNN的模型结构做一个总结。
在学习CNN前,推荐大家先学习DNN的知识。如果不熟悉DNN而去直接学习CNN,难度会比较的大。这是我写的DNN的教程:
深度神经网络(DNN)模型与前向传播算法
深度神经网络(DNN)反向传播算法(BP)
深度神经网络(DNN)损失函数和激活函数的选择
深度神经网络(DNN)的正则化
1. CNN的基本结构
首先我们来看看CNN的基本结构。一个常见的CNN例子如下图:

图中是一个图形识别的CNN模型。可以看出最左边的船的图像就是我们的输入层,计算机理解为输入若干个矩阵,这点和DNN基本相同。
接着是卷积层(Convolution Layer),这个是CNN特有的,我们后面专门来讲。卷积层的激活函数使用的是ReLU。我们在DNN中介绍过ReLU的激活函数,它其实很简单,就是
最终我们得到卷积输出的矩阵为一个2×3的矩阵S。
再举一个动态的卷积过程的例子如下:
我们有下面这个绿色的5×5输入矩阵,卷积核是一个下面这个黄色的3×3的矩阵。卷积的步幅是一个像素。则卷积的过程如下面的动图。卷积的结果是一个3×3的矩阵。



上面举的例子都是二维的输入,卷积的过程比较简单,那么如果输入是多维的呢?比如在前面一组卷积层+池化层的输出是3个矩阵,这3个矩阵作为输入呢,那么我们怎么去卷积呢?又比如输入的是对应RGB的彩色图像,即是三个分布对应R,G和B的矩阵呢?
在斯坦福大学的cs231n的课程上,有一个动态的例子,链接在这。建议大家对照着例子中的动图看下面的讲解。
大家打开这个例子可以看到,这里面输入是3个7×7的矩阵。实际上原输入是3个5×5的矩阵。只是在原来的输入周围加上了1的padding,即将周围都填充一圈的0,变成了3个7×7的矩阵。 例子里面使用了两个卷积核,我们先关注于卷积核W0。和上面的例子相比,由于输入是3个7×7的矩阵,或者说是7x7x3的张量,则我们对应的卷积核W0也必须最后一维是3的张量,这里卷积核W0的单个子矩阵维度为3×3。那么卷积核W0实际上是一个3x3x3的张量。同时和上面的例子比,这里的步幅为2,也就是每次卷积后会移动2个像素的位置。 最终的卷积过程和上面的2维矩阵类似,上面是矩阵的卷积,即两个矩阵对应位置的元素相乘后相加。这里是张量的卷积,即两个张量的3个子矩阵卷积后,再把卷积的结果相加后再加上偏倚b。 7x7x3的张量和3x3x3的卷积核张量W0卷积的结果是一个3×3的矩阵。由于我们有两个卷积核W0和W1,因此最后卷积的结果是两个3×3的矩阵。或者说卷积的结果是一个3x3x2的张量。 仔细回味下卷积的过程,输入是7x7x3的张量,卷积核是两个3x3x3的张量。卷积步幅为2,最后得到了输出是3x3x2的张量。如果把上面的卷积过程用数学公式表达出来就是:
5. CNN模型结构小结
理解了CNN模型中的卷积层和池化层,就基本理解了CNN的基本原理,后面再去理解CNN模型的前向传播算法和反向传播算法就容易了。下一篇我们就来讨论CNN模型的前向传播算法。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
3) UFLDL Tutorial
4)CS231n Convolutional Neural Networks for Visual Recognition, Stanford


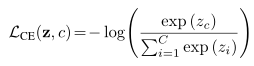










 京公网安备 11010802041100号
京公网安备 11010802041100号