Flume使用大全之kafkasource-kafkachannel-hdfs
作者:鱼和鱼还有鱼3_Mh_qet | 来源:互联网 | 2023-10-12 19:46
agent.sourceskafkaSource1agent.channelskafkaChannelagent.sinkshdfsSinkagent.sources.kafkaSo
agent.sources = kafkaSource1
agent.channels = kafkaChannel
agent.sinks = hdfsSink
agent.sources.kafkaSource1.channels = kafkaChannel
agent.sinks.hdfsSink.channel = kafkaChannel
agent.sources.kafkaSource1.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafkaSource1.zookeeperCOnnect= node1:2181
agent.sources.kafkaSource1.topic = bpu_sensor_router,bpu_sensor_record_present,bpu_group_status_present,bpu_gateway_heartbeat,bpu_gateway_router,bpu_sensor_heartbeat
agent.sources.kafkaSource1.consumer.group.id = flume
agent.sources.kafkaSource1.kafka.consumer.timeout.ms = 100
agent.sources.kafkaSource1.kafka.bootstrap.servers = node7:9092
agent.sources.kafkaSource1.batchSize = 100
agent.sources.kafkaSource1.batchDuratiOnMillis= 1000
agent.channels.kafkaChannel.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.kafkaChannel.kafka.bootstrap.servers = node7:9092
agent.channels.kafkaChannel.kafka.topic = flume-kafkaChannel
agent.channels.kafkaChannel.consumer.group.id = flume-consumer
#---------hdfsSink 相关配置------------------
agent.sinks.hdfsSink.type = hdfs
# 注意, 我们输出到下面一个子文件夹data中
agent.sinks.hdfsSink.hdfs.path = hdfs://nameservice1/user/hive/warehouse/%{topic}/%Y/%m/%d
agent.sinks.hdfsSink.hdfs.writeFormat = TEXT
agent.sinks.hdfsSink.hdfs.fileType = DataStream
agent.sinks.hdfsSink.hdfs.rollSize = 128000000
agent.sinks.hdfsSink.hdfs.rollInterval=60
agent.sinks.hdfsSink.hdfs.rollCount = 0
agent.sinks.hdfsSink.hdfs.batchSize = 100
agent.sinks.hdfsSink.hdfs.batchDuratiOnMillis= 1000
agent.sinks.hdfsSink.hdfs.round = true
agent.sinks.hdfsSink.hdfs.roundUnit = day
agent.sinks.hdfsSink.hdfs.roundValue = 1
agent.sinks.hdfsSink.hdfs.threadsPoolSize = 25
agent.sinks.hdfsSink.hdfs.useLocalTimeStamp = true
agent.sinks.hdfsSink.hdfs.minBlockReplicas = 1
agent.sinks.hdfsSink.hdfs.idleTimeout = 30
agent.sinks.hdfsSink.hdfs.filePrefix= %{topic}
推荐阅读
-
软件环境Hadoop:2.7,3.1(sincev2.5)Hive:0.13-1.2.1HBase:1.1,2.0(sincev2.5)Spark(optional)2.3.0K ...
[详细]
蜡笔小新 2023-10-16 16:09:42
-
一、什么是Lambda架构Lambda架构由Storm的作者[NathanMarz]提出,根据维基百科的定义,Lambda架构的设计是为了在处理大规模数 ...
[详细]
蜡笔小新 2023-10-17 16:06:09
-
-
ConsumerConfiguration在kafka0.9使用JavaConsumer替代了老版本的scalaConsumer。新版的配置如下:bootstrap. ...
[详细]
蜡笔小新 2023-10-16 10:44:59
-
本文由编程笔记#小编为大家整理,主要介绍了logistic回归(线性和非线性)相关的知识,包括线性logistic回归的代码和数据集的分布情况。希望对你有一定的参考价值。 ...
[详细]
蜡笔小新 2023-12-14 21:40:43
-
像不少公司内部不同团队都会自己研发自己工具产品,当各个产品逐渐成熟,到达了一定的发展瓶颈,同时每个产品都有着自己的入口,用户 ...
[详细]
蜡笔小新 2023-12-13 15:19:01
-
一、集群间数据拷贝scp实现两个远程主机之间的文件复制scp-rhello.txtroothadoop103:useratguiguhello.txt推pushscp-rr ...
[详细]
蜡笔小新 2023-12-13 13:52:40
-
FeatureRequestIsyourfeaturerequestrelatedtoaproblem?Please ...
[详细]
蜡笔小新 2023-12-13 11:52:05
-
本文介绍了在SQL Server中进行REVERT权限切换的操作步骤和注意事项。首先登录到SQL Server,其中包括一个具有很小权限的普通用户和一个系统管理员角色中的成员。然后通过添加Windows登录到SQL Server,并将其添加到AdventureWorks数据库中的用户列表中。最后通过REVERT命令切换权限。在操作过程中需要注意的是,确保登录名和数据库名的正确性,并遵循安全措施,以防止权限泄露和数据损坏。 ...
[详细]
蜡笔小新 2023-12-10 19:41:02
-
近期,某用户在重启RAC一个节点的数据库实例时,发现启动速度非常慢。同时业务部门反馈连接RAC存活节点的业务也受影响。通过对日志的分析, ...
[详细]
蜡笔小新 2023-10-17 20:40:38
-
python+selenium十:基于原生selenium的二次封装fromseleniumimportwebdriverfromselenium.webdriv ...
[详细]
蜡笔小新 2023-10-17 17:28:31
-
裁剪和masking在PyCairo指南的这个部分,我么将讨论裁剪和masking操作。裁剪裁剪就是将图形的绘制限定在一定的区域内。这样做有一些效率的因素 ...
[详细]
蜡笔小新 2023-10-17 17:18:21
-
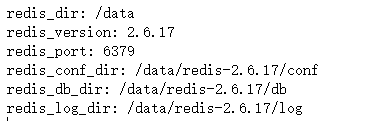
1、相关redis参数:2、templatesredis.conf配置相关参数:daemonizeyespidfilevarrunredis_{{red ...
[详细]
蜡笔小新 2023-10-17 15:59:52
-
本文目录一览:1、html网页跳转javascript代码实现 ...
[详细]
蜡笔小新 2023-10-17 15:04:31
-
动态多点是一个高扩展的IPSEC解决方案传统的ipsecS2S有如下劣势1.中心站点配置量大,无论是采用经典ipsec***还是采用greoveripsec多一个分支 ...
[详细]
蜡笔小新 2023-10-17 09:16:50
-
本文是学习Java多线程与高并发知识时做的笔记。这部分内容比较多,按照内容分为5个部分:多线程基础篇JUC篇同步容器和并发容器篇线程池篇MQ篇本篇 ...
[详细]
蜡笔小新 2023-10-16 11:14:01
-
鱼和鱼还有鱼3_Mh_qet
这个家伙很懒,什么也没留下!





![[翻译]PyCairo指南裁剪和masking](https://img6.php1.cn/3cdc5/9d74/696/ff5f2ae0c65cf286.jpeg)


 京公网安备 11010802041100号
京公网安备 11010802041100号