题注:
在 eggjs 团队的日常协作中,深度依赖于「基于 GitLab 的一站式硬盘式异步协作模式」。
本文作为相关介绍文章第一篇引子,转自阿里内部,已获作者 @晚学 授权。原文标题:「我是这样开始用 Git 的」
前言
如果这篇文章以 「Git 好用到没朋友,甩 svn 十条长安街」的基调开始,中间插上一大段从网上抄来的、已经被转载得满地球都是的、看着特有道理但自己看完却完全没感觉的文字,末了结尾处高喊 Git 我爱你并且自作多情的留下 6 个亢奋的感叹号的话(吁……先喘口气),那么,这篇文章肯定收了钱了。
我们以码字为生的文字工作者最重要的精神就是:冷静并客观。
所以今天,我们就冷静并客观的来看看 svn 和 Git,看 Git 是不是后生可畏,看 svn 是不是老当益壮。
入门总是伴随着惨不忍睹
可能大部分人跟我的经历是一样的,最先接触到的 VCS(version control system)是 svn ,然后为了不被人家说土,开始尝试认识 Git。
如果把 svn 和 Git 比作朋友的话,他俩可谓性格都非常分明,svn 是个直肠子,简单直接,从不绕弯弯,svn 命令语义非常清楚,如果你不是高级 SCM ,你只要学会:
svn checkout
svn update
svn commit
svn revert
概你就能够和别人进行协作开发了,你看,多简单。
但 Git 不一样,他可不是个随和的朋友,他比 svn 有个性太多了,相信大部分开始学习 Git 的人都曾经被这句话搞到怀疑自己的智商以至放弃 Git – Git 是一个分布式的版本管理系统。
一开始你感觉是这样的:我勒个去,分布式,很高端啊,哥得看看。
看了半天,你心里打鼓了:矮油我去,看了半天命令有点蒙圈,不过还是能够清醒的认识到自己完全没理解 「分布式」这三个字用在 Git 里面是个什么意思的。
再回过头去看看 Git 命令,你会坚定的认为代码的归宿就应该是 svn,Git 搞那么复杂是在秀智商么?滚蛋,一边玩去。
但是当你听到外面有人不断的说:“Git 太特么好用了,简直神器” 之类话,你又开始怀疑自己:是我太笨还是这个世界太荒唐?
我就是这么一路走过来的。
实际上…
实际上,svn 和 Git 只是两个不同的东西而已,Git 没有比 svn 好到天翻地覆,svn 也没有人们嘴里说的那么不堪。
作为工具来讲他俩都专注的做一件事情:版本控制。最大的差别就是这个所谓的 「分布式」,那么这个分布式到底是个什么鬼?
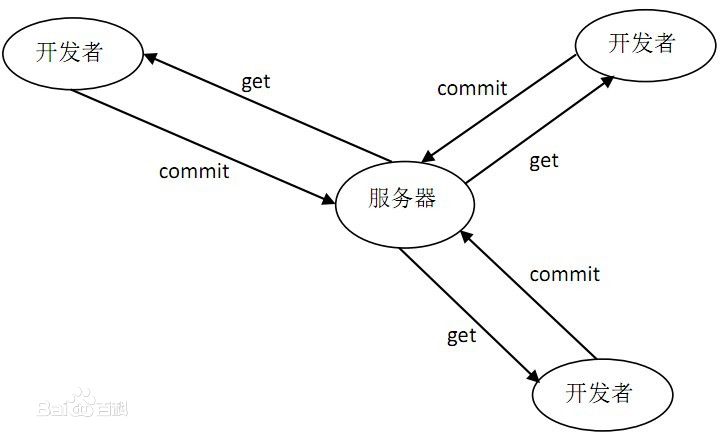
svn 的架构我们都很熟悉了,经典 CS 架构:某个地方 run 着一个 svn server,上面存放着很多代码仓库,所有人通过 svn client 和 svn server 进行交互:拉取代码、提交代码、更新代码。一切都是那么的自然。
Git 号称分布式的意思是说 “在某个地方 run 着很多 git server ” 么?如果是这样的,好像也没什么稀奇的呀,相信 svn 也能做到。
实际上……所谓 Git 分布式版本控制和 svn 传统版本控制的区别是这样的:
差别就是 Git 在你本地多做了一次版本控制,相当于在你本地有一个 svn 服务器,远端还有一个 svn 服务器,那么为什么要这么做呢?原来 svn 那种直观的模式不是挺好的么?
实际上……原因很简单,我们来看一个故事,这样的场景每天都在上演:
有一个项目,需要 10 个人一起协作完成。
v0.0.1 的时候:大家用 svn ,新建了一个叫 XX-v-0.0.1
的仓库,所有人都往这个代码仓库里面提交代码,久而久之大家发现,别人提交的老是会影响到自己(就是冲突啦),自己提交的也会影响到别人,人数越多这个影响就会被放的越大,甚至有时候由于一个人的失误提交导致大家都没法工作了,如果这种“失误”每天多发生几次,基本上就没什么心情写代码了。
v0.0.2 的时候:大家开始总结经验,不能这么搞了,所有人从 XX-v-0.0.2
的代码仓库上创建一个自己的分支,自己开发,然后每天我们找个时间坐在一起,一个一个的把自己的分支合并到 XX-v-0.0.2
上面。这种做法某种程度上缓解了 0.0.1 版本的时候遇到的问题,其实就是把冲突的频率降下去了而已,实质跟 0.0.1
的做法没有任何区别。(试想一下假如还是在同一个分支上,大家约定都不提交,每天找个时间坐在一起一个一个的提交,是不是效果一样一样的?前者唯一的好处就是自己的代码起码有个版本库管着,不至于本地丢了就全没了;但是前者一个典型的坏处就是到合并的时候如果差异特别大的话合并起来就会相当困难,甚至完全没法合并。)
0.0.1 的做法是高频冲突概率,但是每次冲突的解决成本相对较小
0.0.2 的做法是低频冲突概率,但是每次冲突解决的成本相对较高
没法玩了么?
述情况的排列组合里面有这么一个看起来最优的组合:如果我能做到冲突的频率很低,并且冲突解决的成本也低,那岂不是达到了一个比较完美的状态?
要想做到 「冲突频率低」,那么只能限制提交的频率,怎么限制?如果都在一个分支上搞,你总不能发个红头文件限制每个人每天提交的次数吧?那就在各自分支上搞呗!提交的次数我不能限制,合并的次数我还是可控的吧?搞定!所以结论是用分支分开搞比大家搅在一起搞要好。
要想做到 「解决冲突成本低」,怎么搞?顺着上面的分支开发思路,要想成本低那就得经常合并啊?三个和尚就没水吃了,更何况是十个程序员,怎么约定谁先合并谁后合并?
干脆我们找一个人专门来做合并,这个人就是 SCM ,SCM 每天就合并代码玩儿,第一个把 A 分支的代码合并进主干,问题不大,第二个把 B 分支合并进来,稍微有点费劲(因为差异变大了,可能会有冲突),第三个把 C 分支的代码合并进来,比较费劲(差异又增大了,冲突会增多),第四个把 D 分支的代码合并进来,就很困难了,第五个把 E 分支的代码合并进来…. SCM 离职不干了。
这是一个悲惨的笨 SCM 的故事。
后来来了个聪明的 SCM ,他合并完A分支之后,告诉剩下的 9 个分支 owner :
你们把主干代码和自己的代码先合并一下,谁先合并完谁先找我,我优先帮他合并进主干。
于是聪明 SCM 把以前笨 SCM 自己干的活儿分到了 9 个人头上,显然轻松了许多。但是程序员不乐意了:
凭啥写代码的也是老子,合并的也是老子,你知道合并有多麻烦么,先 diff 俩分支,拿到 diff 文件,再 patch 到我自己的分支上,解决完冲突连厕所都不敢上赶紧一路小跑跑去找你 SCM 大人,我特么累不累啊!!
聪明 SCM 说:
大哥你别急,你们忙我也没闲着,我做了一个工具,特意取了个名字叫 Git,洋气吧?你只要运行一个命令(git rebase 主干)就自动把主干代码合并到你的分支上去了,有冲突就解决,没冲突最好。
到这个时候为止,虽然不能说皆大欢喜,至少我们的目的达到了:
但是,不优雅。
有人都建分支搞,搞得 svn 上一坨一坨的分支,眼花缭乱的乱死了,这不是增加我的工作量么,其实这个分支对于开发者来讲,就是用于版本控制的,你放在你自己本地不行么?当你要合并的时候你再把这个分支给我,这样咱们公司的版本库 server 上不也干净么?这些临时的代码分支不要留在上面,多碍事。那么怎么放在本地呢?很简单啊,你自己在本地搭一个 svn server ,你自己的分支就在自己本地搞,你自己专属的 svn 服务器随便怎么搞都无所谓,然后等你要提交上来给我合并的时候,你再把这个分支提交到公司的 svn server 上来,别担心,还记得我那个洋气的工具么? Git !我又给他加了一个功能,帮你区分提交到不同的服务器,你看啊,你提交你自己本地的,我叫做 git commit ,你把你本地的提交给我的,我叫做 git push ,你看,多合理,push 就是 push 我赶紧帮你搞合并呐,为了取这名字我操碎了心呐,你说我怎么这么有才呢?
好,故事讲完了,多么自然的,“双 svn 架构” 就演变成了今天的 Git,它很好的解决了我们遇到的问题:
极其方便的分支功能(而且是精明的在你本地开分支),让开发者很方便的在分支上开发,其背后的良苦用心在于借助分支帮大家 “降低冲突频率”。
极其方便的 rebase 和 merge 功能,在 “经常合并” 的思路下,既解放了 SCM ,又解放了开发者,其背后的深意实则是鼓励大家 “经常合并”。
这个时候,你应该能理解为什么大家都说 Git 洋气了吧?也大概能理解 Git 的一个历史演进过程了吧(咳咳,这个过程是我自己总结和理解的哈,反正我是这么理解的,也不知道对不对,管它呢,听起来还是能自圆其说的)
好,到这里,你估计不得不承认 Git 确实比 svn 更先进一些,不过你依然无法抵挡 svn 简单好用的诱惑,没关系,如果 Git 就此止步,那它顶多也就是个“略牛逼”的软件而已,掀不起什么风浪的。
基于 Git 有个叫 GitLab 的开源软件,已经被部署到了阿里,它才是利器。









 京公网安备 11010802041100号
京公网安备 11010802041100号