(本文是自己学习爬虫的一点笔记和感悟)
经过python的初步学习,对字符串、列表、字典、元祖、条件语句、循环语句……等概念应该已经有了整体印象,终于可以着手做一些小练习来巩固知识点,写爬虫练习再适合不过。
1. 网页基础
爬虫的本质就是从网页中获取所需的信息,对网页的知识还是要有一点了解。百度百科对HTML的定义:HTML,超文本标记语言,是一种标识性的语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字,图形、动画、声音、表格、链接等。
当然,网页并不仅仅只有HTML,它只能实现静态效果,我们经常看到的网页都还有有美化样式的CSS和实现动态效果的JavaScipt。爬虫对前端语言要求不高,能找到自己需要爬取的信息就足够了,当然有前端基础的童鞋爬虫会更顺手。![]()
![]()
![]()
上图右侧的网页就是由左侧的HTML代码实现的
2. 浏览网页的过程
比如我们平时要浏览百度,首先要在浏览器的地址栏输入“www.baidu.com”,从输入这个网页地址到浏览器显示出百度网页的内容,浏览器作为浏览的“客户端”向服务器端发送了一次请求,然后服务器再根据请求的内容作出相应的响应,将响应的数据返回到客户端,最后浏览器再把响应到的数据翻译成我们看到的网页。
人工浏览网页是对服务器发送请求,爬虫的也是发送请求,发送请求实质上是指发送请求报文的过程。请求报文包括以下四个方面:请求行、请求头、空行和请求体。本篇文章只说请求头,因为其在网络爬虫忠的作用相当重要,服务器可以对请求头进行检测来判断这次请求是人为的还是非人为的。如果一个网站有请求头反爬虫机制,那么没有添加请求头就会请求失败。
一个请求头中带有很多属性,不过最重要的属性就是User-Agent,这个属性是请求头里面必须有的,其他的属性可以根据实际情况添加。
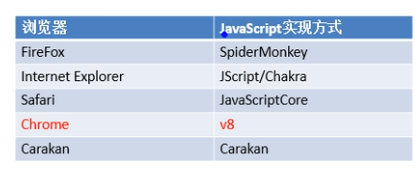
在发出请求时如果不添加请求头信息,服务器就会识别出来这次请求是网络爬虫发出的非人为发出,这时网站如果做了请求头反爬虫机制,就会导致请求失败,无法获取数据。每个浏览器都有他的User-Agent,比如chrome:![]()
在百度首页按右键,选择“检查”然后再选中network刷新网页就可以看到左侧服务器响应给浏览器的各种数据,选中其中一个在Headers下下拉就可以看到浏览器的User-Agent属性,选中复制下面的案例中可以直接用。
3.爬虫流程![]()
4. 安装requests和BeautifulSoup库
使用pip安装方式:
pip install requests
pip install BeautifulSoup4![]()
![]()
requests库有七个主要方法,最常用的就是requests.get()和requests.post()方法,入门阶段只关注requests.get()方法。
BeautifulSoup库基本用法:可以先了解soup.find()和soup.find_all()函数用法,其他先不用管。具体参考BeautifulSoup官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
(python爬虫对网页的解析方法主要有BeautifulSoup,Xpath,正则表达式等,个人觉得BeautifulSoup对新手最友好,但是在效率和速度方面比不过Xpath,毕竟Xpath是C编写的,Xpath相对也较简单可视个人情况再学习,而正则表达式学习成本较高)
5. 练习一:爬取酷狗TOP500榜曲目
主要先把爬虫的流程套路过一遍,力求简洁。练习可能需要回顾的基础知识点:format()方法;字符串切片;列表索引;strip()和split()字符串处理方法;zip()函数……如果遗忘请百度或翻之前笔记。![]()
本练习只爬取榜单里的歌手名和歌曲名,可以看到歌手名和歌曲名之间多了个“-”,爬下来后考虑使用split()方法对字符串进行处理。直接上代码:
#导入requests和BeautifulSoup库
import requests
from bs4 import BeautifulSoup
#搜狗TOP500曲目链接
url = "http://www.kugou.com/yy/rank/home/1-8888.html"
#获取所有网页信息
response = requests.get(url)
#利用.text方法提取响应的文本信息
html = r.text
#利用BS库对网页进行解析,得到解析对象soup
soup =BeautifulSoup(html,'html.parser')
利用谷歌浏览器吧鼠标放在歌名上,右击选择“检查”,很容易找到需要爬取信息的特征:![]()
看到花花绿绿的HTML代码别虚,都是纸老虎,只要能找到需要的标签信息就好,可以看到所有歌名都是在这样的标签之下:![]()
每一个这样的标签就代表一首歌名的代码。继续如下代码:
#解析出歌名,find_all()函数返回的是tag的列表
names = soup.find_all('a',class_='pc_temp_songname')
# 打印names
print(names)![]()
打印发现除了歌手名和歌曲名还有一堆不需要的符号和字母,可以考虑使用get_text()方法获取标签中的文本数据,继续:
……
#利用for循环遍历出name,再利用get_text()方法获取标签中的文本数据
for name in names:
#利用split方法把歌手和曲目分隔返回成列表形式赋值给item
item = name.get_text().split('-')
print("歌手:{} 曲名:{}".format(item[0],item[1]))
再打印出来看看:![]()
总共返回了22条,是一页榜单的数据。下个练习再讲怎么爬取榜单所有页码的数据。到这里一个mini爬虫练习就结束了。完整代码如下:![]()
总共不到十行代码,很容易上手,基本上能了解爬数据的流程。
6.练习二:爬取猫眼电影TOP100
前面都是固定套路和练习一一样,直接上代码:
#导入所需的requests和BeautifulSoup库
import requests
from bs4 import BeautifulSoup
#获取猫眼电影TOP100链接
url = 'https://maoyan.com/board/4?offset=0'
#把刚刚复制chrome的User-Agent以字典形式粘到headers中,把自己爬虫的请求伪装成chrome浏览器的请求
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
#发出请求
response = requests.get(url,headers = headers)
html = response.text
#利用BS库对网页进行解析,得到解析对象soup
soup = BeautifulSoup(html,'html.parser')![]()
打开猫眼TOP100网页,准备对电影的排名,名字,主演,上映时间,和评分五个字段进行爬取,首先对网页进行分析,右击鼠标选中检查,如下:![]()
可以发现电影排名都是在如下标签中的:
2
继续寻找包含电影名字的标签:![]()
可以发现电影名称包含在如下标签中:
霸王别姬
包含电影名称的标签‘a’是‘p’的子标签,只需要抓取‘p’标签就可以利用get_text()方法抓取到标签中的文本信息。同样的可以找到包含其他要爬取的字段标签,包含主演内容的标签:
主演:张国荣,张丰毅,巩俐
可以看到文本部分有空格,到时候用strip()函数清除空格。包含上映时间和评分的标签如下:
#包含上映时间的标签
上映时间:1993-01-01
#包含评分的标签
9.5
利用bs库的find_all()可对所有符合条件的标签进行抓取:
names = soup.find_all('p',class_="name")
actors = soup.find_all('p',class_="star")
ranks = soup.find_all('i',class_="board-index")
times = soup.find_all('p',class_="releasetime")
scores = soup.find_all('p',class_="score")
这样,包含要爬取字段信息的标签就被全部获取,find_all()函数返回标签列表。可以使用for循环对返回的遍历出列表中的字段信息。不过直接遍历得到的就不是一部电影的排名、名称、主演……而是先是一堆名字,一堆排名,像这样的:![]()
这种样式和我们想象的不一样,需要将一部电影的各个字段信息在一行显示就需要zip()函数来实现:
for rk,ne,ar,te,se in zip(ranks,names,actors,times,scores):
#对字符串进行简单清洗
rank = rk.get_text()
name = ne.get_text().strip()
actor = ar.get_text().strip()[3:]
time = te.get_text()[5:]
score = se.get_text()
print('{} {} {} {} {}'.format(rank,name,actor,time,score))
这样就可以得到第一页10个电影的各项信息。但我们还想获取剩余九页的内容,可以先对每一页的URL进行分析:
第一页:https://maoyan.com/board/4?offset=0
……
可以发现只有offset后面的参数是有变化的其他部分不变,网页翻页由这个参数控制而且这个参数的规律是以零为首项,公差为10的等差数列,我们可以想到用for循环语句来遍历实现对十页内容的爬取。代码如下:
for i in range(10):
url = 'https://maoyan.com/board/4?offset={}'.format(i*10)
这样,100条电影的五个字段信息都就爬取下来了。结果如下:![]()
完整代码如下:![]()
到这里,需要的数据就全部爬取成功,接下来可以进一步学习爬取数据的存储以及与SQL数据库的连接,为后面的数据分析做准备。











 京公网安备 11010802041100号
京公网安备 11010802041100号