
Spark读取parquet数据源
1.Parquet文件介绍
Apache Parquet是Hadoop生态圈中一种新型的列式存储格式,它可以兼容Hadoop生态圈中大多数据的计算框架,如Hadoop, Spark,它也被多种查询引擎所支持,例如Hive, Impala等,而且它是跨语言和平台的。
Parquet的产生是由Twitter和Cloudera公司由于Apache Impala的缘故使用开发完成并开源给Apache基金会组织进行孵化,现已成为APache的顶级项目。
另一方面,随着嵌套格式数据的需求日益增加,目前Hadoop生态圈中主流的OLAP都支持丰富的数据类型,例如Hive, SparkSQL, Impala等都支持诸如array, map, struct这样的复合数据类型,这也使得像Parquet这种原生支持嵌套数据的存储格式变得至关重要,由于它是列式存储,所以在性能方面会很高。
列式存储,就是按照列进行存储数据,把某一旬的数据连续地存储,每一行中的不同的列离散分布。相比较于行存储,列存储具有以下优势:
- 可以跳过不符合条件的数据,只读取需要的数据,降低磁盘IO
- 使用压缩可以降低磁盘的存储空间,并且由于同一列的数据类型是一样的,可以使用更高效的压缩编码进一步节约存储空间;
- 只读取需要的列,能够获得更好的扫描性能;
Parquet是SparkSQL默认的存储格式,它支持灵活的读写Parquet文件,并对Parquet文件的schema可以自动解析。
import org.apache.spark.sql.{DataFrame, SparkSession}object SparkSqlParquetSource { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(SparkSqlParquetSource.getClass.getSimpleName) .master("local") .getOrCreate() spark.sparkContext.setLogLevel("WARN") //读取json文件生成DataFrame val sanguoDF: DataFrame = spark.read.format("json").load("./dataset/sanguo.json") //把结果写入parquet sanguoDF.write.parquet("./dataset/parquet/sanguo.parquet") /** * 读取刚刚写入的parquet文件 * */ val sgDF: DataFrame = spark.read.parquet("./dataset/parquet/sanguo.parquet") //打印schema sgDF.printSchema() sgDF.show() //释放资源 spark.stop() }}
上述代码中,通过读取json文件写入parquet文件:
.crc是校验文件,数据生成的parquet文件是用snappy压缩的
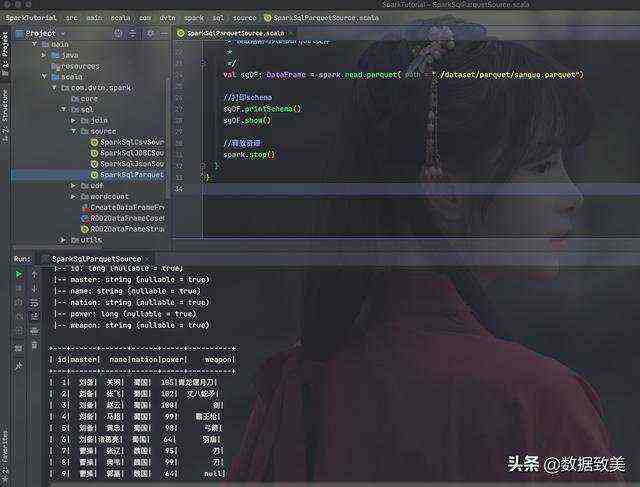
运行的结果
2.分区发现(Partition Discovery)
表分区是一种常见的优化方法,比如Hive中就提供了分区表的特性。在一个分区表中,不同分区的数据通常是存储在HDFS上不同的目录中,分区列的值通常就包含在了分区目录的目录名中。SparkSQL中的parquet数据源,支持自动根据目录名推断出分区信息。例如,如果将人口数据存储在分区表中,并且使用性别和国家作为分区列。那么目录结构可能如下所示:
path└── to └── table ├── gender=male │ ├── ... │ │ │ ├── country=US │ │ └── data.parquet │ ├── country=CN │ │ └── data.parquet │ └── ... └── gender=female ├── ... │ ├── country=US │ └── data.parquet ├── country=CN │ └── data.parquet └── ...
如果将 path/to/table传入SparkSession.read.parquet()或SparkSession.read.load()方法,那么SparkSQL就会自动根据目录的结构,推断出分区信息是gender和country。即使数据文件中只包含了两列值,name和age,但是Spark SQL返回的DataFrame,调用printSchema()方法时,会打印出四个列的值:name,age,country,gender。这就是自动分区推断的功能。
此外,分区列的数据类型,也是自动被推断出来的。目前,Spark SQL仅支持自动推断出数字类型和字符串类型。有时,用户也许不希望Spark SQL自动推断分区列的数据类型。此时只要设置一个配置即可, spark.sql.sources.partitionColumnTypeInference.enabled,默认为true,即自动推断分区列的类型,设置为false,即不会自动推断类型。禁止自动推断分区列的类型时,所有分区列的类型,就统一默认都是String。
3.元数据合并(Schema Merging)
如同ProtocolBuffer,Avro,Thrift一样,Parquet也是支持元数据合并的。用户可以在一开始就定义一个简单的元数据,然后随着业务需要,逐渐往元数据中添加更多的列。在这种情况下,用户可能会创建多个Parquet文件,有着多个不同的但是却互相兼容的元数据。Parquet数据源支持自动推断出这种情况,并且进行多个Parquet文件的元数据的合并。
因为元数据合并是一种相对耗时的操作,而且在大多数情况下不是一种必要的特性,从Spark 1.5.0版本开始,默认是关闭Parquet文件的自动合并元数据的特性的。可以通过以下两种方式开启Parquet数据源的自动合并元数据的特性:
- 读取Parquet文件时,将数据源的选项,mergeSchema,设置为true
- 将spark.sql.parquet.mergeSchema参数设置为true
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}object SparkSqlSchemaMergeTest { def main(args: Array[String]): Unit = { val spark: SparkSession= SparkSession.builder() .master("local") .appName(SparkSqlSchemaMergeTest.getClass.getSimpleName) .getOrCreate() spark.sparkContext.setLogLevel("WARN") //导入隐式转换 import spark.implicits._ //创建第一个DataFrame val personSeq: Seq[(String, Int)] = Array(("风清扬", 55), ("任我行", 60)).toSeq val personDF: DataFrame = spark.createDataset(personSeq).toDF("name", "age")// personDF.printSchema()// personDF.show() //保存第一个DF到parquet文件 personDF.write.mode(SaveMode.Append).parquet("./dataset/parquet/person.parquet") //创建第二个DataFrame val personWithGenderSeq: Seq[(String, String)] = Array(("关羽", "男"), ("张飞", "男")).toSeq val personWithGenderDF: DataFrame = spark.createDataset(personWithGenderSeq).toDF("name", "gender") //保存第二个DF到parquet文件 personWithGenderDF.write.mode(SaveMode.Append).parquet("./dataset/parquet/person.parquet") /** * 首先,第一个DataFrame和第二个DataFrame的元数据是肯定不一样的 * 一个是包含了name和age, 而别一个是包含了name和gender * 所以,期望将来读取这个parquet文件时只有三列name, age, gender, 实现自动合并元数据的功能 * */ //用mergeSchema的方式,读取person.parquet文件中的数据,并将元数据合并 val mergedPerosnDF: DataFrame = spark.read.format("parquet").option("mergeSchema", "true").load("./dataset/parquet/person.parquet") //打印合并的schema的信息 mergedPerosnDF.printSchema() mergedPerosnDF.show() spark.stop() }}
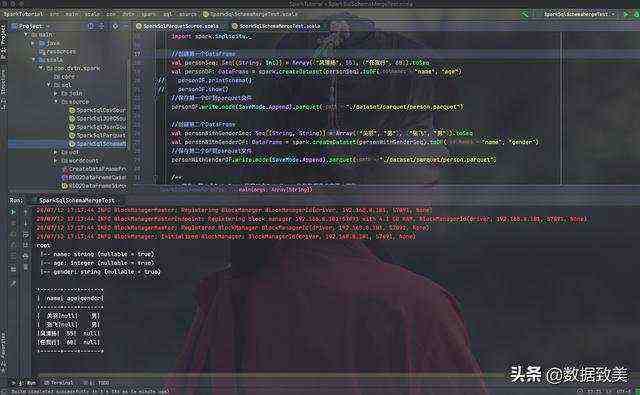
代码实现截图
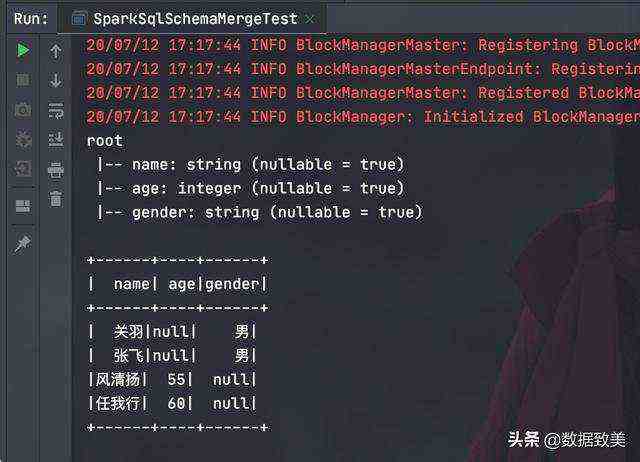
运行结果可以看出进行了schema的合并









 京公网安备 11010802041100号
京公网安备 11010802041100号