主要内容
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式的全文搜索引擎,其对外服务是基于RESTful web接口发布的。Elasticsearch是用Java开发的应用,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
1. 相关概念
1.1 cluster
集群。ElasticSearch集群由一或多个节点组成,其中有一个主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部看ElasticSearch集群,在逻辑上是个整体,你与集群中的任何一个节点通信和与整个ElasticSearch集群通信是等价的。也就是说,主节点的存在不会产生单点安全隐患、并发访问瓶颈等问题。
1.2 primary shard
primary shard:代表索引的主分片,ElasticSearch可以把一个完整的索引分成多个primary shard,这样的好处是可以把一个大的索引拆分成多个分片,分布存储在不同的ElasticSearch节点上,从而形成分布式存储,并为搜索访问提供分布式服务,提高并发处理能。primary shard的数量只能在索引创建时指定,并且索引创建后不能再更改primary shard数量。
1.3 replica shard
replica shard:代表索引主分片的副本,ElasticSearch可以设置多个replica shard。replica shard的作用:一是提高系统的容错性,当某个节点某个primary shard损坏或丢失时可以从副本中恢复。二是提高ElasticSearch的查询效率,ElasticSearch会自动对搜索请求进行负载均衡,将并发的搜索请求发送给合适的节点,增强并发处理能力。
1.4 Index
索引。相当于关系型数据库中的表。其中存储若干相似结构的Document数据。如:客户索引,订单索引,商品索引等。ElasticSearch中的索引不像数据库表格一样有强制的数据结构约束,在理论上,可以存储任意结构的数据。但了为更好的为业务提供搜索数据支撑,还是要设计合适的索引体系来存储不同的数据。
1.5 Type
类型。每个索引中都必须有唯一的一个Type,Type是Index中的一个逻辑分类。ElasticSearch中的数据Document是存储在索引下的Type中的。
注意:ElasticSearch5.x及更低版本中,一个Index中可以有多个Type。ElasticSearch6.x版本之后,type概念被弱化,一个index中只能有唯一的一个type。且在7.x版本之后,删除type定义。
1.6 Document
文档。ElasticSearch中的最小数据单元。一个Document就是一条数据,一般使用JSON数据结构表示。每个Index下的Type中都可以存储多个Document。一个Document中可定义多个field,field就是数据字段。如:学生数据({"name":"张三", "age":20, "gender":"男"})。
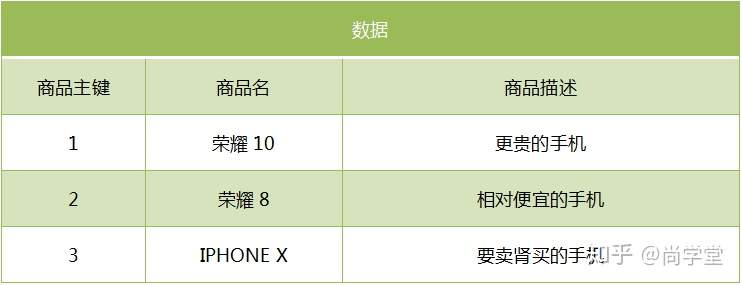
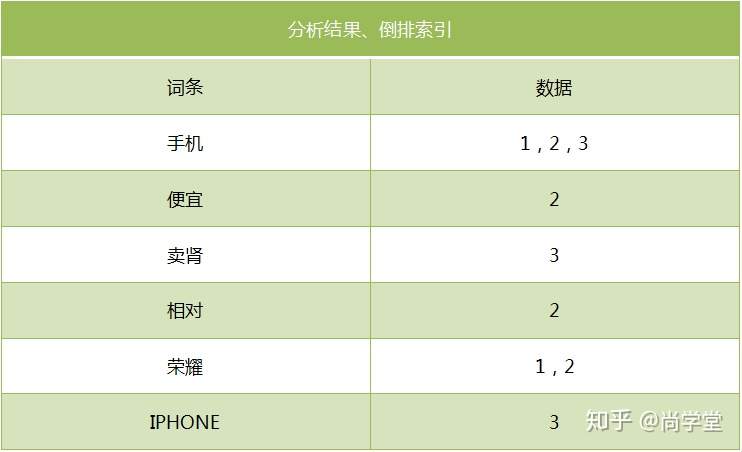
1.7 反向索引|倒排索引
对数据进行分析,抽取出数据中的词条,以词条作为key,对应数据的存储位置作为value,实现索引的存储。这种索引称为倒排索引。倒排索引是Document写入ElasticSearch时分析维护的。
如:
2. ElasticSearch常见使用场景
维基百科:全文检索,高亮显示,搜索推荐
The Guardian(国外的一个新闻网站),此平台可以对用户的行为(点击、浏览、收藏、评论)、社区网络数据(对新闻的评论等)进行数据分析,为新闻的发布者提供相关的公众反馈。
Stack Overflow(国外的程序异常讨论论坛)
Github(开源代码管理),在千亿级别的代码行中搜索信息
电子商务平台等。
3. 为什么不用数据库做搜索?
3.1 查询语法复杂度高。
如:电商系统中搜索商品数据 - select * from products where name like '%关键字%' and price bewteen xxx and yyy and ......。不同的用户提供的查询条件不同,需要提供的动态SQL过于复杂。
3.2 关键字索引不全面,搜索结果不符合要求
如:电商系统中查询商品数据,条件为商品名包含'笔记本电脑'。那么对此关键字的分析结果为-笔记本、电脑、笔记等。对应的查询语法应该为 - select * from products where name like '%笔记本%' or name like '%电脑%' .......
3.3 效率问题
数据量越大,查询反应效率越低。
使用的ElasticSearch的版本是6.8.4。ElasticSearch6.x要求Linux内核必须是3.5+版本以上。
在linux操作系统中,查看内核版本的命令是: uname -a
课堂使用的Linux是CentOS8。内核使用的是4.4。
ElasticSearch6.X版本要求JDK版本至少是1.8.0_131。 提供1.8.0_161JDK安装包。
1. 为ElasticSearch提供完善的系统配置
ElasticSearch在Linux中安装部署的时候,需要系统为其提供若干系统配置。如:应用可启动的线程数、应用可以在系统中划分的虚拟内存、应用可以最多创建多少文件等。
1.1 修改限制信息
vi /etc/security/limits.conf
是修改系统中允许应用最多创建多少文件等的限制权限。Linux默认来说,一般限制应用最多创建的文件是65535个。但是ElasticSearch至少需要65536的文件创建权限。修改后的内容为:
* soft nofile 65536
* hard nofile 65536
1.2 修改线程开启限制
在CentOS6.5版本中编辑下述的配置文件
vi /etc/security/limits.d/90-nproc.conf
在CentOS7+版本中编辑配置文件是:
vi /etc/security/limits.conf
是修改系统中允许用户启动的进程开启多少个线程。默认的Linux限制root用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024个线程。必须修改限制数为4096+。因为ElasticSearch至少需要4096的线程池预备。ElasticSearch在5.x版本之后,强制要求在linux中不能使用root用户启动ElasticSearch进程。所以必须使用其他用户启动ElasticSearch进程才可以。
* soft nproc 4096
root soft nproc unlimited
注意:Linux低版本内核为线程分配的内存是128K。4.x版本的内核分配的内存更大。如果虚拟机的内存是1G,最多只能开启3000+个线程数。至少为虚拟机分配1.5G以上的内存。
1.3 修改系统控制权限
CentOS6.5中的配置文件为:
vi /etc/sysctl.conf
CentOS8中的配置文件为:
vi /etc/sysctl.d/99-sysctl.conf
系统控制文件是管理系统中的各种资源控制的配置文件。ElasticSearch需要开辟一个65536字节以上空间的虚拟内存。Linux默认不允许任何用户和应用直接开辟虚拟内存。
新增内容为:
vm.max_map_count=655360
使用命令: sysctl -p 。 让系统控制权限配置生效。
2. 安装ElasticSearch
ElasticSearch是java开发的应用。在6.8.4版本中,要求JDK至少是1.8.0_131版本以上。
ElasticSearch的安装过程非常简单。解压立刻可以使用。
2.1 解压缩安装压缩包
tar -zxf elasticsearch-6.8.4.tar.gz
2.2 移动ElasticSearch
mv elasticsearch-6.8.4 /usr/local/es/
2.3 修改ElasticSearch应用的所有者
因为ElasticSearch不允许root用户启动,而课堂案例中,ElasticSearch是root用户解压缩的。所以解压后的ElasticSearch应用属于root用户。所以我们需要将ElasticSearch应用的所有者修改为其他用户。当前课堂案例中虚拟机Linux内有bjsxt这个用户。
chown -R bjsxt.bjsxt /usr/local/es
2.4 切换用户
su bjsxt
2.5 修改配置
修改config/elasticsearch的配置文件,设置可访问的客户端。0.0.0.0代表任意客户端访问。
vi config/elasticsearch.yml
增加下述内容:
network.host: 0.0.0.0
2.6 启动
/usr/local/es/bin/elasticsearch
关闭: ctrl + c
/usr/local/es/bin/elasticsearch -d
关闭:
jps 命令查看ElasticSearch线程的编号
kill -9 ElasticSearch线程编号
2.7 测试连接
curl http://localhost:9200
返回如下结果:
{
"name" : "L6WdN7y",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "s7_GSd9YQnaH10VQBKCQ5w",
"version" : {
"number" : "6.3.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "eb782d0",
"build_date" : "2018-06-29T21:59:26.107521Z",
"build_snapshot" : false,
"lucene_version" : "7.3.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3. 搭建集群
修改配置文件$elasticsearch_home/config/elasticsearch.yml
增加配置:
# 发现的节点IP
discovery.zen.ping.unicast.hosts: ["ip1", "ip2"]
# 最小集群数:常用计算公式 - 总数/2 + 1
discovery.zen.minimum_master_nodes: min_nodes_count
4. 安装Kibana
Kibana是一个基于WEB的ElasticSearch管理控制台。现阶段安装Kibana主要是为了方便学习。
在Linux中安装Kibana很方便。解压,启动即可。Kibana要求的环境配置是小于ElasticSearch的要求的。
tar -zxf kibana-6.3.1-linux-x86_64.tar.gz
修改config/kibana.yml
vi config/kibana.yml
新增内容: server.host: "0.0.0.0"
bin/kibana
访问时,使用浏览器访问http://192.168.2.119:5601/
1. 查看健康状态
GET _cat/health?v

2. 创建索引
命令语法:PUT 索引名{索引配置参数}
index名称必须是小写的,且不能以下划线'_','-','+'开头。
在ElasticSearch中,默认的创建索引的时候,会分配5个primary shard,并为每个primary shard分配一个replica shard(在ES7版本后,默认创建1个primary shard)。在ElasticSearch中,默认的限制是:如果磁盘空间不足15%的时候,不分配replica shard。如果磁盘空间不足5%的时候,不再分配任何的primary shard。ElasticSearch中对shard的分布是有要求的。ElasticSearch尽可能保证primary shard平均分布在多个节点上。Replica shard会保证不和他备份的那个primary shard分配在同一个节点上。
创建默认索引
PUT test_index1
创建索引时指定分片。
PUT test_index2
{"settings":{"number_of_shards" : 2,"number_of_replicas" : 1}
}
3. 修改索引
命令语法:PUT 索引名/_settings{索引配置参数}
注意:索引一旦创建,primary shard数量不可变化,可以改变replica shard数量。
PUT test_index2/_settings
{"number_of_replicas" : 2
}
4. 删除索引
命令语法:DELETE 索引名1[, 索引名2 ...]
DELETE test_index1
5. 查看索引信息
GET _cat/indices?v

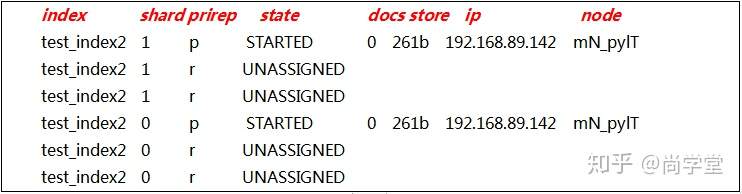
6. 检查分片信息
查看索引的shard信息。
GET _cat/shards?v
7. 新增Document
在索引中增加文档。在index中增加document。
ElasticSearch有自动识别机制。如果增加的document对应的index不存在,自动创建index;如果index存在,type不存在,则自动创建type。如果index和type都存在,则使用现有的index和type。
7.1 PUT语法
此操作为手工指定id的Document新增方式。
语法:PUT 索引名/类型名/唯一ID{字段名:字段值}
如:

结果:

如果使用PUT语法对同id的Document执行多次操作。是一种覆盖操作。如果需要ElasticSearch辅助检查PUT的Document是否已存在,可以使用强制新增语法。使用强制新增语法时,如果Document的id在ElasticSearch中已存在,则会报错。(version conflict, document already exists)
语法:
PUT 索引名/类型名/唯一ID/_create{字段名:字段值}
或
PUT 索引名/类型名/唯一ID?op_type=create{字段名:字段值}。
如:

7.2 POST语法
此操作为ElasticSearch自动生成id的新增Document方式。此语法格式和PUT请求的数据新增,只有唯一的区别,就是可以自动生成主键id,其他的和PUT请求新增数据完全一致。
语法:POST 索引名/类型名{字段名:字段值}
如:

8. 查询Document
8.1 GET ID单数据查询
语法:GET 索引名/类型名/唯一ID
如:
GET test_index/my_type/1
结果:

8.2 GET _mget批量查询
批量查询可以提高查询效率。推荐使用(相对于单数据查询来说)。
语法如下:



9 修改Document
9.1 替换Document(全量替换)
和新增的PUT|POST语法是一致。
PUT|POST 索引名/类型名/唯一ID{字段名:字段值}
本操作相当于覆盖操作。全量替换的过程中,ElasticSearch不会真的修改Document中的数据,而是标记ElasticSearch中原有的Document为deleted状态,再创建一个新的Document来存储数据,当ElasticSearch中的数据量过大时,ElasticSearch后台回收deleted状态的Document。
如:

结果:

9.2 更新Document(partial update)
语法:POST 索引名/类型名/唯一ID/_update{doc:{字段名:字段值}}
只更新某Document中的部分字段。这种更新方式也是标记原有数据为deleted状态,创建一个新的Document数据,将新的字段和未更新的原有字段组成这个新的Document,并创建。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别。
如:

结果:

10. 删除Document
ElasticSearch中执行删除操作时,ElasticSearch先标记Document为deleted状态,而不是直接物理删除。当ElasticSearch存储空间不足或工作空闲时,才会执行物理删除操作。标记为deleted状态的数据不会被查询搜索到。
语法:DELETE 索引名/类型名/唯一ID
如:

结果:

11. bulk批量增删改
使用bulk语法执行批量增删改。语法格式如下:
POST _bulk
{ "action_type" : { "metadata_name" : "metadata_value" } }
{ document datas | action datas }
语法中的action_type可选值为:
create : 强制创建,相当于PUT 索引名/类型名/唯一ID/_create
index: 普通的PUT操作,相当于创建Document或全量替换
update: 更新操作(partial update),相当于 POST 索引名/类型名/唯一ID/_update
delete: 删除操作
案例如下:

注意: bulk语法中要求一个完整的json串不能有换行。不同的json串必须使用换行分隔。多个操作中,如果有错误情况,不会影响到其他的操作,只会在批量操作返回结果中标记失败。bulk语法批量操作时,bulk request会一次性加载到内存中,如果请求数据量太大,性能反而下降(内存压力过高),需要反复尝试一个最佳的bulk request size。一般从1000~5000条数据开始尝试,逐渐增加。如果查看bulk request size的话,一般是5~15MB之间为好。
bulk语法要求json格式是为了对内存的方便管理,和尽可能降低内存的压力。如果json格式没有特殊的限制,ElasticSearch在解释bulk请求时,需要对任意格式的json进行解释处理,需要对bulk请求数据做json对象会json array对象的转化,那么内存的占用量至少翻倍,当请求量过大的时候,对内存的压力会直线上升,且需要jvm gc进程对垃圾数据做频繁回收,影响ElasticSearch效率。
生成环境中,bulk api常用。都是使用java代码实现循环操作。一般一次bulk请求,执行一种操作。如:批量新增10000条数据等。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有