很多时候我们都会对SDD硬盘进行性能测试等,不过一般为英文,而且很多专业术语,很多用户看不懂,网络上流传的硬盘测试图一般是英文版的软件界面,即便看的懂英文,也很难解释这些数据的意义,本题将为大家详细介绍这些数据的含义和测试疑虑。
硬盘测试结果分析:
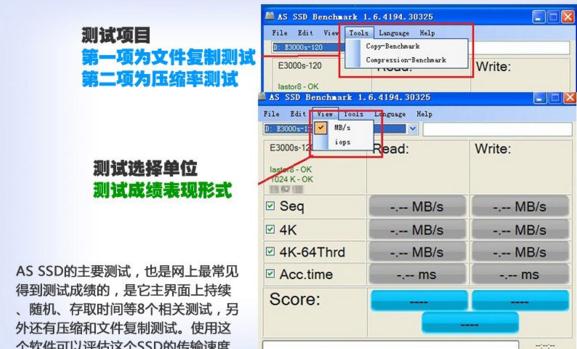
注:以金胜E3000s为例为大家解读SSD在AS SSD测试软件所代表的成绩。
金胜 E3000s-120采用了7mm超薄设计,内部构造也较为简单,PCB仅一面贴有电子元件。SSD方案为:SF2281+英特尔同步MLC,由于采用如此方案,在速度和整体性能来说,相对来说成绩比较突出。
AS SSD的主要测试,也是网上最常见得到测试成绩的,是它主界面上持续、随机、存取时间等8个相关测试,另外还有压缩和文件复制测试。使用这个软件可以评估这个SSD的传输速度好不好。
在SATA III接口上测试,读写成绩分别为:481MB/s、419MB/s。读取速度在这里表现还算正常,而持续写入会受相当多的因素影响,包括盘内剩余空间的多寡、盘内数据分布、系统节能设置等等都会对测试成绩产生显著的影响。首先是持续测试(Seq),AS SSD会先以16MB的尺寸为单位,持续向受测分区写入生成1个达到1GB大小的文件,然后再以同样的单位尺寸读取这个,最后计算平均成绩而给出结果。测试一完毕,测试文件会立刻删除。
关于随机测试,产生最多疑问的就是单队列深度的随机测试成绩,经常能见到有刚接触SSD的人会问:为什么这个项目的成绩低那么多?简单的理解,持续测试是整体跑分,而4K文件是同一时间处理一个小文件或者64个小文件。成绩当然会看起来比较低。再来是随机单队列深度测试(4K),测试软件会以512KB的单位尺寸生成1GB大小的测试文件,然后在其地址范围(LBA)内进行随机4KB单位尺寸进行写入及读取测试,直到跑遍这个范围为止,最后同样计算平均成绩给出结果。由于有生成步骤,本测试对硬盘会产生一共2GB的数据写入量。本测试完毕后,测试文件会暂时保留。
64队列深度的4KB测试,只是同时写入和读取的文件数量不同。单队列正常情况下是写入会比读取成绩高1.5倍(2倍)。而64队列深度的正常情况读写都要比持续低,如果出现相反的情况,纯属软件“抽风”,不用搭理它。到随机64队列深度测试(4K-64Thrd),软件则会生成64个16MB大小的测试文件(共计1GB),然后同时以4KB的单位尺寸,同时在这64个文件中进行写入和读取测试,最后依然以平均成绩为结果。本步骤也同样产生2GB的数据写入量。本测试一完毕,测试文件会立刻删除。
一般普通用户其实不太需要关心,只要看懂前面持续和随机的测试已经足以判断SSD有没有正常工作。如果采用桥接SATA接口数值上会比原生SATA接口高一些,和HDD相比,这个数值就能比较容易表现出SSD“快”的根本所在。接着是数据存取时间测试(Acc.time),软件会以4KB为单位尺寸,随机读取全盘地址范围(LBA),写入则以512B为单位尺寸,随机写入保留的1GB地址范围内,最后以平均成绩给出结果。
在选择IOPS作为单位,金胜这款SSD在随机测试中表现的成绩就表现非常优异。获得以上所有成绩后,AS SSD还会依据其公式计算得分,但AS SSD的分数,并没有很强的代表性,小编建议大家不需要关心。只要清楚以上8个成绩就足够了。以上主界面的几个测试,完整测一次会产生共5GB的写入量,因此无必要就建议大家不要随便跑。
文件复制测试,其中ISO测试是复制2个大文件的速度。(300MB和800MB各一)。Program测试是复制由许多小文件组成的典型程序文件夹。(最小的512B,最大的70MB)。Game测试则复制由许多小文件和较大文件混合的文件夹。(512B~数十MB都有)。这个测试其实就等同在硬盘内复制文件,处理速度越快,也说明其实际运用也能表现突出。
最后是AS SSD的压缩率测试,这个测试是针对主控使用了压缩功能的SSD而设的,通过不同可压缩比率的测试文件来获得压缩性能曲线。在没使用压缩功能的SSD上,成绩就会如上图中的那样,曲线比较平直而不是随压缩率的变化而成为弧线。SSD在写入上突然弧度变化大,可以理解为突发情况,压缩测试也会生成1GB的测试文件,所以会产生共2GB的写入量。
补充:硬盘常见故障:
一、系统不认硬盘
二、硬盘无法读写或不能辨认
三、系统无法启动 。
系统无法启动基于以下四种原因:
1. 主引导程序损坏
2. 分区表损坏
3. 分区有效位错误
4. DOS引导文件损坏
正确使用方法:
一、保持电脑工作环境清洁
二、养成正确关机的习惯
三、正确移动硬盘,注意防震
开机时硬盘无法自举,系统不认硬盘
相关阅读:固态硬盘保养技巧
一、不要使用碎片整理
碎片整理是对付机械硬盘变慢的一个好方法,但对于固态硬盘来说这完全就是一种“折磨”。
消费级固态硬盘的擦写次数是有限制,碎片整理会大大减少固态硬盘的使用寿命。其实,固态硬盘的垃圾回收机制就已经是一种很好的“磁盘整理”,再多的整理完全没必要。Windows的“磁盘整理”功能是机械硬盘时代的产物,并不适用于SSD。
除此之外,使用固态硬盘最好禁用win7的预读(Superfetch)和快速搜索(Windows Search)功能。这两个功能的实用意义不大,而禁用可以降低硬盘读写频率。
二、小分区 少分区
还是由于固态硬盘的“垃圾回收机制”。在固态硬盘上彻底删除文件,是将无效数据所在的整个区域摧毁,过程是这样的:先把区域内有效数据集中起来,转移到空闲的位置,然后把“问题区域”整个清除。
这一机制意味着,分区时不要把SSD的容量都分满。例如一块128G的固态硬盘,厂商一般会标称120G,预留了一部分空间。但如果在分区的时候只分100G,留出更多空间,固态硬盘的性能表现会更好。这些保留空间会被自动用于固态硬盘内部的优化操作,如磨损平衡、垃圾回收和坏块映射。这种做法被称之为“小分区”。
“少分区”则是另外一种概念,关系到“4k对齐”对固态硬盘的影响。一方面主流SSD容量都不是很大,分区越多意味着浪费的空间越多,另一方面分区太多容易导致分区错位,在分区边界的磁盘区域性能可能受到影响。最简单地保持“4k对齐”的方法就是用Win7自带的分区工具进行分区,这样能保证分出来的区域都是4K对齐的。
三、保留足够剩余空间
固态硬盘存储越多性能越慢。而如果某个分区长期处于使用量超过90%的状态,固态硬盘崩溃的可能性将大大增加。
所以及时清理无用的文件,设置合适的虚拟内存大小,将电影音乐等大文件存放到机械硬盘非常重要,必须让固态硬盘分区保留足够的剩余空间。
四、及时刷新固件
“固件”好比主板上的BIOS,控制固态硬盘一切内部操作,不仅直接影响固态硬盘的性能、稳定性,也会影响到寿命。优秀的固件包含先进的算法能减少固态硬盘不必要的写入,从而减少闪存芯片的磨损,维持性能的同时也延长了固态硬盘的寿命。因此及时更新官方发布的最新固件显得十分重要。不仅能提升性能和稳定性,还可以修复之前出现的bug。
五、学会使用恢复指令
固态硬盘的Trim重置指令可以把性能完全恢复到出厂状态。但不建议过多使用,因为对固态硬盘来说,每做一次Trim重置就相当于完成了一次完整的擦写操作,对磁盘寿命会有影响。
随着互联网的飞速发展,人们对数据信息的存储需求也在不断提升,现在多家存储厂商推出了自己的便携式固态硬盘,更有支持Type-C接口的移动固态硬盘和支持指纹识别的固态硬盘推出。






 京公网安备 11010802041100号
京公网安备 11010802041100号