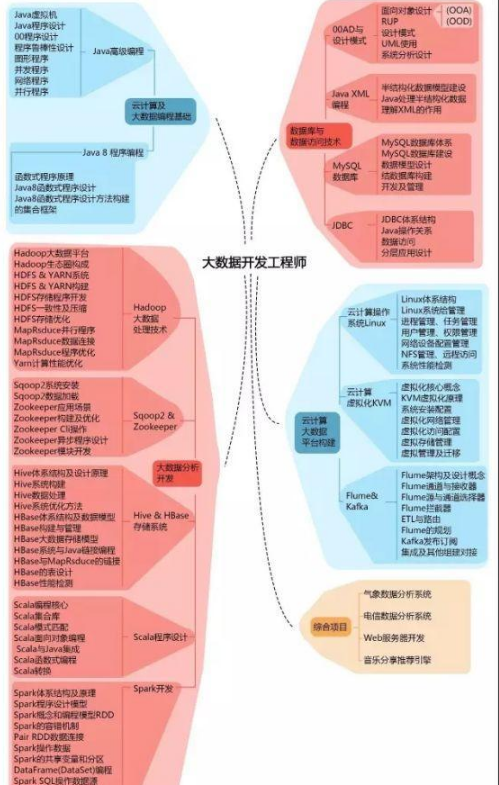
随着业务和大数据技术的发展,越来越多的公司需要在后端架设Hbase数据库,而原有的业务则需要从各种RDBMS数据库中迁移到Hbase当中。Appach的sqoop(发音:[skup])就是基于这样的需求而诞生的,本文详细记录了一个通过sqoop将数据从postgresql迁移到Hbase的例子。
要完成数据的迁移,那前期毋庸置疑,目的集群上一定是已经安装好了:
在我的例子中:
具体的集群安装,可以参考网上的各种文章。
这里需要注意的是,其实sqoop已经不支持最新版本的hbase了,但本文的操作至少是可以做的:
Sqoop does not support the latest versions of Hbase yet. The latest of Sqoop is compatible with versions of Hbase <= 0.95.2, there is an open issue (SQOOP-2759) for this hbase-sqoop integration.
http://mirrors.cnnic.cn/apache/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
将sqoop解压到“/usr/lib/sqoop”目录.
$tar -xvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha /usr/lib/sqoop把sqoop相关的环境变量配置到 ~/.bashrc 文件:
export SQOOP_HOME=/usr/lib/sqoop
export PATH=$PATH:$SQOOP_HOME/bin然后source ~/.bashrc 文件.
$ source ~/.bashrc复制创建sqoop-env.sh
mv sqoop-env-template.sh sqoop-env.sh修改 sqoop-env.sh 加入下面三行,根据集群情况填写
HADOOP_COMMON_HOME=/opt/hadoop-2.7.3/
HADOOP_MAPRED_HOME=/opt/hadoop-2.7.3/
HBASE_HOME=/opt/hbase-1.3.0添加jar包
下载postgresql的jdbc驱动,并放置到sqoop的lib目录
Crl -L 'http://jdbc.postgresql.org/download/postgresql-9.2-1002.jdbc4.jar' -o postgresql-9.2-1002.jdbc4.jar
mv postgresql-9.2-1002.jdbc4.jar /usr/lib/sqoop/lib/进入sqoop的bin目录下执行命令
./sqoop-list-tables --connect jdbc:mysql://your_postgresql_address:port/your_db_name --username mysqlusername --P然后提示输入密码,输入数据库登录密码即可。然后终端显示该数据库下的所有表名称。表示Sqoop安装成功
现在我的postgresql里面有多张表:
假设准备导入aswu_operation这张表。因为sqoop不支持最新版的hbase,因此必须手动的在Hbase里面创建一张表来存储postgresql里的aswu_operation表。这里,仍然采用aswu_operation作为表名:
hbase(main):002:0> create 'aswu_operation' 'Op_info'
然后执行sqoop的import命令。
sqoop import --connect jdbc:postgresql://10.141.47.194/aswudb --table aswu_operation --hbase-table aswu_operation --column-family Op_info --hbase-row-key id --username postgres --P该语句的意思是从jdbc:postgresql中读入aswu_operation表到Hbase的aswu_operation表,postgresql的aswu_operation表中的所有column,都归入到Hbase的aswu_operation表的‘Op_info’column family。而Hbase的aswu_operation表的row key采用postgresql的aswu_operation表中的id字段。
相关的命令的具体解释:
--table <table-name> Table to read
HBase arguments:
--column-family <family> Sets the target column family for the
import
--hbase-bulkload Enables HBase bulk loading
--hbase-create-table If specified, create missing HBase tables
--hbase-row-key <col> Specifies which input column to use as the row key
--hbase-table <table> Import to <table> in HBase
在该命令执行之后,sqoop会生成mapreduce的job,会有多个task并行的从postgresql上读取数据,并往hbase上插入数据。因为配置了集群的缘故,会有多个节点尝试去访问postgresql。因此,需要在postgresql上打开这些节点的访问权限。具体方法是编辑pg_hba.conf文件,加入各个hadoop节点的ip访问权限:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
host all all 10.157.69.85/31 md5
host all all 10.157.69.216/31 md5
host all all 10.157.70.158/31 md5
host all all 10.157.70.38/31 md5
host all all 10.157.65.174/31 md5
host all all 10.157.68.60/31 md5
host all all 10.157.69.216/31 md5
host all all 10.157.66.49/31 md5
host all all 10.157.67.63/31 md5完成之后,会看到如下输出:
打开hbase,查询数据是否已经插入:
hbase(main):002:0> get 'aswu_operation', '1'
COLUMN CELL
Op_info:end_time timestamp=1488176106248, value=2017-02-27 13:14:20.818
Op_info:failed_steps timestamp=1488176106248, value=0
Op_info:last_updated timestamp=1488176106248, value=2017-02-27 13:14:20.818
Op_info:progress timestamp=1488176106248, value=0
Op_info:restart_possible timestamp=1488176106248, value=false
Op_info:start_time timestamp=1488176106248, value=2017-02-27 13:14:00.193
Op_info:status timestamp=1488176106248, value=SUCCEED
Op_info:success_steps timestamp=1488176106248, value=1
Op_info:target timestamp=1488176106248, value={"externalFmReportId":1}
Op_info:target_name timestamp=1488176106248, value=
Op_info:total_steps timestamp=1488176106248, value=1
Op_info:type timestamp=1488176106248, value=FM_REPORT
Op_info:version timestamp=1488176106248, value=1
operation:end_time timestamp=1488183791964, value=2017-02-27 13:14:20.818
operation:failed_steps timestamp=1488183791964, value=0
operation:last_updated timestamp=1488183791964, value=2017-02-27 13:14:20.818
operation:progress timestamp=1488183791964, value=0
operation:restart_possible timestamp=1488183791964, value=false
operation:start_time timestamp=1488183791964, value=2017-02-27 13:14:00.193
operation:status timestamp=1488183791964, value=SUCCEED
operation:success_steps timestamp=1488183791964, value=1
operation:target timestamp=1488183791964, value={"externalFmReportId":1}
operation:target_name timestamp=1488183791964, value=
operation:total_steps timestamp=1488183791964, value=1
operation:type timestamp=1488183791964, value=FM_REPORT
operation:version timestamp=1488183791964, value=1
1 row(s) in 0.3200 seconds
可以看到对应的数据已经插入到Hbase里面。
从上面已经完成的步骤,我们可以看到数据表已经被迁移到了Hbase当中,但我们知道在Hbase当中,row-key的设计非常重要。不可能简单的使用RDBMS中的主键(一般是big interger的id)作为row-key。row-key需要根据业务场景的需求,能够方便通过排序,筛选等操作得到我们需要读取或操作的数据集。因此,在导入的过程中,我们需要对Row key进行一定的变形或修饰。具体做法如下:
sqoop在往hbase插入数据时,会调用类PutTransformer来生成插入hbase需要的Put类,该Put类定义了如何生成rowkey, cloumn name (column family name + column name)和column value。通过修改Put对象的行为,我们可以轻松的修改row key, column name和column value。
因此我们需要自定义PutTransformer的行为,并通过命令行参数,告诉sqoop使用我们自定义的PutTransformer类。一下是一个简单的定义。首先我们需要先extend PutTransformer。再对getPutCommand方法进行override。
具体这个类的行为,大部分代码可以参考sqoop本身自带的ToStringPutTransformer类。
这里的关键是这句:
Put put = new Put( Bytes.toBytes( rowKey.toString() + ":operation" ) );为rowkey加上了一个“operation”的后缀。
具体代码如下:
package com.sqoop.example;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.sqoop.hbase.PutTransformer;
/**
* @author Lex Li
* @date 27/02/2017
*/
public class AswuOperationTransFormat
extends PutTransformer
{
private Mapbyte
org.apache.sqoop
sqoop
1.4.6
jar -cvf sqoop-1.4.6.jar sqoop-1.4.6/重新生成sqoop-1.4.6.jar文件。在sqoop import的命令行中加入:
-D sqoop.hbase.insert.put.transformer.class=com.sqoop.example.AswuOperationTransFormat具体的就是:
sqoop import -D sqoop.hbase.insert.put.transformer.class=com.sqoop.example.AswuOperationTransFormat --connect jdbc:postgresql://10.141.47.194/aswudb --table aswu_operation --hbase-table aswu_operation --column-family Op_info --hbase-row-key id --username postgres --P完成后,进入Hbase查看:
10005:operation column=Op_info:end_time, timestamp=1488266002107, value=2017-02-28 12:47:08.509
10005:operation column=Op_info:error_code, timestamp=1488266002107, value=ASWUR01
10005:operation column=Op_info:error_description, timestamp=1488266002107, value=Unexpected error appears. Try to fail main o
peration.
10005:operation column=Op_info:failed_steps, timestamp=1488266002107, value=1
10005:operation column=Op_info:last_updated, timestamp=1488266002107, value=2017-02-28 12:47:08.509
10005:operation column=Op_info:progress, timestamp=1488266002107, value=0
10005:operation column=Op_info:restart_possible, timestamp=1488266002107, value=true
10005:operation column=Op_info:software_package_title, timestamp=1488266002107, value=4G
10005:operation column=Op_info:start_time, timestamp=1488266002107, value=2017-02-28 12:47:08.364
10005:operation column=Op_info:status, timestamp=1488266002107, value=FAILED
10005:operation column=Op_info:success_steps, timestamp=1488266002107, value=0
10005:operation column=Op_info:target, timestamp=1488266002107, value=CLUSTER-1269/PLMN-PLMN/MRBTS-567
10005:operation column=Op_info:target_name, timestamp=1488266002107, value=
10005:operation column=Op_info:total_steps, timestamp=1488266002107, value=2
10005:operation column=Op_info:type, timestamp=1488266002107, value=SW_UPLOAD
10005:operation column=Op_info:version, timestamp=1488266002107, value=1
10 row(s) in 0.4560 seconds
所有的row key加上了”:operation”的后缀






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有