文章目录使用ComplexHeatmap包绘制个性化热图检测安装加载包创建测试数据集一行命令绘图调参美化猜你喜欢写在后面使用ComplexHeatmap包绘制个性化热图作者&#x
文章目录 使用ComplexHeatmap包绘制个性化热图 检测安装加载包 创建测试数据集 一行命令绘图 调参美化 猜你喜欢 写在后面
使用ComplexHeatmap包绘制个性化热图 作者:刘梦瑶 诺禾致源 微生物信息
审稿:刘永鑫 中国科学院遗传与发育生物学研究所
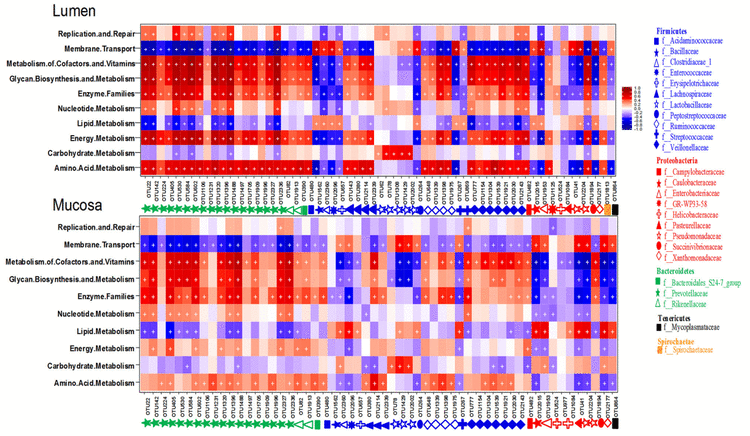
ComplexHeatmap包由顾祖光博士创建,是一个非常全面的绘制热图的R包,可以利用它来绘制许多文献中的美图,例如下图展示的16S文献分析中的热图。这里主要介绍一下如何用这个R包来绘制类似的个性化热图。
检测安装加载包 # 检测安装CRAN包
创建测试数据集 可以按照的Bioconductor官网上ComplexHeatmap包的说明来创建一个测试数据(http://bioconductor.org/packages/release/bioc/vignettes/ComplexHeatmap/inst/doc/s2.single_heatmap.html )
# 设置随机数种子,保证数据分析随机过程可重复
一行命令绘图 使用默认参数,一行命令即可出图
#默认对行和列都进行聚类
调参美化 下面我们通过参数设置来进行个性化热图定制。
使用HeatmapAnnotation函数可以构建注释对象,我们可以进行自定义,也可以直接使用它的内置函数。
注释按位置来分类可分为行注释和列注释,以列注释为例,其内置函数按照图形的类型可以分为6种,anno_points(),anno_barplot(),anno_boxplot(),anno_histogram(),anno_density(),anno_text()。
行注释的内置函数和列注释类似,前面加上row即可,如row_anno_points()。
本文重点讨论anno_points()的用法。
# 生成包含10个0.5数值的向量
"type"为这一行注释的名称,show_annotation_name = FALSE,即不显示名称。pch可指定绘制点时使用的符号,共25种,如上三角,下三角,圆形,方形等,具体可见《R In Action》。size可指定符号的大小,gp可指定符号的颜色。
# 批量按行中心标准化,减均值除方差,Z-score
如需对数据进行标准化,需使用apply函数来处理数据。我们可以通过circlize包中的colorRamp2()函数,来自定义颜色。对mat_scaled的数值进行筛选,生成一个符号是加号或空值的新数据框。这一部分可以根据作图要求来自定义。
P1=Heatmap(mat_scaled,
name可定义图例的名称。top_annotation 可引用上面定义好的列注释, 并将列注释放在heatmap上方;bottom_annotation 则将列注释放在heatmap下方。rect_gp定义小方格的边框颜色,线条类型及宽度。cell_fun可以对heatmap的每个小方格进行自定义,这里用其来显示”+”号,也可以显示数字等。cluster_rows和cluster_columns可定义是否聚类。row_names_side可定义行名的显示位置,默认值right。column_names_side可定义列名的显示位置,默认值bottom。row_names_gp可定义列名的颜色。
# 行名第一列
rowAnnotation中max_text_width可计算得到列名中最长的文本宽度,legendGrob可自定义图例的名称,形状,颜色。
猜你喜欢 10000+: 菌群分析 系列教程:微生物组入门 Biostar 微生物组 宏基因组 专业技能:生信宝典 学术图表 高分文章 不可或缺的人 一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote 文献阅读 热心肠 SemanticScholar Geenmedical 扩增子分析:图表解读 分析流程 统计绘图 16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun 在线工具:16S预测培养基 生信绘图 科研经验:云笔记 云协作 公众号 编程模板: Shell R Perl 生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘 写在后面 为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外5000+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍末解决群内讨论,问题不私聊,帮助同行。
学习扩增子、宏基因组科研思路和分析实战,关注“宏基因组”
点击阅读原文,跳转最新文章目录阅读
















 京公网安备 11010802041100号
京公网安备 11010802041100号