我记得最初的P4微架构的一个有趣的特点是它是双泵ALU.我认为英特尔称它为快速执行单元,但基本上它意味着ALU中的每个执行单元实际上以两倍的频率运行,并且可以在一个周期内处理两个简单的ALU操作,即使它们是依赖的.
这个功能在某些时候消失了(在P4之前或同时),但是有没有一个带有双重转储ALU 的64位 P4?P4的64位变体在2004年推出,大约是在最初的32位发布后的四年,但我不清楚双速ALU是否已经消失.似乎宽度流水线方法用于加倍速度对64位来说很难,这激起了我的好奇心.
由于人们可能仍然需要支持一些(显然很旧的)64位P4硬件,因此了解ALU行为对于优化很有意义.
1> Hadi Brais..:
我发现英特尔优化手册2005涵盖了32位和64位NetBurst处理器.请参阅第C-17页的表C-8.根据这篇博客文章的第一条评论,32位Northwood的模型是02h,而64位Nocona的模型是03h.该表显示ADD/SUB/AND/OR/XOR两个处理器的吞吐量均为0.5个周期,但Northwood的延迟为0.5个周期,Nocona的延迟为1个周期.这意味着Nocona支持双泵,但前提是背对背指令不依赖.该表的其余部分还显示,在诺斯科纳(Nocona)上,一些未在Northwood上进行双重抽水的指令是双泵的.
简介:有大量证据表明,一些基于NetBurst的处理器(无论是已发布还是已取消)可以使用2个32位交错ALU或至少一个64位交错ALU,每个周期至少执行2次64位ALU操作(这将通过较小的特征尺寸启用,例如当时的90nm).
Intel Pentium 4 Willamette 2处理器上的原始论文1的图7 讨论了双泵3 ALU 如何在某些细节(逻辑设计级别)工作.

该图显示了一个32位交错的ALU单元.这证实了ALU可以在三个快速周期中执行两个完全相关(两个输入操作数都相关)的简单ALU操作(其中快速周期是主时钟周期的一半).在2个快速循环(1个主循环)之后,操作本身的结果可用,但新标志仅在第三个快速循环(1.5个主循环)后可用.请注意,端口0和1上有两个这样的ALU,两者都是交错的.因此,该设计可以执行2个依赖性ALU链,每个慢循环吞吐量具有4个操作.
该论文发表于2001年.英特尔在2005年发表了另一篇论文4,详细讨论了电路级如何在英特尔奔腾4 Prescott 5处理器中交错整数核心.我不清楚该论文是否讨论了64位版本的Prescott或32位版本.然而,本文明确指出,交错的ALU单元只能执行加法,布尔运算,移位和旋转(另一篇论文讨论了Prescott核心的设计,其中两个快速ALU单元不支持移位和旋转).另一个重要区别是该文件的声明:
有两个不同的32位FCLK执行数据路径交错一个时钟以实现64位操作.
因此,端口0和1上的两个快速ALU单元似乎交错排列,从而实现64位快速整数运算,例如加法.因此,该设计可以执行两个32位依赖性ALU链,每个慢循环吞吐量具有4个操作,或者一个64位依赖性ALU链,每个慢循环吞吐量具有2个操作.这比单个交错的64位ALU更强大,它只能执行64位操作,而不能执行32位操作.这很可能是NetBurst微体系结构的64位变体中使用的设计.
来自英特尔的另外6 篇论文7证实,英特尔确实能够设计出双泵64位ALU.我引用了这篇论文:
在本文中,我们描述了采用90nm双Vt CMOS技术制造的单周期整数ALU,在64b模式下工作在4GHz,32b模式延迟为7GHz(在1.3V,25℃测量).
本文未提及此设计是否实际用于任何特定处理器.但考虑到该论文于2004年发布,所有64位NetBurst核心(无论是发布还是取消)都很有可能使用该设计.
英特尔发布了许多基于64位NetBurst的处理器.例如,请参阅服务器级处理器的此列表.其中一个核心叫做Nocona.有一些实验证据表明前面提到的设计(2个交错的32位ALU)实际上是在Nocona中使用的.请参阅2008年CMU教授的一些课程中使用的这些幻灯片,用于代码优化.幻灯片比较了Nocona(64位NetBurst),Intel Core(也是64位)和AMD Opteron(也是64位,并且显然实现了相同的64位交错ALU设计)的性能.这是循环中使用的代码:
x = x + d[i];
其中所有元素都是32位整数(遗憾的是,尚未使用64位).
在幻灯片35上,您可以看到在Nocona和Opteron上实现的32位整数加法吞吐量.由于每个操作都需要一个负载,而Nocona每个周期只支持一个负载,因此Nocona的性能最高可达每个周期约1个操作.然而,Opteron每个周期支持两个负载,接近每个周期2个操作的理论最大值.这个实验当然没有利用惊人的优势,而只是有两个32位简单ALU的事实.
但是,在幻灯片的后面,使用SSE3而不是标量整数寄存器.幻灯片44显示了所有三个处理器的结果.对于SSE3,每4个元素只有一个128位负载.Nocona可以在每个周期从L1D执行64位负载(参见下面引用的文章),而Core可以在每个周期执行单个128位L1D负载.但是,Core具有称为高级数字媒体增强(ADMB)的功能,使其能够在每个周期执行4次32位添加.同一篇论文还提到,前核心架构每个周期仅支持2个32位SSE3 ALU操作.但是如果Nocona中有两个32位交错的ALU,则SSE3的低吞吐量意味着SSE3操作仅使用交错的ALU中的一个.ADMB可以通过两种方式实现.通过将每个ALU扩展到64位并保持它们交错并利用两个ALU每个周期执行2个64位ALU操作.另一种可能性是将每个ALU扩展到128位并消除错误.
英特尔于1998年提交了一项专利,并于2001年授权交错执行指令,基本上不是ALU操作.该专利仍然有效.关于交错执行如何对128位SIMD指令有用,有很多讨论.基于该专利,英特尔酷睿很可能使用两个64位交错的ALU来实现其吞吐量.每个64位ALU实际上可以使用上图中所示的两个交错的32位ALU来制作.
2002年,英特尔为通用交错ALU设计申请了专利.从某种意义上讲它是通用的,它与任何特定的ALU操作或时钟周期数或时钟周期无关.这里有趣的是,其中一个图显示了交错的64位ALU设计!那是在2002年.该专利还讨论了设计交错ALU的一些挑战.
该专利说它在2006年的同一天被授予和放弃.然后几个月后,又提交了另一份相同的专利申请.
此文章表明波托马克(另一个服务器级的Pentium 4)是64位架构和支持每个周期4的64位.Yamhill和Jayhawk被英特尔取消.(文章中有一个错误:Nocona是一个64位CPU.)
(1)如果链接断开,该论文的标题为"Pentium®4处理器的微架构",由Glenn Hinton等人撰写.
(2)也称为第一代奔腾4.
(3)也称为交错ALU.
(4)如果链路断开,该论文标题为"Pentium®4处理器整数核心的低压摆动逻辑电路",由Daniel J. Deleganes等人撰写.
(5)也称为第三代奔腾4.
(6)如果链路断开,该论文标题为"一个4GHz 300mW 64b整数执行ALU,具有90nm CMOS的双电源电压",由Sanu K. Mathew等人撰写.
(7)如果链接断开,该论文标题为"高性能能源双效供应设计",由Sanu K. Mathew等人撰写.





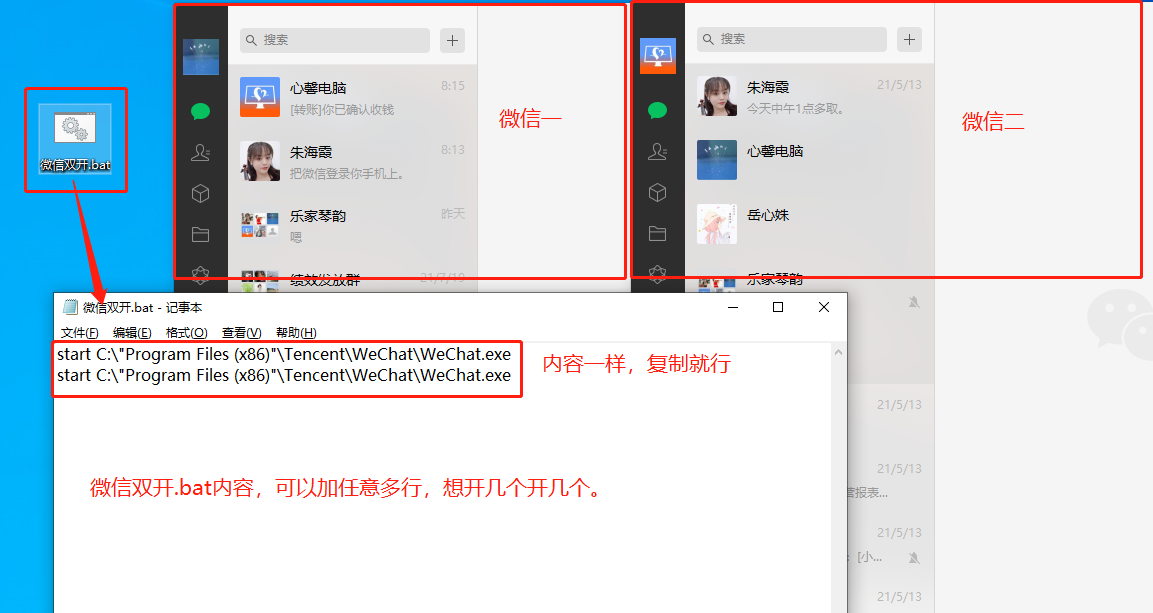



 京公网安备 11010802041100号
京公网安备 11010802041100号