目录一、常用的评价指标1、SSE(误差平方和)2、R-square(决定系数)3、Adjusted R-Square (校正决定系数)二、python中的sklearn. metrics(1) exp
目录
一、常用的评价指标
1、SSE(误差平方和)
2、R-square(决定系数)
3、Adjusted R-Square (校正决定系数)
二、python中的sklearn. metrics
(1) explained_variance_score(解释方差分)
(2) Mean absolute error(平均绝对误差)
(3)Mean squared error(均方误差)
(4) Mean squared logarithmic error
(5)Median absolute error(中位数绝对误差)
(6) R² score(决定系数、R方)
三、交叉验证在python上的实现
一、常用的评价指标
对于回归模型效果的判断指标经过了几个过程,从SSE到R-square再到Ajusted R-square, 是一个完善的过程:
SSE(误差平方和):The sum of squares due to error
R-square(决定系数):Coefficient of determination
Adjusted R-square:Degree-of-freedom adjusted coefficient of determination
下面我对以上几个名词进行详细的解释下,相信能给大家带来一定的帮助!!
1、SSE(误差平方和)
计算公式如下:
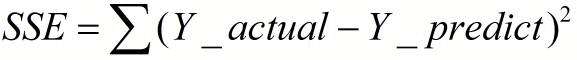
- 同样的数据集的情况下,SSE越小,误差越小,模型效果越好
- 缺点:
SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义
2、R-square(决定系数)
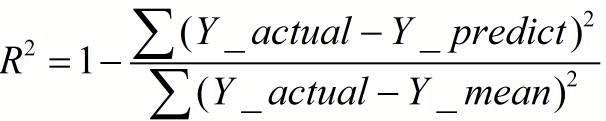
- 数学理解: 分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响
- 其实“决定系数”是通过数据的变化来表征一个拟合的好坏。
- 理论上取值范围(-∞,1], 正常取值范围为[0 1] ------实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞
- 一个常数模型总是预测 y 的期望值,它忽略输入的特征,因此输出的R^2会为0
越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好
数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
3、Adjusted R-Square (校正决定系数)

n为样本数量,p为特征数量
二、python中的sklearn. metrics
python的sklearn.metrics中包含一些损失函数,评分指标来评估回归模型的效果。主要包含以下几个指标:n_squared_error, mean_absolute_error, explained_variance_score and r2_score.。
(1) explained_variance_score(解释方差分)
y_hat :预测值, y :真实值, var :方差
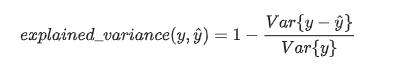
explained_variance_score:解释方差分,这个指标用来衡量我们模型对数据集波动的解释程度,如果取值为1时,模型就完美,越小效果就越差。下面是python的使用情况:
# 解释方差分数
>>> from sklearn.metrics import explained_variance_score
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> explained_variance_score(y_true, y_pred)
0.957...
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> explained_variance_score(y_true, y_pred, multioutput='raw_values')
...
array([ 0.967..., 1. ])
>>> explained_variance_score(y_true, y_pred, multioutput=[0.3, 0.7])
...
0.990...
(2) Mean absolute error(平均绝对误差)
y_hat :预测值, y :真实值
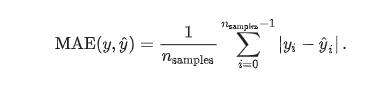
给定数据点的平均绝对误差,一般来说取值越小,模型的拟合效果就越好。下面是在python上的实现:
>>> from sklearn.metrics import mean_absolute_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_absolute_error(y_true, y_pred)
0.5
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> mean_absolute_error(y_true, y_pred)
0.75
>>> mean_absolute_error(y_true, y_pred, multioutput='raw_values')
array([ 0.5, 1. ])
>>> mean_absolute_error(y_true, y_pred, multioutput=[0.3, 0.7])
...
0.849...
(3)Mean squared error(均方误差)
y_hat :预测值, y :真实值
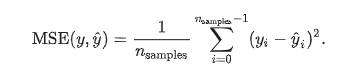
这是人们常用的指标之一。
>>> from sklearn.metrics import mean_squared_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_squared_error(y_true, y_pred)
0.375
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> mean_squared_error(y_true, y_pred)
0.7083...
(4) Mean squared logarithmic error
y_hat :预测值, y :真实值
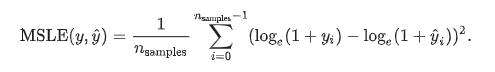
当目标实现指数增长时,例如人口数量、一种商品在几年时间内的平均销量等,这个指标最适合使用。请注意,这个指标惩罚的是一个被低估的估计大于被高估的估计。
>>> from sklearn.metrics import mean_squared_log_error
>>> y_true = [3, 5, 2.5, 7]
>>> y_pred = [2.5, 5, 4, 8]
>>> mean_squared_log_error(y_true, y_pred)
0.039...
>>> y_true = [[0.5, 1], [1, 2], [7, 6]]
>>> y_pred = [[0.5, 2], [1, 2.5], [8, 8]]
>>> mean_squared_log_error(y_true, y_pred)
0.044...
y_hat :预测值, y :真实值

中位数绝对误差适用于包含异常值的数据的衡量
>>> from sklearn.metrics import median_absolute_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> median_absolute_error(y_true, y_pred)
0.5
(6) R² score(决定系数、R方)
R方可以理解为因变量y中的变异性能能够被估计的多元回归方程解释的比例,它衡量各个自变量对因变量变动的解释程度,其取值在0与1之间,其值越接近1,则变量的解释程度就越高,其值越接近0,其解释程度就越弱。
一般来说,增加自变量的个数,回归平方和会增加,残差平方和会减少,所以R方会增大;反之,减少自变量的个数,回归平方和减少,残差平方和增加。
为了消除自变量的数目的影响,引入了调整的R方
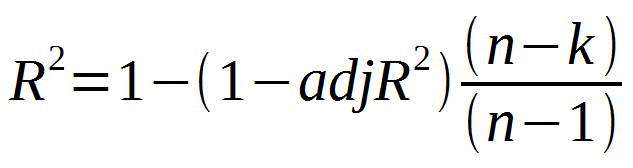
>>> from sklearn.metrics import r2_score
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> r2_score(y_true, y_pred)
0.948...
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> r2_score(y_true, y_pred, multioutput='variance_weighted')
...
0.938...
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> r2_score(y_true, y_pred, multioutput='uniform_average')
...
0.936...
>>> r2_score(y_true, y_pred, multioutput='raw_values')
...
array([ 0.965..., 0.908...])
>>> r2_score(y_true, y_pred, multioutput=[0.3, 0.7])
...
0.925...
三、交叉验证在python上的实现
############################交叉验证,评价模型的效果############################
from sklearn import datasets, linear_model
from sklearn.model_selection import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y, cv=5)) # 默认是3-fold cross validation
############################交叉验证,评价模型的效果############################
from sklearn import datasets, linear_model
from sklearn.model_selection import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y, cv=5)) # 默认是3-fold cross validation
################定义一个返回cross-validation rmse error函数来评估模型以便可以选择正确的参数########
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
def rmse_cv(model):
##使用K折交叉验证模块,将5次的预测准确率打印出
rmse= np.sqrt(-cross_val_score(model, X_train, y_train, scoring="neg_mean_squared_error", cv = 5)) #输入训练集的数据和目标值
return(rmse)
model_ridge = Ridge()
alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean() #对不同的参数alpha,使用岭回归来计算其准确率
for alpha in alphas]
cv_ridge
#绘制岭回归的准确率和参数alpha的变化图
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation - Just Do It")
plt.xlabel("alpha")
plt.ylabel("rmse")







 京公网安备 11010802041100号
京公网安备 11010802041100号