Pytorch的load方法和load_state_dict方法只能较为固定的读入参数文件,他们要求读入的state_dict的key和Model.state_dict()的key
Pytorch的load方法和load_state_dict方法只能较为固定的读入参数文件,他们要求读入的state_dict的key和Model.state_dict()的key对应相等。
而我们在进行迁移学习的过程中也许只需要使用某个预训练网络的一部分,把多个网络拼和成一个网络,或者为了得到中间层的输出而分离预训练模型中的Sequential 等等,这些情况下。传统的load方法就不是很有效了。
例如,我们想利用Mobilenet的前7个卷积并把这几层冻结,后面的部分接别的结构,或者改写成FCN结构,传统的方法就不奏效了。
最普适的方法是:构建一个字典,使得字典的keys和我们自己创建的网络相同,我们再从各种预训练网络把想要的参数对着新的keys填进去就可以有一个新的state_dict了,这样我们就可以load这个新的state_dict,目前只能想到这个方法应对较为复杂的网络变换。
网上查“载入部分模型”,“冻结部分模型”一般都是只改个FC,根本没有用,初学的时候自己写state_dict也踩了一些坑,发出来记录一下。
一.载入部分预训练参数
我们先看看Mobilenet的结构
( 来源github,附带预训练模型mobilenet_sgd_rmsprop_69.526.tar)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
我们只需要前7层卷积,并且为了方便日后concate操作,我们把Sequential拆开,成为下面的样子
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.conv1 = conv_bn( 3, 32, 2)
self.conv2 = conv_dw( 32, 64, 1)
self.conv3 = conv_dw( 64, 128, 2)
self.conv4 = conv_dw(128, 128, 1)
self.conv5 = conv_dw(128, 256, 2)
self.conv6 = conv_dw(256, 256, 1)
self.conv7 = conv_dw(256, 512, 2)
# 原来这些不要了
# 可以自己接后面的结构
''' self.features = nn.Sequential( conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 1024, 2), conv_dw(1024, 1024, 1), nn.AvgPool2d(7),) self.fc = nn.Linear(1024, 1000) '''
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
x4 = self.conv4(x3)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
x7 = self.conv7(x6)
#x8 = self.features(x7)
#out = self.fc
return (x1,x2,x3,x4,x4,x6,x7)
我们更具改过的结构创建一个net,看看他的state_dict和我们预训练文件的state_dict有啥区别
net = Net()
#我的电脑没有GPU,他的参数是GPU训练的cudatensor,于是要下面这样转换一下
dict_trained = torch.load("mobilenet_sgd_rmsprop_69.526.tar",map_location=lambda storage, loc: storage)["state_dict"]
dict_new = net.state_dict().copy()
new_list = list (net.state_dict().keys() )
trained_list = list (dict_trained.keys() )
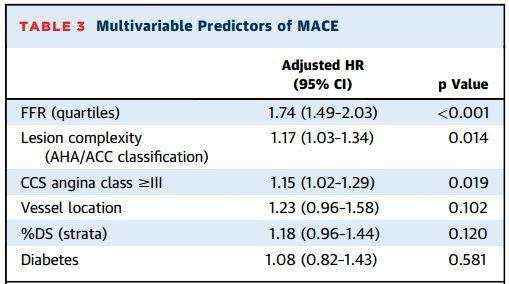
print("new_state_dict size: {} trained state_dict size: {}".format(len(new_list),len(trained_list)) )
print("New state_dict first 10th parameters names")
print(new_list[:10])
print("trained state_dict first 10th parameters names")
print(trained_list[:10])
print(type(dict_new))
print(type(dict_trained))
得到输出如下:
我们截断一半之后,参数由137变成65了,前十个参数看出,名字变了但是顺序其实没变。state_dict的数据类型是Odict,可以按照dict的操作方法操作。
new_state_dict size: 65 trained state_dict size: 137
New state_dict first 10th parameters names
[‘conv1.0.weight’, ‘conv1.1.weight’, ‘conv1.1.bias’, ‘conv1.1.running_mean’, ‘conv1.1.running_var’, ‘conv2.0.weight’, ‘conv2.1.weight’, ‘conv2.1.bias’, ‘conv2.1.running_mean’, ‘conv2.1.running_var’]
trained state_dict first 10th parameters names
[‘module.model.0.0.weight’, ‘module.model.0.1.weight’, ‘module.model.0.1.bias’, ‘module.model.0.1.running_mean’, ‘module.model.0.1.running_var’, ‘module.model.1.0.weight’, ‘module.model.1.1.weight’, ‘module.model.1.1.bias’, ‘module.model.1.1.running_mean’, ‘module.model.1.1.running_var’]
我们看出只要构建一个字典,使得字典的keys和我们自己创建的网络相同,我们在从各种预训练网络把想要的参数对着新的keys填进去就可以有一个新的state_dict了,这样我们就可以load这个新的state_dict,这是最普适的方法适用于所有的网络变化。
for i in range(65):
dict_new[ new_list[i] ] = dict_trained[ trained_list[i] ]
net.load_state_dict(dict_new)
还有别的情况,比如我们只是在后面加了一些层,没有改变原来网络层的名字和结构,可以用下面的简便方法:
loaded_dict = {k: loaded_dict[k] for k, _ in model.state_dict()}
二.冻结这几层参数
方法很多,这里用和上面方法对应的冻结方法
发现之前的冻结有问题,还是建议看一下
https://discuss.pytorch.org/t/how-the-pytorch-freeze-network-in-some-layers-only-the-rest-of-the-training/7088
或者
https://discuss.pytorch.org/t/correct-way-to-freeze-layers/26714
或者
对应的,在训练时候,optimizer里面只能更新requires_grad = True的参数,于是
optimizer = torch.optim.Adam( filter(lambda p: p.requires_grad, net.parameters(),lr) )











 京公网安备 11010802041100号
京公网安备 11010802041100号