import torchtorch.manual_seed(7)
w = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)y.backward(retain_graph=True)
x = torch.tensor([3.], requires_grad=True)y = torch.pow(x, 2) # y = x**2grad_1 = torch.autograd.grad(y, x, create_graph=True) # grad_1 = dy/dx = 2x = 2 * 3 = 6grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
autograd小贴士: 梯度不自动清零依赖于叶子节点的节点,requires_grad默认为True叶子节点不可执行in-place
autograd小贴士:
x &#61; torch.randn(3, requires_grad&#61;True)y &#61; x * 2while y.data.norm() < 1000:y &#61; y * 2print(y)
tensor([-150.3182, 805.0087, 969.5453], grad_fn&#61;)
v &#61; torch.tensor([0.1, 1.0, 0.0001], dtype&#61;torch.float)y.backward(v)print(x.grad)
tensor([1.0240e&#43;02, 1.0240e&#43;03, 1.0240e-01])
print(x.requires_grad)print((x ** 2).requires_grad)with torch.no_grad():print((x ** 2).requires_grad)
True True False
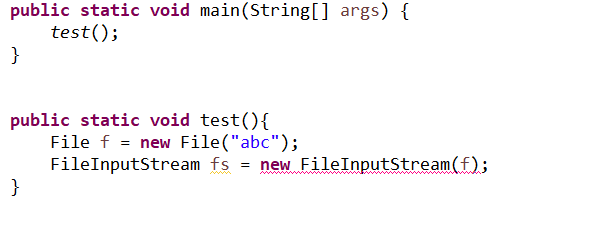
求y&#61;x2y&#61;x^2y&#61;x2对xxx的一阶偏导和二阶偏导。








 京公网安备 11010802041100号
京公网安备 11010802041100号