作者:后起之秀 | 来源:互联网 | 2023-10-14 03:20
作者:文松
链接:https://www.zhihu.com/question/280526042/answer/1615449221
来源:知乎
一、高端内存的由来(为什么需要高端内存)
在32位地址时代,最大可寻址0xFFFFFFFF,即4GB,因此虚拟地址空间有4GB,通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间,即Linux内核虚拟地址空间只有1G。
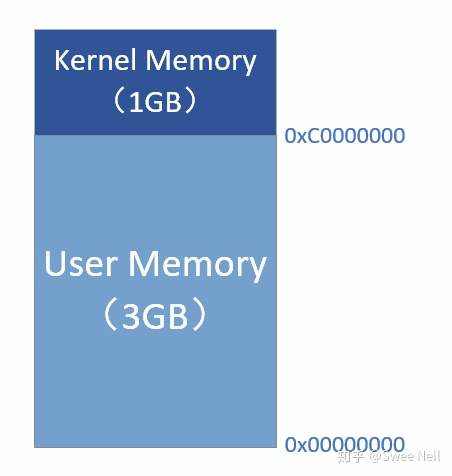
32位地址空间
实际的计算机体系结构有硬件的限制,这约束了页框的使用方式,其中,Linux内核必须处理x86体系结构的两种硬件约束:
- ISA总线的直接内存存取(DMA)处理器有一个严格的限制:它们只能对RAM的前16MB地址进行寻址。
- 在具有大容量RAM的现代32位计算机中,CPU不能直接访问所有的物理内存,因为现行地址大小太小。
为了应对这种限制,对于x86机器,Linux内核将内存区域又被分为了3个管理区(zone)。
| 区域 |
|---|
| ZONE_DMA | 低于16MB的内存空间 |
| ZONE_NORMAL | 16MB~895MB |
| ZONE_HIGHMEM | 896MB~物理内存结束 |
在内核或应用程序访问内存时,所操作的内存地址都为虚拟地址,而对应到真正的物理内存地址,需要地址一对一的映射。对于应用程序,虚拟地址到物理地址的转换需要MMU,而对于内核前两个管理区的内存空间被直接映射到虚拟地址空间中。
对于内核,直接映射时虚拟地址0xc0000003对应的物理地址为0x00000003,0xc0000004对应的物理地址为0x00000004。虚拟地址与物理地址有如下的对应关系:
物理地址 = 虚拟地址 – 0xC0000000
在Linux内核中,有虚拟地址向物理地址转换的宏:
__virt_to_phys
也是直接通过上面的对应关系计算而来~
如果按照上面所说的采用直接映射的方式,将内核1G的地址空间全部直接映射,就会发现内核只能访问1GB的物理内存,但是实际上我们的物理内存,往往是8G、16G,甚至更高,那么其他空间内核将无法访问和管控。所以必须要有一种灵活的方式,既减少开销,同时又让内核能够访问全部的物理内存,Linux高端内存十分必要。
Linux 规定“内核直接映射空间” 最多映射 896M 物理内存~
高端内存就是帮助我们访问除了直接映射的896MB物理内存之外的其他内存空间。
二、实现方式
内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存呢?
在《深入理解LINUX内核》中介绍了,内核可以采用三种不同的机制将页框映射到高端内存,分别叫做:
- 永久内存映射
- 临时内存映射
- 非连续内存分配
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的虚拟地址空间,借用一会。
借用这段虚拟地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
@Swee Neil
的回答已经把core concept介绍清楚了,我这边补充一些内容。
要理解high memory是要解决什么问题,首先要了解下内核地址转换的方式。在内核中我们往往要频繁地进行虚拟/物理地址操作,在这种情况下,快速高效的virtual to physical转换就很重要。可如果按照多级页表path walk去查找,内存访问开销就比较大,因此一种简单的"fix-mapping"思路是:将0xC0000000-0xFFFFFFFF的虚拟地址直接映射到0x00000000-0x3FFFFFFF,也就是将最高的1G地址全部映射到最低的1G,这样虚拟地址与物理地址之间就有固定的3G offset,每当遇到一个内核中的符号,我们需要得到其物理地址时,直接减去3G即可。
有人可能会问,那0-3G的比较低的那些虚拟地址怎么转换呢?答案是不用,也就是内核自己不使用0-3G的虚拟地址(除非是处理syscall)。
上述这种简单粗暴的处理方式很方便理解,效率也比较高(只需要简单的减法操作),但也有自己的局限性。在32位处理器下,按照经典用户态与内核3:1的划分比例,内核能够使用的虚拟地址只有1G大,按照固定offset的映射方式,这意味着内核能够使用的物理地址大小也只有1G。但...随着内核越来越复杂,各种数据结构对内存的需求也越来越高,比如用来物理页的page结构体,仅仅在其上增加一个12字节的reverse mapping管理结构,就会使得page总体占用的内存增高400KB,将近96个物理页大小[1];即便内存技术的发展使得高于4G的内存变得十分常见,受限于32位系统与这种fix-mapping,内核可用的物理内存大小仍然被死死地限制在1G。
以上,算是对high memory要解决问题的背景介绍。通俗地讲,"high memory"要解决的是32位下虚拟地址空间不足带来的问题(而显然,对64位系统这个问题就不存在了)。实际上在很早以前这个问题就在lwn上讨论过了[2] ,在当时已经有一些临时的方法去规避这个问题,比如重新划分用户/内核的地址空间比例,变为2.5:1.5等等,但在特定场景下(比如用户态使用的内存非常非常多)会使得用户态运行效率降低,同时带来一些非对其问题,因此也不是一个很好的办法。
怎么解决呢?
如
@Swee Neil
所提到的,我们可以把这1G,划分成两部分,一部分用来fix-mapping,一部分用来dynamic-mapping。以x86为例,实际中的做法是,0xC0000000-0xF7FFFFFF的896MB用作fix-mapping,0xF8000000-0xFFFFFFFF的128MB用作dynamic-mapping,前者仍然对应于物理地址的0x00000000-0x37FFFFFF(只不过部分要优先分配给DMA);后者就是所谓的high memory。当然,high memory也有自己的缺点,就是效率比较低(既然是动态的,就绕不开重映射、pte操作等等)。
实际上high memory还被划分为了3个区域[3],一部分用于vmalloc分配虚拟地址上连续的内存,一部分用于较长期的动态映射(persistent kernel mappings),还有一部分用于编译时可以直接分配物理地址的高端固定映射(fixmaps):

x86_32的memlayout
来到64位系统,这个问题天然就不存在,因此在64位系统的memlayout[3]中就没有high memory,但vmalloc仍然是内核的一个重要部分,因此memlayout中仍然有这一部分:

x86_64的memlayout
参考
- ^Kernel development LWN - Kernel
- ^Virtual Memory I: the problem Virtual Memory I: the problem [LWN.net]
- ^abMauerer, W. (2010). Professional Linux Kernel Architecture. Somerset: Wiley.









 京公网安备 11010802041100号
京公网安备 11010802041100号