||
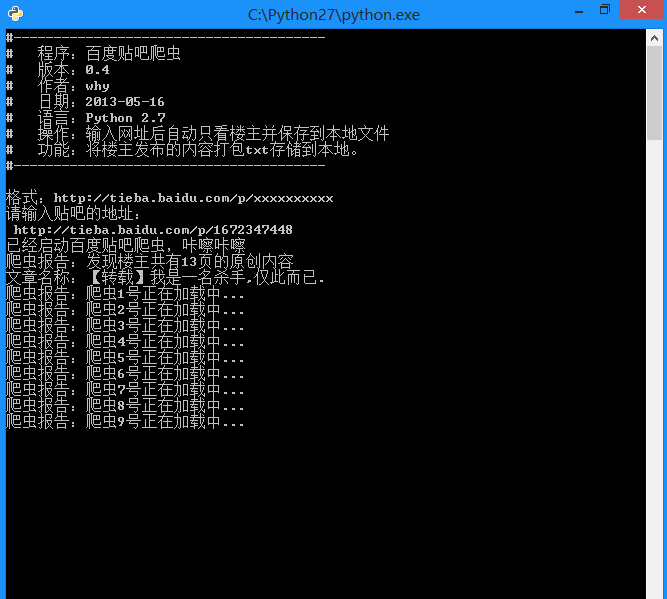
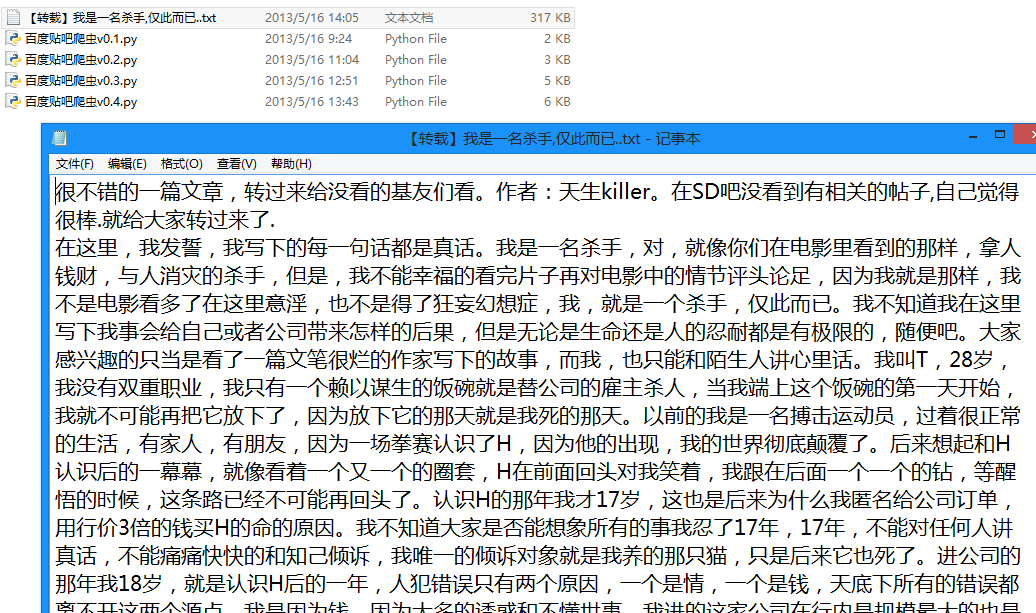
)") ") 12 页" 来获取一共有多少页 xxxxxxxxxx 找出标题 (.*?)', myPage, re.S) #-------- 程序入口处 ------------------
以上就是改进之后的抓取百度贴吧的全部代码了,非常的简单实用吧,希望能对大家有所帮助
推荐阅读
本文介绍了如何通过修改织梦DedeCms源代码来实现全站伪静态,以提高管理和SEO效果。全站伪静态可以避免重复URL的问题,同时通过使用mod_rewrite伪静态模块和.htaccess正则表达式,可以更好地适应搜索引擎的需求。文章还提到了一些相关的技术和工具,如Ubuntu、qt编程、tomcat端口、爬虫、php request根目录等。 ...
[详细]
蜡笔小新 2023-12-14 19:45:47
本文介绍了使用正则表达式来爬取36Kr网站首页所有新闻的操作步骤和代码示例。通过访问网站、查找关键词、编写代码等步骤,可以获取到网站首页的新闻数据。代码示例使用Python编写,并使用正则表达式来提取所需的数据。详细的操作步骤和代码示例可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-12 19:16:21
本文介绍了lua语言中闭包的特性及其在模式匹配、日期处理、编译和模块化等方面的应用。lua中的闭包是严格遵循词法定界的第一类值,函数可以作为变量自由传递,也可以作为参数传递给其他函数。这些特性使得lua语言具有极大的灵活性,为程序开发带来了便利。 ...
[详细]
蜡笔小新 2023-12-14 18:18:21
本文介绍了在Python爬虫中使用正则表达式的方法和注意事项。首先解释了爬虫的四个主要步骤,并强调了正则表达式在数据处理中的重要性。然后详细介绍了正则表达式的概念和用法,包括检索、替换和过滤文本的功能。同时提到了re模块是Python内置的用于处理正则表达式的模块,并给出了使用正则表达式时需要注意的特殊字符转义和原始字符串的用法。通过本文的学习,读者可以掌握在Python爬虫中使用正则表达式的技巧和方法。 ...
[详细]
蜡笔小新 2023-12-12 11:51:07
本文介绍了如何在HTML5网页模板中加入百度统计,并对模板文件、css样式表、js插件库等内容进行了说明。同时还解答了关于HTML5网页模板的使用方法、表单提交、域名和空间的问题,并介绍了如何使用Visual Studio 2010创建HTML5模板。此外,还提到了使用Jquery编写美好的HTML5前端框架模板的方法,以及制作企业HTML5网站模板和支持HTML5的CMS。 ...
[详细]
蜡笔小新 2023-12-11 12:06:41
web前端|css教程css!importantweb前端-css教程本文分享css中提升优先级属性!important的用法总结微信门店展示源码,vscode如何管理站点,ubu ...
[详细]
蜡笔小新 2023-12-11 11:25:16
本文介绍了求解gcdexgcd斐蜀定理的迭代法和递归法,并解释了exgcd的概念和应用。exgcd是指对于不完全为0的非负整数a和b,gcd(a,b)表示a和b的最大公约数,必然存在整数对x和y,使得gcd(a,b)=ax+by。此外,本文还给出了相应的代码示例。 ...
[详细]
蜡笔小新 2023-12-14 17:48:30
本文介绍了使用Python实现变声器功能(萝莉音御姐音)的方法及步骤。首先登录百度AL开发平台,选择语音合成,创建应用并填写应用信息,获取Appid、API Key和Secret Key。然后安装pythonsdk,可以通过pip install baidu-aip或python setup.py install进行安装。最后,书写代码实现变声器功能,使用AipSpeech库进行语音合成,可以设置音量等参数。 ...
[详细]
蜡笔小新 2023-12-14 16:21:36
本文介绍了Python爬虫技术基础篇面向对象高级编程(中)中的多重继承概念。通过继承,子类可以扩展父类的功能。文章以动物类层次的设计为例,讨论了按照不同分类方式设计类层次的复杂性和多重继承的优势。最后给出了哺乳动物和鸟类的设计示例,以及能跑、能飞、宠物类和非宠物类的增加对类数量的影响。 ...
[详细]
蜡笔小新 2023-12-12 16:19:02
本文介绍了绕过WAF的XSS检测机制的方法,包括确定payload结构、测试和混淆。同时提出了一种构建XSS payload的方法,该payload与安全机制使用的正则表达式不匹配。通过清理用户输入、转义输出、使用文档对象模型(DOM)接收器和源、实施适当的跨域资源共享(CORS)策略和其他安全策略,可以有效阻止XSS漏洞。但是,WAF或自定义过滤器仍然被广泛使用来增加安全性。本文的方法可以绕过这种安全机制,构建与正则表达式不匹配的XSS payload。 ...
[详细]
蜡笔小新 2023-12-11 19:42:30
本文介绍了2022年的风口,探讨了一份稳定的副业收入对于普通人增加收入的重要性,以及如何抓住风口来实现赚钱的目标。文章指出,拼命工作并不一定能让人有钱,而是需要顺应时代的方向。 ...
[详细]
蜡笔小新 2023-12-11 18:31:31
本文介绍了Python开源库和第三方包中常用的框架和库,包括Django、CubicWeb等。同时还整理了GitHub中最受欢迎的15个Python开源框架,涵盖了事件I/O、OLAP、Web开发、高性能网络通信、测试和爬虫等领域。 ...
[详细]
蜡笔小新 2023-12-11 18:24:06
本文介绍了Android实战中使用jsoup实现网络爬虫的方法,以糗事百科项目为例。对于初学者来说,数据源的缺乏是做项目的最大烦恼之一。本文讲述了如何使用网络爬虫获取数据,并以糗事百科作为练手项目。同时,提到了使用jsoup需要结合前端基础知识,以及如果学过JS的话可以更轻松地使用该框架。 ...
[详细]
蜡笔小新 2023-12-11 09:19:45
背景应用安全领域,各类攻击长久以来都危害着互联网上的应用,在web应用安全风险中,各类注入、跨站等攻击仍然占据着较前的位置。WAF(Web应用防火墙)正是为防御和阻断这类攻击而存在 ...
[详细]
蜡笔小新 2023-12-11 01:30:52
本文整理了315道Python基础题目及答案,帮助读者检验学习成果。文章介绍了学习Python的途径、Python与其他编程语言的对比、解释型和编译型编程语言的简述、Python解释器的种类和特点、位和字节的关系、以及至少5个PEP8规范。对于想要检验自己学习成果的读者,这些题目将是一个不错的选择。请注意,答案在视频中,本文不提供答案。 ...
[详细]
蜡笔小新 2023-12-10 14:33:46
夜幕2502896061
这个家伙很懒,什么也没留下!









 京公网安备 11010802041100号
京公网安备 11010802041100号