上篇是对es的安装教程,这篇主要讲下搜索引擎基础知识+es基础知识
一、搜索引擎基础知识:
搜索引擎是什么? 是一个检索服务,主要分全文检索和垂直检索。
Solr、 es
Es是什么?:ElasticSearch,分布式的索引库,Nosql。
对外提供检索服务,http或者transport协议对外提供搜索。Restful的json。Es6.6.0 es2.x。
对内就是一个数据库,nosql
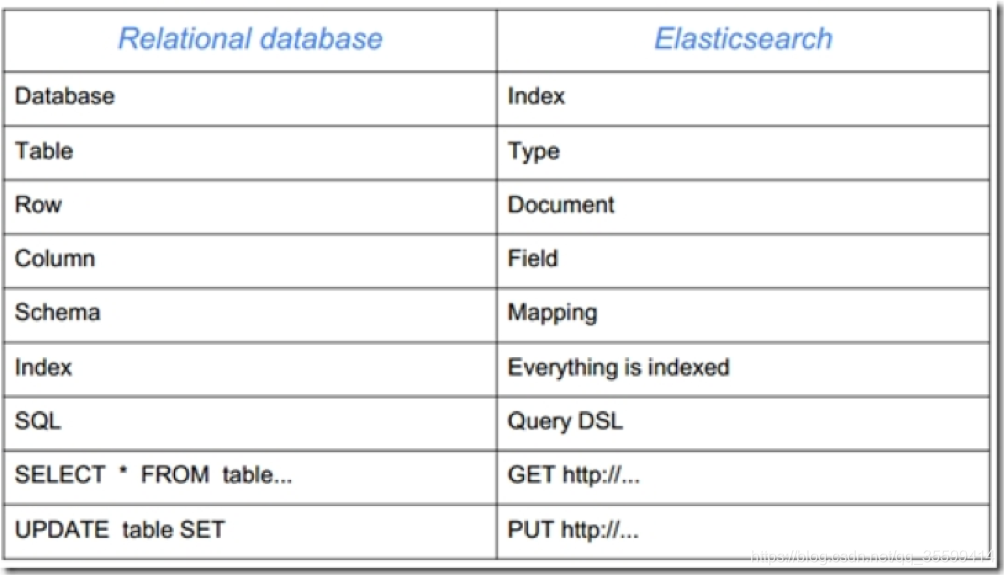
1、Es名词定义:
索引=数据库:很多个
类型(type)=表 =》 es6.x只有一个type,之前可以建很多,es7.x就没有这个type了。
文档=行数据 docment。
Filed
缺点:nosql 非关系型的,没有办法链接查询的,也就是跨索引查询
在ElasticSearch中我们会经常听到以下名词,现在我来将它和关系型数据库做一个对比:
2、分词:
NLP:自然语言处理;
分词可以说是搜索引起的基石,如果一个搜索引擎没有好的分词器那么这个搜索引擎必然是失败的。
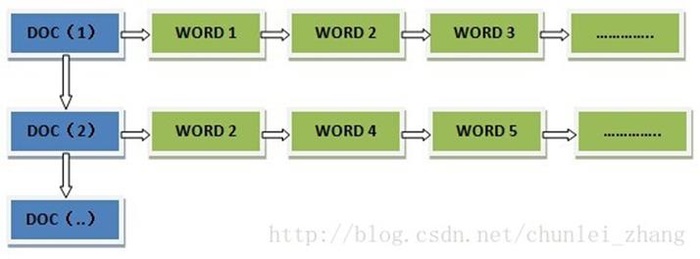
搜索是以词作为最小单元,依靠分词器进行构建,最后会生成一个倒排索引。这个我们后面会详细讲解,这里就提一下.
3、倒排索引:
正向索引:例如hashmap中:key(唯一)——value(多个) 一个唯一的key可以对应多个value,正向索引即根据唯一的key索引找到value值
而倒排索引则是相反的:根据通过不唯一的value值找到唯一的key值
例如我们在搜索文章时:搜索”我在吃饭“
此时搜索引擎会将 ”我在吃饭“ 进行分词为 ”我/在/吃饭“ ,然后去索引库中找到”我“、”在“、”吃饭“这三个词对应的文章出来
(因为我、在、吃饭这三个词在多篇文章存在,所以是不唯一的,而根据该不唯一的值找到多篇有唯一id的文章。整个过程则属于倒排索引)
4、TF-IDF
前面说了倒排索引,那么要是我现在搜出了多篇文章,谁排前面?谁排后面?
TF:词频 ;一篇文章中包含了多少这个词,包含越多表明越相关(例如:”我“出现了20次)
DF:文档频率; 包含这个词的文档总数,比如 :”我“在多少篇文章中出现了。DF越高,则在多篇文章出现的概率越高,则不具备有特殊性(比较普遍,重要性较低),则越不是搜索者想要搜到的文章
IDF = 1/DF:逆文档,DF取反 也就是 1/DF;如果包含该词的文档越少,也就是DF越小,IDF越大,则说明词对这篇文档重要性就越大。
TFIDF: TF*IDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力
Es:有个打分排序:使用BM25算法 tfNom.
二、搭建相同ip的es集群(模拟)
先模拟一下es集群:
这里就不搭建多个虚拟机(不同ip)了,直接利用不同ip设置不同es,而且这里只搭建两个es(你可以自己模拟搭建多个)127.0.0.1:9200 (tcp9300 node-master)
127.0.0.1:9201 (tcp9301 node-slave)
1、复制一份es的解压文件到另一个目录
mkdir /usr/local/es2
cp -R ../es/elasticsearch-6.6.0 /usr/local/es2
2、修改原来配置文件elasticsearch.yml 内容
# 配置es的集群名称, es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-cluster
# 节点名称
node.name: node-master #节点名称
# 设置绑定的ip地址还有其它节点和该节点交互的ip地址
network.host: 0.0.0.0
# 指定http端口,你使用head、kopf等相关插件使用的端口
http.port: 9200
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
#设置集群组ip
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301"] #加上多个ip地址+端口
3、给es用户授权
切换到root:su root
授权:chown -R es:es /usr/local/es2
切回se:su se
4、修改elasticsearch.yml 文件
# 配置es的集群名称, es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-cluster
# 节点名称
node.name: node-slave #节点名称
# 设置绑定的ip地址还有其它节点和该节点交互的ip地址
network.host: 0.0.0.0
# 指定http端口,你使用head、kopf等相关插件使用的端口
http.port: 9201
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9301
#设置集群组ip
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301"] #加上多个ip地址+端口5、分别开启两个es即可
去kibana中查看节点情况:
到此,简单的集群模拟成功(你也可以模拟不同ip的es集群,操作都差不多的)
三、es的基础操作知识
建索引的时候:如:我在吃饭,被拆为我、在、吃饭。此时用索引时搜索吃,是否会匹配到吃饭这个词?(不会,因为es会根据搜索语句进行分词,分完后再去对应查找相应的索引词,如没有找到索引词一样的则找不到)
创建索引用ik_max(分词比较细),检索索引用ik_smart(分词不是很细),这样可以减少分词数量,我在吃饭则会被拆为(我、我在、吃、吃饭、饭),而搜索吃饭用ik_smart则可以减少分词操作,直接搜到吃饭索引词。
副本间数据同步是否存在高并发下数据不一致?
基本概念:
分布式索引介绍:
1.number_of_shards:分片数量,类似于数据库里面分库分表,一经定义不可更改。主要响应写操作
2.number_of_replicas:副本数,用于备份分片的,和分片里面的数据保持一致,主要响应读操作,副本越多读取就越快。
3.分布式索引一定要注意分片数量不能更改,所以在创建的时候一定要预先估算好数据大小,一般在8CPU16G的机器上一个分片不要超过300g。索引会根据分片的配置来均匀的响应用户请求
4.如果调整了分片数那就要重建索引。
例如:Id:有1 2 3 4的4条数据。
2个shard(分片) = > 就要把id全部重建;使用Id%len看每条数据是存在哪个分片
1和3存在shard1;2和4存在shard2
----------------------------------mysql中的分表操作
(分片可以看成mysql的分表操作,msql的分库分表有垂直、水平(分库也分垂直水平))
垂直分表:也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
水平分表:针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用。
---------------------------------------
而分片则是对应我们其中的水平分表,即将数据分别存到不同的分片中去,此时考虑到高可用问题,所以es还提供了一个副本数量的设置。可以根据你es的集群相应的设置副本数量,副本本身是相对于源数据的一个备份。
例如:我们此时部署了两个es集群,然后在es中建立索引(相当于建立数据库),并声明其分片数量为3、副本数量为1(看集群机器多少台)。(可以看成建立一个数据库,其中水平分表为3张,表数据备份1个)
PUT /test //建立test索引(数据库)
{"settings" : {"number_of_shards" : 3, //设置分片为3"number_of_replicas" : 1 //设置副本数为1}
此时可以看到每个节点都有三个分片,并且副本是es集群随机分布的。那么对es集群进行读写时怎么运作的?
进行读操作:不管请求分发到哪个节点,此时都可以在该节点进行读操作
写操作:当请求分发到某个节点时,如果分发到的是master节点,如果请求的是非主节点,此时则将请求转给主节点(master)然后主节点进行分析看属于哪个分片,默认基于文档ID(routing),其基本算法为hash(routing) % (primary count),知道是哪个分片了则看该分片的主分片位于哪个节点,然后将请求发到该节点的主分片进行处理,主节点处理完后,成功后会发送消息给master。如果请求分发到非master节点上,则该节点会将该请求转发到master节点上去,然后由master计算出分配在哪个分片上再去同步到副本上。
注意:分片数量一旦在索引创建完成,则不能修改。(因为旧数据是以原先的分片数量来决定其到哪个分片的),而副本数量则是可以修改的。(es中是不能跨索引联合检索的(不能跨库联合查询))
上面对es的一些概念解释清楚了,下面则对其基本用法进行说明:
1)、建立索引:建立索引一般需要建立settings、mapping(不写es会默认生成,一般推荐自定义)
PUT /test
{"settings" : {"number_of_shards" : 2,"number_of_replicas" : 1}更新其replicas(副本)状态,但是不能更新shards状态
PUT /test/_settings{"number_of_replicas" : 0
}2)、指定id建立索引
(其中_doc是type(类型),es7版本没有type了,即没有表名这个概念了)
(es中索引为库,每个库只有一个表,一个表可以水平拆分为多个表)
(其中1表示,建立id为1的数据)
索引一个文档
保存一个数据,保存在哪个索引的哪个类型下,指定用那个唯一标识 PUT customer/external/1;在customer索引下的external类型下保存1号数据为
PUT customer/external/1
{"name":"John Doe"
}put只能作为全量修改(即将某条数据的所有值都换了)
post可以做部分字段修改(只换传的值,其他值不换)
POST新增。如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
PUT可以新增也可以修改。PUT必须指定id;由于PUT需要指定id,我们一般用来做修改操作,不指定id会报错。
下面是在postman中的测试数据:
创建数据成功后,显示201 created表示插入记录成功。
{"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}这些返回的JSON串的含义;这些带有下划线开头的,称为元数据,反映了当前的基本信息。
"_index": "customer" 表明该数据在哪个数据库下;
"_type": "external" 表明该数据在哪个类型下;
"_id": "1" 表明被保存数据的id;
"_version": 1, 被保存数据的版本
"result": "created" 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。
下面选用POST方式:
添加数据的时候,不指定ID,会自动的生成id,并且类型是新增:
再次使用POST插入数据,仍然是新增的:
添加数据的时候,指定ID,会使用该id,并且类型是新增:
再次使用POST插入数据,类型为updated,版本号变为2
3)查看文档
GET /customer/external/1
http://192.168.137.14:9200/customer/external/1
{"_index": "customer",//在哪个索引"_type": "external",//在哪个类型"_id": "1",//记录id"_version": 3,//版本号"_seq_no": 6,//并发控制字段,每次更新都会+1,用来做乐观锁"_primary_term": 1,//同上,主分片重新分配,如重启,就会变化"found": true,"_source": {"name": "John Doe"}
}通过“if_seq_no=1&if_primary_term=1 ”,当序列号匹配的时候,才进行修改,否则不修改。
实例:将id=1的数据更新为name=1,然后再次更新为name=2,起始seq_no=6,primary_term=1
(1)将name更新为1
http://192.168.137.14:9200/customer/external/1?if_seq_no=6&if_primary_term=1
(2)将name更新为2,更新过程中使用seq_no=6
http://192.168.137.14:9200/customer/external/1?if_seq_no=6&if_primary_term=1
出现更新错误。
(3)查询新的数据
http://192.168.137.14:9200/customer/external/1
能够看到_seq_no变为7。
(4)再次更新,更新成功
http://192.168.137.14:9200/customer/external/1?if_seq_no=7&if_primary_term=1
4)更新文档
(1)POST更新文档,带有_update
http://192.168.137.14:9200/customer/external/1/_update
如果再次执行更新,则不执行任何操作,序列号也不发生变化
POST更新方式,会对比原来的数据,和原来的相同,则不执行任何操作(version和_seq_no)都不变。
(2)POST更新文档,不带_update
在更新过程中,重复执行更新操作,数据也能够更新成功,不会和原来的数据进行对比。
5)删除文档或索引
DELETE customer/external/1
DELETE customer注:elasticsearch并没有提供删除类型的操作,只提供了删除索引和文档的操作。
实例:删除id=1的数据,删除后继续查询
实例:删除整个costomer索引数据
删除前,所有的索引
green open .kibana_task_manager_1 KWLtjcKRRuaV9so_v15WYg 1 0 2 0 39.8kb 39.8kb
green open .apm-agent-configuration cuwCpJ5ER0OYsSgAJ7bVYA 1 0 0 0 283b 283b
green open .kibana_1 PqK_LdUYRpWMy4fK0tMSPw 1 0 7 0 31.2kb 31.2kb
yellow open customer nzDYCdnvQjSsapJrAIT8Zw 1 1 4 0 4.4kb 4.4kb删除“ customer ”索引
删除后,所有的索引
green open .kibana_task_manager_1 KWLtjcKRRuaV9so_v15WYg 1 0 2 0 39.8kb 39.8kb
green open .apm-agent-configuration cuwCpJ5ER0OYsSgAJ7bVYA 1 0 0 0 283b 283b
green open .kibana_1 PqK_LdUYRpWMy4fK0tMSPw 1 0 7 0 31.2kb 31.2kb
6)eleasticsearch的批量操作——bulk
语法格式:
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。
实例1: 执行多条数据
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"John Doe"}执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 491,"errors" : false,"items" : [{"index" : {"_index" : "customer","_type" : "external","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "customer","_type" : "external","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201}}]
}
实例2:对于整个索引执行批量操作
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}运行结果:
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 608,"errors" : false,"items" : [{"delete" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 1,"result" : "not_found","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 404}},{"create" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 2,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "website","_type" : "blog","_id" : "MCOs0HEBHYK_MJXUyYIz","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 201}},{"update" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 3,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1,"status" : 200}}]
}
7)样本测试数据
准备了一份顾客银行账户信息的虚构的JSON文档样本。每个文档都有下列的schema(模式)。
{"account_number": 1,"balance": 39225,"firstname": "Amber","lastname": "Duke","age": 32,"gender": "M","address": "880 Holmes Lane","employer": "Pyrami","email": "amberduke@pyrami.com","city": "Brogan","state": "IL"
}https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json ,导入测试数据,
POST bank/account/_bulk
7、结构化创建索引:简单点将就是自定义mapping等什么(因为自动生成的比较死板)
PUT /test
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"_doc":{"properties": {"name":{"type": "text","analyzer":"ik_max_word","search_analyzer": "ik_smart"},"sname":{"type": "text","analyzer":"ik_smart"},"enname":{"type":"text","analyzer":"english"},"age":{"type": "integer"}}}}
}其中_doc(type,表)在es7中取消了,而properties里进行字段定义。
其中type指字段类型、analyzer指创建索引时用的分词器、search_analyzer指检索时用的分词器(一般创建时用细的分词器,检索时用粗的分词器)
8、分词器的实际使用分析
这里使用analyze对创建索引/检索时分词器的工作进行分析
GET /test/_analyze
{"field": "name","text": "my name is zhaoyun and i like eating apples and running"
}GET /test/_analyze
{"field": "sname","text": "武汉市长江大桥"
}(1)这里使用默认的分词器:stander(中英文都一样)。该分词器会每个字分成一个词,并且分词后不做任何处理
此种分词非常占空间会导致倒排索引很大,而且在搜索的时候也会搜出很多不相干的东西。优点就是搜的多。
(2)英文
English分词器:会提取词干和去掉停用词。
GET /test/_analyze
{"analyzer": "english","text": "my name is zhaoyun and i like eating apples and running"
}改成用english分词器做。就可以看到以下的情况
可以看到running和apples被提取成了词干,提取算法其实就是一个映射感兴趣的同学可以自己取看看。而and 和 is被当作停用词去掉了。
(3)IK分词器:他会有两种模式一种smart,一种max_word。
建索引的时候 用ik_max_word,搜索的时候用smart。如果需要详细理解里面的原理的,请看算法课的第23节课。讲的相当详细。
分词器使用场景:
分词的妙用:
是不是就意味着stander分词没用了?其实并不是这样的哦
#托底,搜江大桥没有,在建了ik的字段,在建一个一样的stander的字段。如果ik搜不到 就可以搜这一个stander分词的,这样保证会又结果。但是慎用,因为占空间,有些特殊的系统可以使用。
#其实ik也还有一个解决的办法 叫砍词:江大桥 我可以砍掉一个词,我砍掉江 就出来了。砍词的策略可以自定义
#江大桥:电商中。我们系统假设有大桥这个品牌。 我会一个个的是去试一下,比如可以用字符串匹配找出大桥。也有很多系统很粗暴,直接从第一个字开始砍,一直砍到有为止。
#既有英文又有中文的 直接选ik
#如果不用砍词那就要去词库加词,比如加入江大桥就可以了。具体路径是在es的:
/config/analysis-ik/main.dic
注意集群的话那就要所有的es都需要加的哦
对于创建索引到检索过程进行总结:
1、创建索引时,先将数据用分词器拆分为多个词,然后再给该条数据指定id并存放到es中
2、检索索引时,根据搜索的数据进行分词,然后跟创建索引时的词进行匹配,匹配到(相等)的话则倒排索引查找到该条数据的id并返回回去。
3、这里需要注意的是:如果查到多条,那么我们需要怎么排序输出?es中又是怎么排序输出的?这些内容在下面说明
三、es的进阶操作
1.建立mapping
原则:
(1)不要使用es默认的mapping,虽然省事但是不合理
(2)字段类型尽可能的精简,因为只要我们建了索引的字段es都会建立倒排,检索时会加载到内存。如果不合理会导致内存爆炸。
(3)有些不要检索的字段不要设置 index:true,es默认时true,其实更推荐大家使用es+mysql(or hbase)等形式,将不需要es存储的字段放在其他的存储介质中,通过唯一标识和es建立映射。
(4)Ik分词在建立的时候要注意:建索引采用ik_max_word 检索采用ik_smart
上面用了analyze进行分析,这里则用另一种分析工具explain
GET /book/_validate/query?explain{"query": {"multi_match": { //multi_match即在"bookName","discription"两个字段中查找"query": "童话故事的大选","fields": ["bookName","discription"]}}}2、Match查询
GET /book/_search{"query": {"match": {"bookName": "童话故事大全" //只在bookName中查询}}}Match对分词进行or 或者 and查询
GET /book/_search{"query": {"match": {"bookName": {"query": "大自然的声音","operator": "and" //即目标数据要同时包含“大自然的声音”分词后的所有词//例分词后是大自然、声音;则目标数据两个都要有//如果这里是or则表示有一个即可}}}}3、Term查询:对检索的数据不进行分词,就直接去倒排索引
GET /book/_search{"query": {"term": {"bookName": {"value": "童话故事大全" //直接用童话故事大全进行倒排索引(不进行分词)}}}}4、最小匹配查询:
GET /book/_analyze{"field": "bookName","text": "安徒生的大自然童话故事"}GET /book/_search{"query": {"match": {"bookName": {"query": "安徒生的大自然童话故事","operator": "or","minimum_should_match": 2 //至少包含"安徒生的大自然童话故事"分词后的两个词}}}}5、再谈tf-idf:如果此时去查询该语句,则会出现一个"_score" 字段,该字段即表示某条数据中bookName字段所占比分
es会根据不同的方式将这些比分进行计算后得出那些数据放在前面,哪些放在后面
GET /book/_search{"explain": true,"query": {"match": {"bookName": "故事大全"}}}多字段联合查询时:
多字段查询:
GET /book/_search{"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName","discription"]}}}es会根据不同字段的比分进行计算最后将数据进行排序输出。
主要有以下几种
1)、多字段添加权重:
GET /book/_search{"explain": true,"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName^10","discription"] //这样bookName的比分乘于10后,该字段在整体得分比重就提升了}}}2)平滑一下 更加突出权重:
GET /book/_search{"explain": true,"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName^10","discription"],"tie_breaker": 0.3 // max plus 0.3 times others of,最大值加上其他值的0.3倍例如bookName是所有字段中的最大值,此时则拿到其他字段的值乘于0.3,然后bookname+该值}}}3)取最好的字段:
GET /book/_search{"explain": true,"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName","discription"], //即取数据中哪个字段的比分的最大值作为数据的比分
//例bookename有:1、3、5,discription有:2、5、6 则这条数据分值为6"type": "best_fields"}}}4)、多字段分值相加
GET /book/_search{"explain": true,"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName","discription"], //所有字段比分值相加作为数据比分
1、3、5 和 2、4、6 则数据比分为1+2+3+4+5+6"type": "most_fields"}}}5)、以分词为单位分别在每个字段里面得分取最大的相加,非常适用于以词作为权重的系统
GET /book/_search{"explain": true,"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName","discription"],//1、3、5和2、4、6 则数据分值为5+6"type": "cross_fields"}}}6、queryString:简单查询中经常使用,可以配合 AND OR NOT 使用
GET /book/_search{"query": {"query_string": {"fields": ["bookName"],"query": "大自然 AND 旅行" //这里进行and操作}}}7、Bool查询:
Must:所有的条件都是ture
Must not:所有的条件都是false
Should:在其条件中只要有一个为ture即可,但是true越多的排在越前面
1)、Should查询:
GET /book/_search
{"query": {"bool": {"should": [ //搜索结果满足其中一个即可{"match": {"bookName": "安徒生"}},{"match": {"discription": "丑小鸭"}}]}}
}8、Filter查询:使用order过滤,避免没有分数
GET /book/_search
{"query": {"bool": {"filter": [{"range": {"commentNum": {"lte": 2000, //commentNum的值最大2000、最小1"gte": 1}}},{"term": {"author":"朱奎"}}]}} ,"sort": [{"commentNum": {"order": "desc"}}]带打分的match(must,用should如果不满足也会执行filter等,所有出来的数据是没有打分的(非通过should出来的数据))
GET /book/_search
{"query": {"bool": {"must": [{"match": {"bookName": "先生"}}],"filter": [{"range": {"commentNum": {"lte": 2000,"gte": 1}}},{"term": {"author":"王德启,王晶/著"}}]}}
}此时如果must不成立则没有结果返回,如果换成shuld看看结果我们发现有结果返回,所以bool中如果有filter即使should都不满足还是回去执行filter 的,只不过全是0分而已。
9、Function Score:
GET /book/_search
{"query": {"function_score": {"query": {"multi_match": {"query": "大自然的旅行故事","fields": ["bookName","discription"],"operator": "or","type": "most_fields"}},"functions": [{"field_value_factor": {"field": "commentNum","modifier": "log2p", "factor": 8}}],"score_mode": "sum","boost_mode": "sum"}}
}查全率:正确的结果有n个,但查出来的正确的有m个
查准率:查出n个文档有m个正确
两者不可兼得,但可以调整排序来优化:Function score.
Score字段:
10、同义词处理:例iphone和苹果、apple
在词库加上苹果、iphone、apple同义词处理
PUT /test11
{"settings": {"number_of_replicas": 1,"number_of_shards": 1,"analysis": {"filter": {"my_synonym_filter": {"type": "synonym","synonyms_path": "analysis-ik/synonyms.txt" //同义词词库地址}},"analyzer": { //自定义分词器设置"ik_syno": { "type": "custom","tokenizer": "ik_smart","filter": ["my_synonym_filter" //自定义过滤器]},"ik_syno_max": {"type": "custom","tokenizer": "ik_max_word","filter": ["my_synonym_filter"]}}}},"mappings": {"_doc": {"properties": {"name": {"type": "text","analyzer": "ik_syno_max","search_analyzer": "ik_syno"}}}}
}PUT /test11/_doc/1
{"name":"苹果"
}GET /test11/_search
{"query": {"match": {"name": "apple"}}
}12、Aggregation(执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL Group by和SQL聚合函数。在elasticsearch中,执行搜索返回this(命中结果),并且同时返回聚合结果,把以响应中的所有hits(命中结果)分隔开的能力。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API啦避免网络往返。
"size":0
size:0不显示搜索数据 aggs:执行聚合。聚合语法如下:
"aggs":{"aggs_name这次聚合的名字,方便展示在结果集中":{"AGG_TYPE聚合的类型(avg,term,terms)":{}}
},搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{"query": {"match": {"address": "Mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"ageAvg": {"avg": {"field": "age"}},"balanceAvg": {"avg": {"field": "balance"}}},"size": 0
}查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38,"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]},"ageAvg" : {"value" : 34.0},"balanceAvg" : {"value" : 25208.0}}
}
复杂: 按照年龄聚合,并且求这些年龄段的这些人的平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},"aggs": {"ageAvg": {"avg": {"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 49,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"ageAvg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"ageAvg" : {"value" : 25269.583333333332}},{"key" : 26,"doc_count" : 59,"ageAvg" : {"value" : 23194.813559322032}},{"key" : 32,"doc_count" : 52,"ageAvg" : {"value" : 23951.346153846152}},{"key" : 35,"doc_count" : 52,"ageAvg" : {"value" : 22136.69230769231}},{"key" : 36,"doc_count" : 52,"ageAvg" : {"value" : 22174.71153846154}},{"key" : 22,"doc_count" : 51,"ageAvg" : {"value" : 24731.07843137255}},{"key" : 28,"doc_count" : 51,"ageAvg" : {"value" : 28273.882352941175}},{"key" : 33,"doc_count" : 50,"ageAvg" : {"value" : 25093.94}},{"key" : 34,"doc_count" : 49,"ageAvg" : {"value" : 26809.95918367347}},{"key" : 30,"doc_count" : 47,"ageAvg" : {"value" : 22841.106382978724}},{"key" : 21,"doc_count" : 46,"ageAvg" : {"value" : 26981.434782608696}},{"key" : 40,"doc_count" : 45,"ageAvg" : {"value" : 27183.17777777778}},{"key" : 20,"doc_count" : 44,"ageAvg" : {"value" : 27741.227272727272}},{"key" : 23,"doc_count" : 42,"ageAvg" : {"value" : 27314.214285714286}},{"key" : 24,"doc_count" : 42,"ageAvg" : {"value" : 28519.04761904762}},{"key" : 25,"doc_count" : 42,"ageAvg" : {"value" : 27445.214285714286}},{"key" : 37,"doc_count" : 42,"ageAvg" : {"value" : 27022.261904761905}},{"key" : 27,"doc_count" : 39,"ageAvg" : {"value" : 21471.871794871793}},{"key" : 38,"doc_count" : 39,"ageAvg" : {"value" : 26187.17948717949}},{"key" : 29,"doc_count" : 35,"ageAvg" : {"value" : 29483.14285714286}}]}}
}查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},"aggs": {"genderAgg": {"terms": {"field": "gender.keyword"},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}},"ageBalanceAvg": {"avg": {"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 119,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"genderAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balanceAvg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balanceAvg" : {"value" : 26626.576923076922}}]},"ageBalanceAvg" : {"value" : 28312.918032786885}}].......//省略其他}}
}
部分参考:https://blog.csdn.net/hancoder/article/details/107612746







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有