一.生成器
1 def func():
2 print("111")
3 return 222
5 ret = func()
6 print(ret)
7 #结果
8 111
9 222
1)这里面函数体里是返回值return;如果将return换成yield就是生成器
1 def func():
2 print("111")
3 yield 222
4 ret = func()
5 print(ret)
6 #输出结果
7
如果函数中包含了yield,那这个函数就是生成器了
所以:a;return直接返回结果,结束函数的调用
b:返回结果,可以让函数分段执行
关于生成器的的小坑;
1 def func():
2 i = 1
3 while i <1000000:
4 yield "%s" % i
5 i += 1
6 print(func().__next__())#不是同一个生成器,开辟了一个新空间
7 print(func().__next__())#相当于一个新的生成器从第一步执行,相当于格式化了func()中的所有东西
8 print(func().__next__())
9 #1,1,1
10 为什么会不变呢,因为执行每一次print,都相当于重新拿了一个生成器,
11 然后从头开始找第一个yield;
生成器是不能进行赋值运算的;所以正确格式:上下两个程序少了一个func = func()
1 def func():
2 i = 1
3 while i <1000000:
4 yield "%s" % i
5 i += 1
6 func = func()
7 print(func.__next__())#不是同一个生成器
8 print(func.__next__())#相当于一个新的生成器从第一步执行
9 print(func.__next__())
10 #输出结果:
11 1,2,3
2)生成器的作用
1 #代码一
2 def cloth1():
3 lst = []
4 for i in range(10000):
5 lst.append(i)
6 return lst
7 c1 = cloth1()
8 #代码二
9 def cloth():
10 for i in range(100000):
11 yield \'衣服\' + str(i+1)
12 c = cloth()
13 for i in range(10):
14 print(c.__next__())
这两段代码差别之处,就是代码一一下子就提取了10000个数,太耗内存;
代码二:是可以控制的,我要几个,你给我几个;惰性机制;
二.send和.next()的区别
1.还是上面的程序,你用._next_()的话,会直接一次性全拿出来值,会很占用内存,生成器的话,是可控的,一个一个
指下去,不会回去,下一次继续获取指针指向的值;
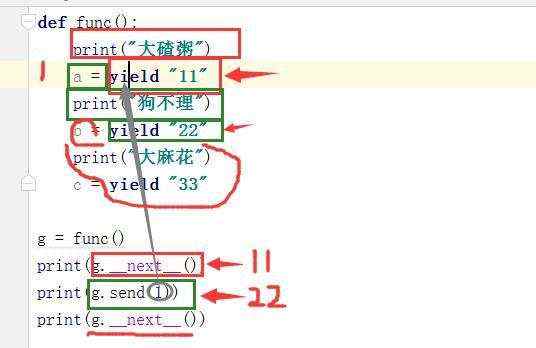
这里面send是怎么运行的,第一行._next_()是运行到红色范围的yield,然后print(g.send(1))是函数func
从a开始执行到下一个yield "22",然后把send的里面的1赋值给a;
代码展示:
1 def func():
2 print("大碴粥")
3 a = yield "11"
4 print(a)
5 print("狗不理")
6 b = yield "22"
7 print(b)
8 print("大麻花")
9 c = yield "33"
10
11 g = func()
12 print(g.__next__())
13 print(g.send(1))
14 print(g.__next__())
15 #输出结果
16 大碴粥
17 11
18 1 #这是send里面的1赋值给了a
19 狗不理
20 22
21 None #因为b是._next_()执行的,没用进行赋值,所以为None
22 大麻花
23 33
注意:第一个不能用send(),最后一个也不要传值;
三.列表推导式,生成器表达式以及其他推导式
1.列表推导式
平常代码:
1 lst = []
2 for i in range(1,16):
3 lst.append(i)
4 print(lst)
5 #输出结果
6 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
替换成列表推导式
lst = [i for i in range(1,16)]
print(lst)
#输出结果
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
这里的lst直接相当于append进行的添加;
1 lst = ["python%d" % i for i in range(1,16)]
2 print(lst)
3 #输出结果
4 [\'python1\', \'python2\', \'python3\', \'python4\', \'python5\', \'python6\', \'python7\', \'python8\', \'python9\', \'python10\', \'python11\', \'python12\', \'python13\', \'python14\', \'python15\']
1 判断列表中的有两个e的元素
2 names = [[\'Tom\', \'Billy\', \'Jefferson\' , \'Andrew\' , \'Wesley\' , \'Steven\' ,
3 \'Joe\'],[\'Alice\', \'Jill\' , \'Ana\', \'Wendy\', \'Jennifer\', \'Sherry\' , \'Eva\']]
4 lst = [name for index in names for name in index if name.count("e") == 2]
5 print(lst)
6 #输出结果
7 [\'Jefferson\', \'Wesley\', \'Steven\', \'Jennifer\']
2.生成器推导式
a:生成器表达式和列表推导式基本一致,只是把[]替换成了()
gen = (i for i in range(10))
print(gen) #输出结果得到的是一串地址,你要用._next_()才能一步一步执行生成器;
生成器表达式和列表推导式两者的区别就是前者是惰性机制,要一个给一个,后者是一次性生成,比较耗内存;
b:生成器的惰性机制
上代码:
*************深坑请留意*************
1 def func():
2 print(111)
3 yield 222
4 g = func() #生成器g
5 g1 = (i for i in g) #生成器g1,for循环只是让g变成了一个迭代器,而没有向它取值
6 g2 = (i for i in g1) #生成器g2,跟g1相似,没有东西让他取值,就不运行
7 print(list(g)) #list内部有一个append,我跟你生成器要值了,你会运行你的函数
8 print(list(g1)) #而._next_()只是生成器要值后执行的语句,
9 print(list(g2))
10 #输出结果
11 111
12 [222]
13 []
14 []
这里面第一个print里面的list(g)相当于list.append()向g要值了,g才会去调用函数,就是你第四行的代码该运行
运行,但是就是不调用我的函数,你就只调用我的变量g,而不执行g;
而当运行第二个print里面的list(g1)时,执行g1=(i for i in g)时,g._next_()已经运行到最后一个yield了,
所以g1再迭代g,已经取不到值了.所以为空列表;
c:字典的生成器格式
ls1 = [1,2,3,4,5] ls2 = [5,6,7,8,9]
dic = {ls1[i]:ls2[i] for i in range(len(ls1))}
d:总结 推导式有:列表推导式,字典推导式,集合推导式,没有元组推导式
面试题:
1 def add(a,b):
2 return a+b
3 def test():
4 for i in range(4):
5 yield i
6 g = test()
7 for n in [2,10]:
8 g = (add(n,i) for i in g)
9 \'\'\'
10 执行效果
11 n = 2
12 g = (add(n,i) for i in test())
13 n = 10
14 g = (add(n,i) for i in ((add(n,i) for i in test()))
15 这里一直没有取值操作,所以不会执行test()函数,而取n值的时候,是最后一步
16 才取的n值,你要带入了,我给你值,否则你就一直用我的变量带入吧;
17 \'\'\'
18 print(list(g))
19 #输出结果
20 [20, 21, 22, 23]











 京公网安备 11010802041100号
京公网安备 11010802041100号