小谈:一直想整理机器学习的相关笔记,但是一直在推脱,今天发现知识快忘却了(虽然学的也不是那么深),但还是浅浅整理一下吧,便于以后重新学习。
最近换到新版编辑器写文章了,有的操作挺方便的,但是😭我目前还没有找到在哪里插入目录。
📙参考:ysu期末复习资料和老师的课件
目录
1.机器学习的定义
2.机器学习的发展历程
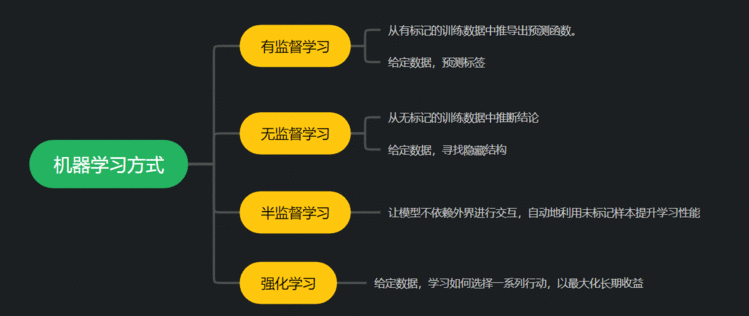
3.监督学习、半监督学习和无监督学习的特点
3.1 监督学习
3.2 无监督学习
3.3 半监督学习
3.4 强化学习
4.机器学习的一般流程
4.1 数据预处理
4.1.1 数据清洗
4.1.2数据采样
4.1.3 数据集拆分
4.2 特征工程
4.2.1 特征编码
4.2.2 特征选择
4.3 数据建模
4.4 结果评估
机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构使之不断改善自己的性能。
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进,通过参数优化的学习模型,能够用于预测相关问题的输出。
推理期→知识期→学科形成→繁荣期
从给定的有标注的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。
常见任务:包括分类与回归。
没有标注的训练数据集,需要根据样本间的统计规律对样本集进行分析
常见任务:聚类
结合(少量的)标注训练数据和(大量的)未标注数据来进行数据的分类学习。
半监督学习可进一步分为纯半监督学习和直推学习,前者假定训练数据中的未标记样本并非待测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
基于环境的反馈而行动,通过不断与环境交互、试错,使整体行动收益最大化,强化学习不需要训练数据的Label,但是它需要每一步行动环境给予的反馈,是奖励还是惩罚,基于反馈不断调整训练对象的行为。
(强化学习接触的很少,以后遇到会补充)
数据预处理→特征工程→数据建模→结果评估
数据预处理:数据清洗、数据集成、数据采样
数据清洗:对各种脏数据进行对应方式的处理,得到标准、干净、连续的数据,提供给数据统计,数据挖掘等使用。
确保数据的五个性质:完整性、合法性、一致性、唯一性、权威性!
数据清洗要保证:数据的完整性、数据的合法性、数据的一致性、数据的唯一性、数据的权威性
(这个期末考试考到了,没有写上一致性😶)
解析一下数据的一致性吧:
不同来源的不同指标,实际内涵是一样的,或是同一指标内涵不一致。
解决方法:建立数据体系,包含但不限于指标体系、维度、单位等
(1)数据不平衡
数据不平衡,指数据集的类别分布不均。
(2)解决方法
解决方法:过采样(Over-Sampling)、欠采样(Under-Sampling)
过采样:通过随机复制少数类来增加其中的实例数量,从而可增加样本中少数类的代表性。
欠采样:通过随机地消除占多数的类的样本来平衡类分布,直到多数类和少数类的实例实现平衡。
(1)常将数据划分为3份
(2)常用拆分方法
特征工程:特征编码、特征选择、特征降维、规范化
数据集中经常会出现字符串信息,例如男女、高中低等,这类信息不能直接用于算法计算,需要将这些数据转化为数值形式进行编码,便于后期进行建模。
比如:
ont-hot编码:
语义编码:
不是所有属性特征都有用。
按照发散性或相关性对各特征进行评分,设定阈值完成特征选择。
互信息:指两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量的确定性。
所以,互信息取值最小为0,意味着给定一个随机变量对,确定和另一个随机变量没有关系,越大表示另一个随机变量的确定性越高。
选定特定算法,然后通过不断的启发式方法来搜索特征。
利用正则化的思想,将部分特征属性的权重调整到0,则这个特征相当于就是被舍弃了。
常见的正则有L1的Lasso,L2的Ridge,和一种综合L1和L2这两个方法的Elastic Net方法。
数据建模:回归问题、分类问题、聚类问题、其他问题
结果评估:拟合度量、查准率、查全率、F1值、PR曲线、ROC曲线













 京公网安备 11010802041100号
京公网安备 11010802041100号