作者:手机用户2602890095 | 来源:互联网 | 2023-09-17 20:50
Hadoop是Apache 下的一个项目,由HDFS、MapReduce、HBase、Hive 和ZooKeeper等成员组成。其中,HDFS 和MapReduce 是两个最基础最重要的成员。
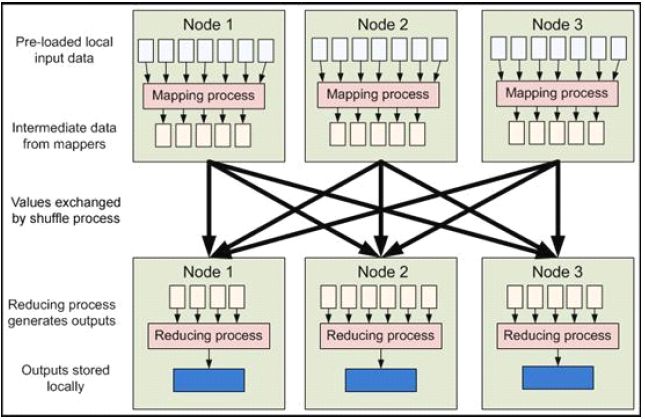
HDFS是Google GFS 的开源版本,一个高度容错的分布式文件系统,它能够提供高吞吐量的数据访问,适合存储海量(PB 级)的大文件(通常超过64M),其原理如下图所示:
#
采用Master/Slave 结构。NameNode 维护集群内的元数据,对外提供创建、打开、删除和重命名文件或目录的功能。DatanNode 存储数据,并提负责处理数据的读写请求。DataNode定期向NameNode 上报心跳,NameNode 通过响应心跳来控制DataNode。
MapReduce 是大规模数据(TB 级)计算的利器,Map 和Reduce 是它的主要思想,来源于函数式编程语言,它的原理如下图所示:Map负责将数据打散,Reduce负责对数据进行聚集,用户只需要实现map 和reduce 两个接口,即可完成TB级数据的计算,常见的应用包括:日志分析和数据挖掘等数据分析应用。另外,还可用于科学数据计算,如圆周率PI 的计算等。Hadoop MapReduce的实现也采用了Master/Slave 结构。Master 叫做JobTracker,而Slave 叫做TaskTracker。用户提交的计算叫做Job,每一个Job会被划分成若干个Tasks。JobTracker负责Job 和Tasks 的调度,而TaskTracker负责执行Tasks。
MapReduce中的Shuffle和Sort分析
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme,ML 等。MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。从高层抽象来看,MapReduce的数据流图如图1 所示:
#
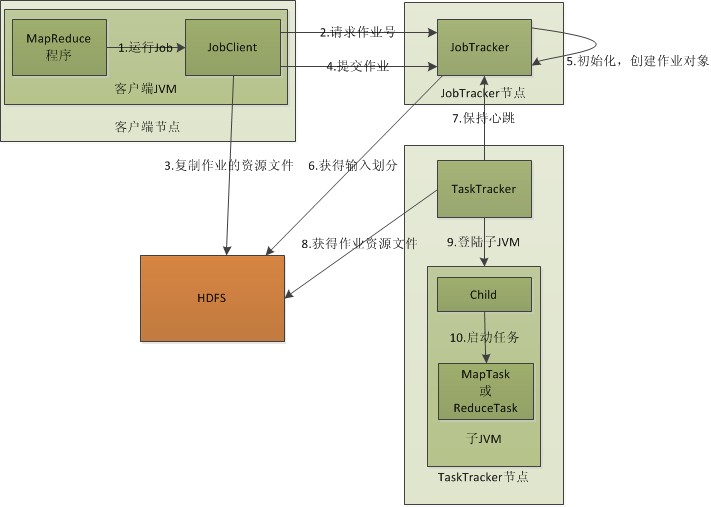
MapReduce作业运行流程:
#
本文的重点是剖析MapReduce的核心过程----Shuffle和Sort。在本文中,Shuffle是指从Map产生输出开始,包括系统执行排序以及传送Map输出到Reducer作为输入的过程。在这里我们将去探究Shuffle是如何工作的,因为对基础的理解有助于对MapReduce程序进行调优。
--------------------------------------分割线 --------------------------------------
Ubuntu 13.04上搭建Hadoop环境 2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置 2013-09/90600.htm
Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) 2013-01/77681.htm
Ubuntu下Hadoop环境的配置 2012-11/74539.htm
单机版搭建Hadoop环境图文教程详解 2012-02/53927.htm
搭建Hadoop环境(在Winodws环境下用虚拟机虚拟两个Ubuntu系统进行搭建) 2011-12/48894.htm
--------------------------------------分割线 --------------------------------------
首先从Map端开始分析,当Map开始产生输出的时候,他并不是简单的把数据写到磁盘,因为频繁的操作会导致性能严重下降,他的处理更加复杂,数据首先是写到内存中的一个缓冲区,并作一些预排序,以提升效率,如图:
#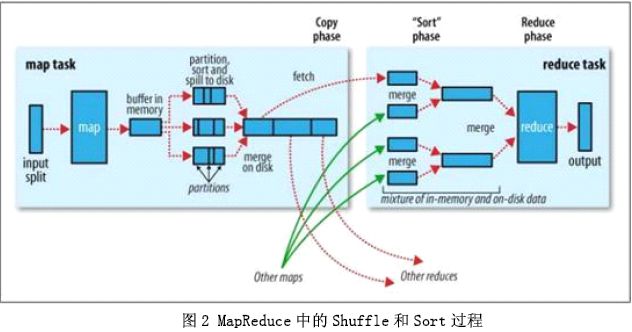
每个Map任务都有一个用来写入输出数据的循环内存缓冲区,这个缓冲区默认大小是100M,可以通过io.sort.mb属性来设置具体的大小,当缓冲区中的数据量达到一个特定的阀值(io.sort.mb * io.sort.spill.percent,其中io.sort.spill.percent 默认是0.80)时,系统将会启动一个后台线程把缓冲区中的内容spill 到磁盘。在spill过程中,Map的输出将会继续写入到缓冲区,但如果缓冲区已经满了,Map就会被阻塞直道spill完成。spill线程在把缓冲区的数据写到磁盘前,会对他进行一个二次排序,首先根据数据所属的partition排序,然后每个partition中再按Key排序。输出包括一个索引文件和数据文件,如果设定了Combiner,将在排序输出的基础上进行。Combiner就是一个Mini Reducer,它在执行Map任务的节点本身运行,先对Map的输出作一次简单的Reduce,使得Map的输出更紧凑,更少的数据会被写入磁盘和传送到Reducer。Spill文件保存在由mapred.local.dir指定的目录中,Map任务结束后删除。
更多详情见请继续阅读下一页的精彩内容: 2014-09/107138p2.htm



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号
京公网安备 11010802041100号