各种分布式全局唯一ID生成算法汇总大全(共12种);设计分布式微服务系统,面试看这篇就够了。
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。在系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;此时一个能够生成全局唯一ID的系统是非常必要的。概括下来,那业务系统对ID号的要求有哪些呢?
1. 全局唯一性:不能出现重复的ID号,保证生成的 ID 全局唯一,这是最基本的要求。
2. 趋势递增:有利于保证DB插入、查询等操作的性能。
3. 单调递增:保证下一个ID一定大于上一个ID,例如版本号、排序等特殊需求。
4. 信息安全:如果ID是连续的,容易被猜测出url,ID号码的数量,对业务产生影响。所以在一些应用场景下,会需要ID无规则、不规则。
上述需求对应不同的场景,3和4需求还是互斥的,无法使其在同一个方案满足。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,整个电商系统都无法完成业务,这就会带来一场灾难。
由此总结出一个ID生成系统应该做到如下几点:
1. 平均延迟和TP999延迟都要尽可能低;
2. 可用性5个9;
3. 高QPS。
划重点了:如果前9种,你都看过了,就直接跳到第10种看吧。
分段模式与雪花到底有什么区别?
一个是依赖DB,一个是依赖时间的.
能不能找到一种,既不依赖DB,也不依赖时间的算法呢?答案是,肯定有的,找吧(本文就能找到)!
DB表自增ID真的不能用在分布式场景吗? 不要让前人把你的思维带偏了!
以下,将为大家讲解各种分布式全局唯一ID生成算法(共12种)。
-
基于数据库自增ID(单个DB)
-
基于数据库自增ID(主从DB结构)
-
UUID 全球唯一,但生成的是字符串。
-
Redis
-
号段模式
-
twitter snowflake Twitter时钟回拨时直接抛异常。时钟回拨时会不可用。
-
美团leaf: 该篇文章详细的介绍了snowflake和db号段方案,近期也进行了Leaf开源。
还可以完善的地方:
没有:连续单调递增ID生成方案;没有批量获取ID号的方法。
snowflake弱化毫秒的时钟回拨,默认能容错5毫秒,避免润秒问题要在外部调用100次。弱依赖Zookeeper分配workerid. 返回结果用Result结构包装,会影响一点性能。时钟回拨时会不可用。
workerid有重复时,会有重号风险。workerid分配方案提供ZooKeeper,但想改其它分配方案需要改源码。
db号段模式属于依赖DB的号段模式,一次取一个号段的ID,减少对ID的访问。
8. 百度uid-generator: 这是基于snowflake方案实现的开源组件. 支持容器重启,workerid用后即弃,机器id占22位,最多可支持约419w次机器启动。
sequence (13 bits)每秒下的并发序列,13 bits可支持每秒8192个并发。
缺点:机器号占太多位,每个时间点能用的号码太少。
9. tinyid :属于依赖DB的号段模式,一次取一个号段的ID,减少对ID的访问。
全局唯一的long型id
趋势递增的id,即不保证下一个id一定比上一个大
非连续性(不支持:连续单调递增ID)
优点:
支持批量获取id
支持多个db的配置,无单点
适用场景:只关心id是数字,趋势递增的系统,可以容忍id不连续,有浪费的场景
缺点:
不适用场景:类似订单id的业务(因为生成的id大部分是连续的,容易被扫库、或者测算出订单量)
作为分布式DB表主键,不是特别合适。不支持,连续单调递增ID,依赖DB。
以上几种算法还存在的问题。
依赖DB分段批量获取的算法,是可以产生全局唯一,且批内连续单调递增的ID。但多个请求分别调用生成一批,多个批都插入数据到库,还是不会连续的。强依赖DB。
雪花生成的是不连续,全局唯一,但只能是趋势递增的ID,部分区间连续,整体不连续。过于依赖时间。
因此又延伸出以下三种算法。
10. 梨花算法:改进的雪花算法,弱依赖时间,对毫秒不敏感,可以允许2分钟即120秒的时钟回拨(实际上可以根据业务场景设置更长或更短的容错时间),可以轻松避免润秒问题。workerid默认从配置文件获取,代码架构可方便扩展workerid分配算法,能处理workerid冲突问题。可提前消费1秒。。。
返回结果用原生long返回&#xff0c;异常使用小于0&#xff08;<0&#xff09;的数表示。
workerid有重复时&#xff0c;会有重号风险。应该选择合适的workerid分配方案避免。
支持批获取ID号.
梨花算法&#xff0c;原文介绍链接。
源码&#xff1a;
https://github.com/automvc/bee/blob/master/src/main/java/org/teasoft/bee/distribution/GenId.java
11. 连续单调递增全局唯一的ID生成算法SerialUniqueId&#xff1a;不依赖于时间&#xff0c;也不依赖于任何第三方组件&#xff0c;只是启动时&#xff0c;用一个时间作为第一个ID设置的种子&#xff0c;设置了初值ID后&#xff0c;就可获取并递增ID。在一台DB内与传统的一样&#xff0c;连续单调递增&#xff08;而不只是趋势递增&#xff09;&#xff0c;而代表DB的workerid作为DB的区号放在高位(类似电话号码的国际区号&#xff09;&#xff0c;从所有DB节点看&#xff0c;则满足分布式DB生成全局唯一ID。本地&#xff08;C8 I7 16g&#xff09;1981ms可生成1亿个ID号,利用上批获取&#xff0c;分隔业务&#xff0c;每秒生成过10亿个ID号不成问题&#xff0c;能满足双11的峰值要求。
可用作分布式DB内置生成64位long型ID自增主键(数据库能更新功能&#xff0c;为我们生成第一个ID最好。不能的话&#xff0c;我们就自己根据算法设置第一个ID)。只要按本算法设置了记录的ID初值&#xff0c;然后默认让数据库表id主键自增就可以&#xff08;如MYSQL&#xff09;。这样&#xff0c;不管是多少个节点插入到该DB的数据&#xff0c;记录的ID都是连续单调递增的。而从全局看&#xff0c;因为workerid不一样&#xff0c;多个数据库间的ID又不会重复。像中国的号码是:12345678,美国的号码也是12345678,但国际区号不一样&#xff0c;号码也就不一样。比如这样100-12345678&#xff0c;101-12345678。
有的人设计软件系统时&#xff0c;即使当初设计的是单体系统&#xff0c;为了让以后DB能适应分布式环境&#xff0c;主键不会重复&#xff0c;使用了UUID的字符生成形式&#xff0c;从而牺牲了数字id的优越性能。其实何须这样呢&#xff01;只需要按本算法设置了记录的ID初值&#xff0c;然后默认让数据库表id主键自增就可以啦。DB表id主键自增不能用在分布式场景——这是之前的一种错误认识。
可以一次取一批ID&#xff08;即一个范围内的ID一次就可以获取了&#xff09;。是不是可以取代依赖DB的号段模式呢!!
对于单点问题&#xff0c;提供高可用解决方案。将该算法打包成一个服务替换<依赖DB的号段模式>中的DB即可&#xff0c;服务与服务调用&#xff0c;无数据库IO开销&#xff0c;从而提高了性能。 &#xff08;但这样就不能连续单调了&#xff0c;但也总比之前的号段模式&#xff0c;要依赖DB好吧!&#xff09;。
使用国际电话号码作类比说明。只不过是用二进制还看得比较清楚。
国际区号&#43;本国&#xff08;地区&#xff09;号码
为什么在一个国家或地区的电话号码不会重复&#xff1f;为什么在国际上一个国家或地区的电话号码还是不会重复&#xff1f;国际区号放在电话号码的最高位部分&#xff0c;只要一国内电话号码不会重复&#xff0c;不同国家用不同的区号&#xff0c;在国际上&#xff0c;电话号码还是不会重复。连续单调递增唯一ID生成算法与这个例子也类似。
绝对全局连续单调递增的DB表主键解决方案&#xff1f;&#xff1f;&#xff1a;
绝对全局连续单调递增的方案不存在。如(1,2,3,…10)分到5个DB&#xff0c;则每个库的ID为&#xff1a;
DB1&#xff08;1,6&#xff09;, DB2&#xff08;2,7&#xff09;, DB3&#xff08;3,8&#xff09;, DB4&#xff08;4,9&#xff09;, DB5&#xff08;5,10&#xff09;
或者&#xff1a;
DB1&#xff08;1,2&#xff09;, DB2&#xff08;3,4&#xff09;, DB3&#xff08;5,6&#xff09;, DB4&#xff08;7,8&#xff09;, DB5&#xff08;9,10&#xff09;
要么总体有序&#xff0c;在各个库趋势递增&#xff1b;要么各个库内连续有序&#xff0c;但各部分DB1绝对连续单调递增&#xff0c;全局唯一的方案&#xff0c;如下&#xff1a;
只能是在新增一个库时&#xff0c;就分配一个库的workerid. 然后在初始化表时&#xff0c;设置初始ID开始用的值&#xff0c;以后由DB自动增长。Workerid的分配可统一放在一个配置文件&#xff0c;由工具检测到某个表是空表&#xff0c;且使用的主键对应的是Java的long型时&#xff0c;设置初始ID开始用的值。
当用作表ID的主键时&#xff0c;可以在表结构创建时&#xff0c;设置不同数据源表主键开始用的ID初值。风险几乎没有&#xff0c;保证100%不重号。
内存生成时&#xff0c;可间隔一定时间(如3分钟&#xff09;缓存当前ID值到文件&#xff0c;供重启时设置回初值用。新ID初始值&#61;缓存的ID值&#43;间隔时间会生成的ID数量最大值。重启会浪费一个间隔时间生成的ID号。
源码&#xff1a;
https://github.com/automvc/bee/blob/master/src/main/java/org/teasoft/bee/distribution/GenId.java
https://github.com/automvc/honey/blob/master/src/main/java/org/teasoft/honey/distribution/SerialUniqueId.java
12. 不依赖时间的梨花算法OneTimeSnowflakeId:
进一步改进第10点提到的梨花算法。
通过代码调用生成ID插入DB的&#xff0c;需要整体有序性。不依赖时间的梨花算法&#xff0c;Workerid应放在序号的上一段&#xff0c;且应用SerialUniqueId算法&#xff0c;使ID不依赖于时间自动递增。使用不依赖时间的梨花算法&#xff0c;应保证各节点大概均衡轮流出号&#xff0c;这样入库的ID会比较有序&#xff0c;因此每个段号内的序列号不能太多。
支持批获取ID号。可以一次取一批ID&#xff08;即一个范围内的ID一次就可以获取了&#xff09;。是不是可以取代依赖DB的号段模式呢!!
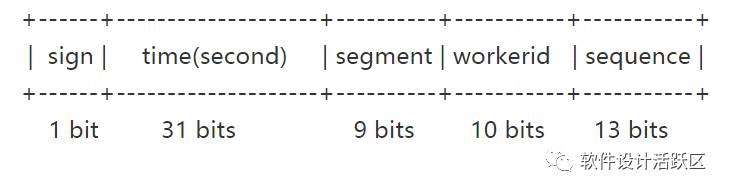
可间隔时间缓存时间值到文件&#xff0c;供重启时设置回初值用。若不缓存&#xff0c;则重启时&#xff0c;又用目前的时间点&#xff0c;重设开始的ID。只要平均不超过419w/s&#xff0c;重启时造成的时钟回拨都不会有影响&#xff08;但却浪费了辛苦攒下的每秒没用完的ID号&#xff09;。要是很多时间都超过419w/s&#xff0c;证明你有足够的能力做这件事&#xff1a;间隔时间缓存时间值到文件。
详细代码&#xff0c;可查看源码:
https://github.com/automvc/honey/blob/master/src/main/java/org/teasoft/honey/distribution/OneTimeSnowflakeId.java
总结1&#xff1a;
应用场景区别&#xff1a;主键ID一般需要连续递增&#xff1b;但订单ID为了安全则不需要太有序。
按是否可以浪费ID区别&#xff1a;
1.浪费ID&#xff0c;
2.不浪费ID&#xff1b;
2.1可以不强依赖于时间;用完时间自动加1秒;
2.2可以不强依赖于时间&#xff0c;当将Workid放最高位部分时&#xff0c;则可以在Workerid内连续单调递增
总结2&#xff1a;
分段模式与雪花到底有什么区别&#xff1f;
一个是依赖DB,一个是依赖时间的.
一个是取的号码可以一直连续递增的&#xff1b;一个是趋势递增&#xff0c;会因workerid的原因产生的ID号是会跳很大一段的.
依赖于DB的号段模式&#xff0c;当多个节点一起拿号时&#xff0c;最终落库的ID还是不能连续的。
雪花ID适合做分布式数据库表主键吗&#xff1f;它只保证递增&#xff0c;没保证连续。
能不能找到一种&#xff0c;既不依赖DB&#xff0c;也不依赖时间的算法呢&#xff1f;答案是&#xff0c;肯定有的&#xff0c;找吧&#xff01;
SerialUniqueId,可以代替分段模式类的算法&#xff0c;随机丢弃部分批量号码&#xff08;成为不连续&#xff09;还可以代替雪花类算法。
OneTimeSnowflakeId可以代替雪花类算法(设置每个段开始的第一个ID号码随机生成&#xff0c;即可不暴露实际使用的ID数量)。
这个都被大家忽略了:
DB表自增ID&#xff0c;也是可以改成分布式特性的&#xff0c;SerialUniqueId就是&#xff01;
---------------------------------------
北有中关村&#xff0c;南有科技园。一个南漂在深圳一线的IT小哥&#xff0c;资深工程师也罢&#xff0c;架构师也罢&#xff0c;我独喜欢软件设计&#xff01;带你了解最前沿的软件设计思想与技术。

长按二维码可关注(公众号: AiTeaSoft)
更多重磅文章等着你!





![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号