对拿到的一堆数据,可以通过KDE方法来估计概率密度,Parzen 窗方法通过使用不同的窗口作为基底,用函数逼近的思路来逼近真实的分布函数,混合高斯模型,同样也用了多个高斯分布做了线性组合来拟合隐含的分布,看起来高斯混合模型也可以用来做概率密度估计,那么到底这两者之间是否是相似的呢?又或者有什么不同呢
混合高斯模型:
其中 N 表示 Component 的个数,也就是由多少个高斯分布来进行混合,
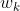
表示每一个Component的权重,它是一个概率意义上的量,代表了一个观测数据由第i个Component生成的概率,因此
其中,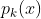 代表了第k个Component的概率密度函数
代表了第k个Component的概率密度函数
从这个公式上面可以看到,一般高斯混合模型的用途是用来做分类判别用,第k个Component代表了第k类,如果我们已经有了第k类的信息,那么我们就可以判定一个数据是属于第k类的概率,这个概率值就是,因此对K个可能的分类,我们就会得到把当前的数据分类到第k类的概率为。









 京公网安备 11010802041100号
京公网安备 11010802041100号