第五节解析解方式求解模型参数
第四节中我们讲解了最大似然和最小二乘之间的关系,通过数学原理找到了损失函数为MSE的理论支撑。本节的话我们讲解怎么样基于目标函数为MSE的情况下,找到最合适的参数模型。在此之前,我们总结下通过最大似然估计建立目标函数思路:
1. 建立线性模型(将误差视为未统计到的多个维度影响的结果)
2. 对于误差假设其服从均值为0的高斯分布
3. 得到每个数据点被采样到的概率分布函数(自变量为θ)
4. 最大似然估计--总概率最大
5. 通过两边取ln和公式整理,得到结论:mse最小时总似然最大。
我们挨个分析下上面逻辑,第一条什么是线性模型?所谓的多元线性回归里面的线性模型就是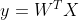 ,是一个线性相加的结果,并且误差视为未统计到的多个维度影响的结果且其服从均值为0的高斯分布。第三条中,对于每一个样本,都会得到一个概率分布函数。第四条中,将所有的样本的概率分布函数累乘,得到一个似然函数,我们的目标就是使其总样本发生的概率最大。最后通过对最大似然函数做数学变换,两边取ln和公式整理,得到结论为:mse最小时总似然最大。所以我们得到新的目标:所谓学习就是 求出一组使mse最小的θ参数。通常,我们把求一个使某函数达到最大(小)值的自变量解的过程叫做函数最优化,机器学习实质上都是将参数学习问题转变为函数最优化问题,进而求解,所以对于线性回归问题,我们要做的就是对
,是一个线性相加的结果,并且误差视为未统计到的多个维度影响的结果且其服从均值为0的高斯分布。第三条中,对于每一个样本,都会得到一个概率分布函数。第四条中,将所有的样本的概率分布函数累乘,得到一个似然函数,我们的目标就是使其总样本发生的概率最大。最后通过对最大似然函数做数学变换,两边取ln和公式整理,得到结论为:mse最小时总似然最大。所以我们得到新的目标:所谓学习就是 求出一组使mse最小的θ参数。通常,我们把求一个使某函数达到最大(小)值的自变量解的过程叫做函数最优化,机器学习实质上都是将参数学习问题转变为函数最优化问题,进而求解,所以对于线性回归问题,我们要做的就是对  其优化。
其优化。
那么如何求函数最小值呢?(函数最优化问题)我们结合高中的知识知道,直接的思路是求导,然后使得导数为零的点,就是我们的最优解。那么这个思想可以应用到求解我们的模型参数吗?实际上是可以的,因为都是函数的最优化问题。我们铺垫几个向量求导的预备公式:
 ;
;  ;
;  ;
; 
上面我们不用管怎么来的,就是一些数学公式而已,有兴趣的自己研究下就可以。先将损失函数写成矩阵形式:

解释:因为 是列向量(
是列向量( 是预测的
是预测的 ,减去对应的真实的,所以是一个列向量),转置之后
,减去对应的真实的,所以是一个列向量),转置之后 是行向量。所以
是行向量。所以 根据向量相乘的规则,对应位置相乘相加,因为对应位置都是同一个元素,所以就是右边的
根据向量相乘的规则,对应位置相乘相加,因为对应位置都是同一个元素,所以就是右边的 相加,也就是最终的上面的写成矩阵形式的公式。其中X矩阵是把每个x看做一个行向量张成的矩阵,y是把所有训练集上的y写作一个列向量。
相加,也就是最终的上面的写成矩阵形式的公式。其中X矩阵是把每个x看做一个行向量张成的矩阵,y是把所有训练集上的y写作一个列向量。
因为我们的目标是想得到一组最小的 ,所以也就是相当于
,所以也就是相当于 对求导,并令其导数为0,然后解出来,就是我们的最小的解。既然要求导,那么我们对目标函数求梯度,我们说对于向量求梯度,实际上就是对于向量中的每个参数求导,这是一 一对应的。我们对目标函数求梯度的过程如下:
对求导,并令其导数为0,然后解出来,就是我们的最小的解。既然要求导,那么我们对目标函数求梯度,我们说对于向量求梯度,实际上就是对于向量中的每个参数求导,这是一 一对应的。我们对目标函数求梯度的过程如下:




其实上面就是我们根据上面铺垫的向量求导公式结合乘法展开式可得。当梯度为0时,函数应有极小值。此时 。解得
。解得 。称该形式为线性回归目标函数的解析解。因为解析解不是那么重要,所以不再详细一步步展开上面转换过程。所以我们可以补充总结下线性回归学习的整体流程:
。称该形式为线性回归目标函数的解析解。因为解析解不是那么重要,所以不再详细一步步展开上面转换过程。所以我们可以补充总结下线性回归学习的整体流程:
1. 一开始我们拿到了训练集,包含若n个数据点,每个点有m个维度(特征)
2. 我们设定线性判别模型 
3. 想要求得最好的一组θ(学习目标)
4. 建立MSE目标函数
5. 对MSE目标函数求使其极小的θ。第一个工具:解析解。
然而解析解有如下缺陷:
1. 解析解函数中存在矩阵求逆的步骤,不是所有矩阵的逆矩阵都可求,有时候只能求近似解
2. 当数据维度非常高时(几百维度以上) 解析解的求解速度会非常慢(O(n^3))
因此:通常利用梯度下降法求解函数最小问题的数值解。
所以下一节中,我们讲解通过梯度下降法求解函数最小问题的数值解,这个是最常用也是机器学习以后经常见到的,会对其原理和过程做详细介绍。





 京公网安备 11010802041100号
京公网安备 11010802041100号