作者:泰山长征 | 来源:互联网 | 2023-09-02 21:57
原文地址NVIDIA的GPU架构是围绕可扩展的多线程流多处理器阵列(SMs)构建的。当主机CPU上的CUDA程序调用内核网格时,网格的块被枚举并分配给具有可用执行能
原文地址
NVIDIA 的 GPU 架构是围绕可扩展的多线程流多处理器阵列(SMs)构建的。当主机 CPU 上的 CUDA 程序调用内核网格时,网格的块被枚举并分配给具有可用执行能力的多处理器。线程块的线程在一个多处理器上并发执行,多个线程块可以在一个多处理器上并发执行。当线程块终止时,在空出的多处理器上启动新的块。
多处理器被设计成同时执行数百个线程。为了管理如此大量的线程,它使用了 SIMT 体系结构 中描述的独特的 SIMT 体系结构(单指令、多线程)。这些指令被流水线化,以便在单个线程中利用指令级并行,以及通过同时进行硬件多线程(详见硬件多线程)广泛地利用线程级并行。与 CPU 内核不同,它们是按顺序发布的,没有分支预测,也没有投机执行。
SIMT 体系结构 和 硬件多线程 描述了所有设备共有的流多处理器的体系结构特征。
计算能力 3.x,计算能力 5.x,计算能力 6.x 和计算能力 7.x 分别提供了计算能力 3.x, 5.x, 6.x, 7.x 设备的细节。
NVIDIA 的 GPU 架构采用小端表示。
SIMT 架构
多处理器创建、管理、调度和执行线程(以 32个线程为一组,称为 warp )。组成一个 warp 的各个线程从同一个程序地址开始,但是它们有自己的指令地址计数器和寄存器状态,因此可以独立地分支和执行。“warp”一词起源于最早的并行线程技术——weaving。半 warp 是指 warp 的前半部分或后半部分。四分之一 war[ 是 warp 的第一、二、三或四分之一。
当一个多处理器有一个或多个线程块要执行时,它将这些线程块划分为多个 warp ,每个 warp 由一个 warp 调度程序调度执行。块被分割成 warp 的方式总是相同的;每个 warp 包含连续的线程——第一个 warp 包含线程 0,线程 id逐个累加 。线程层次结构描述线程 id 是如何与块中的线程索引相关联的。
一个 warp 每次执行一条共同指令,所以当一个 warp 的 32 个线程它们的执行路径都相同时,就可以实现完全的效率。如果 warp 的线程通过依赖于数据的条件产生分支发散,warp 将执行所采取的每个分支路径,禁用不在该路径上的线程。分支发散只发生在 warp 内;不管执行的是共同的代码路径还是互斥的代码路径,不同的 warp 都是独立执行的。
SIMT 体系结构类似于 SIMD (单指令、多数据)向量组织,因为一条指令控制多个处理元素。一个关键的区别是 SIMD 向量组织向软件公开 SIMD 宽度,而 SIMT 指令指定单个线程的执行和分支行为。与 SIMD 向量机相反,SIMT 使程序员能够为独立的标量线程编写线程级并行代码,以及为协调线程编写数据并行代码。为了保证正确性,程序员基本上可以忽略 SIMT 行为;然而,通过注意代码避免在 warp 处出现线程发散,就可以实现显著的性能改进。实际上,这类似于传统代码中高速缓存线的作用:在设计正确性时可以安全地忽略高速缓存线的大小,但在设计性能峰值时,必须在代码结构中考虑高速缓存线的大小。另一方面,向量架构要求软件将合并加载到向量中,并手动管理发散。
在 Volta 之前, warp 使用一个程序计数器(在 warp 中的所有32个线程之间共享),并使用一个激活掩码指定 warp 内的活跃线程。因此,来自不同区域或不同执行状态的同一 warp 内的线程不能相互发送信号或交换数据,而需要细粒度共享由锁或互斥锁保护的数据的算法很容易导致死锁,这取决于争用线程来自哪个 warp 。
从 Volta 体系结构开始,独立的线程调度允许线程之间的完全并发,而不管 warp 。使用独立的线程调度,GPU 维护每个线程的执行状态,包括一个程序计数器和调用堆栈,并可以在每个线程的粒度上产生执行,以更好地利用执行资源,或者允许一个线程等待另一个线程生成数据。调度优化器决定如何将活动线程从同一 warp 组合到 SIMT 单元中。与以前的 NVIDIA GPU 一样,这保留了 SIMT 执行的高吞吐量,但是具有更大的灵活性:现在线程可以在子 warp 粒度上发散和重新聚合。
如果开发人员假设以前的硬件体系结构具有warp -同步性,那么独立的线程调度可能导致一组不同的线程参与到执行的代码中,因此执行的结果可能会和设想的有出入。特别是,任何 warp 同步代码(如无同步、减少内 warp )都应该重新检查,以确保与 Volta 或更高版本兼容。参见计算能力7.x 查询详情。
注意:
参与当前指令的 warp 线程称为活动线程,而不在当前指令上的线程为非活动线程(禁用)。线程可以因为各种各样的原因变成非活动的,包括比同一个 warp 中其他线程提前退出 、采取了一条同目前 warp 执行的路径不同的分支路径、或者是最后一个线程块的线程,该线程块的线程数量并不是一个 warp 大小的倍数。
如果 warp 执行的是一个非原子指令,且该 warp 内有多于一个的线程在全局或共享内存写入相同的位置,发生在该位置的序列化写入数量取决于设备的计算能力(见计算能力 3.x,计算能力 5.x,计算能力 6.x,以及计算能力 7.x),而执行最终写入的线程是未定义的。
如果 warp 执行的是一个原子指令,且该 warp 内的多个线程读取、修改和写入了全局内存中的相同位置,则每次产生的读取/修改/写入该位置的操作都是序列化的,但是它们发生的顺序没有定义。
硬件多线程
多处理器处理的每个 warp 的执行上下文(程序计数器、寄存器等)在 warp 的整个生命周期内保持在芯片上。因此,从一个执行上下文切换到另一个执行上下文是没有成本的,并且在每次发出指令时,warp 调度器都会选择一个 warp(它的线程已经准备好执行下一条指令(即 warp 的活动线程)),并向这些线程发出指令。
特别地,每个多处理器都有一组 32 位寄存器,这些寄存器在 warp 之间划分,以及一个并行数据缓存或共享内存,这些内存是在线程块之间进行划分。
对于给定的内核,可以在多处理器上驻留和一起处理的块和 warp 的数量取决于内核使用的寄存器和共享内存的数量,以及多处理器上可用的寄存器和共享内存的数量。每个多处理器还具有最大驻留块数和最大驻留 warp 数。这些限制以及多处理器上可用的寄存器和共享内存的数量是设备计算能力的函数,并在附录计算能力中给出。如果每个多处理器没有足够的寄存器或共享内存来处理至少一个块,内核将无法启动。
块内 warp 的总数如下:
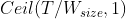 ,
,
- T 是每个块的线程数,
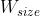 是 warp 尺寸,等于32,
是 warp 尺寸,等于32,- ceil(x, y)等于 x 四舍五入到 y 的最近倍数。
为一个块分配的寄存器总数和共享内存总量记录在 CUDA Toolkit 中 提供的 CUDA占用计算器 中。












 京公网安备 11010802041100号
京公网安备 11010802041100号