作者:我是王健值得信赖 | 来源:互联网 | 2023-06-06 20:55
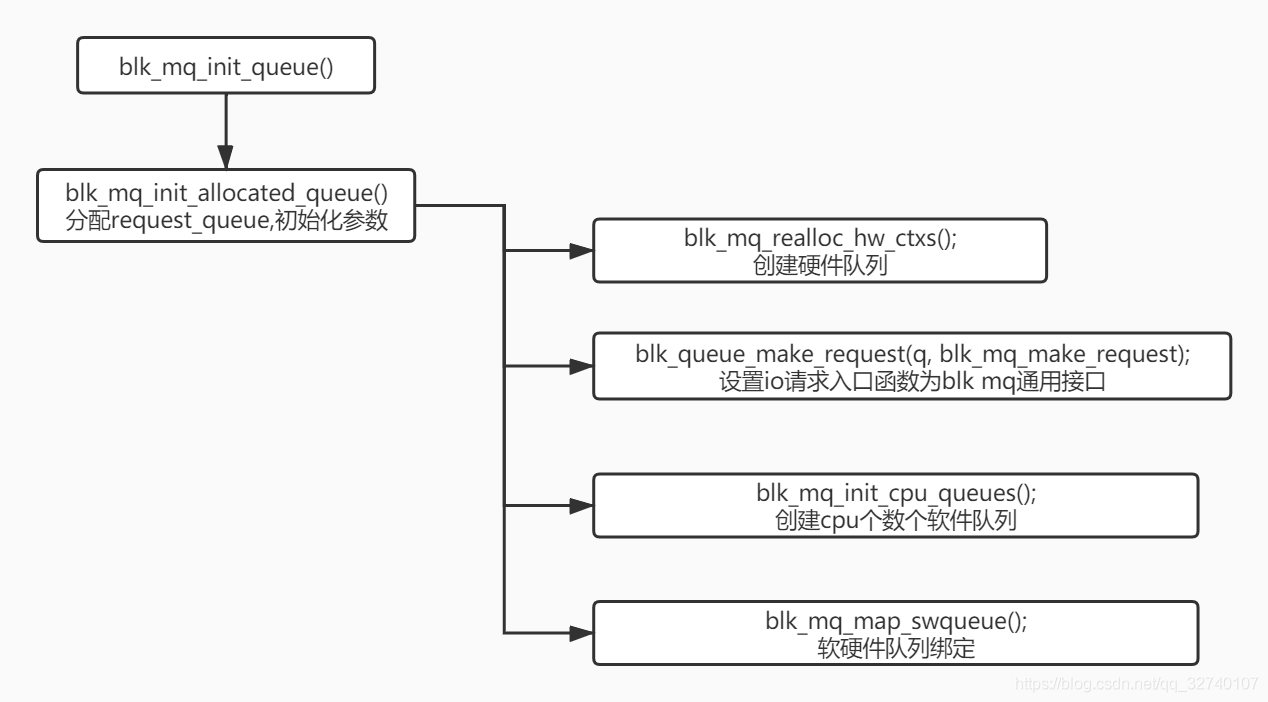
主要流程request_queue初始化块设备初始化时通过blk_mq_init_queue()创建request_queue并初始化,主要功能包含:reque
主要流程
request_queue初始化
块设备初始化时通过blk_mq_init_queue()创建request_queue并初始化,主要功能包含:
- request_queue与块设备的blk_mq_tag_set相互绑定,根据blk_mq_tag_set设置一些参数。
- 创建软硬件队列及进行绑定。
- 设置io请求入口函数make_request_fn 为 blk_mq_make_request()。
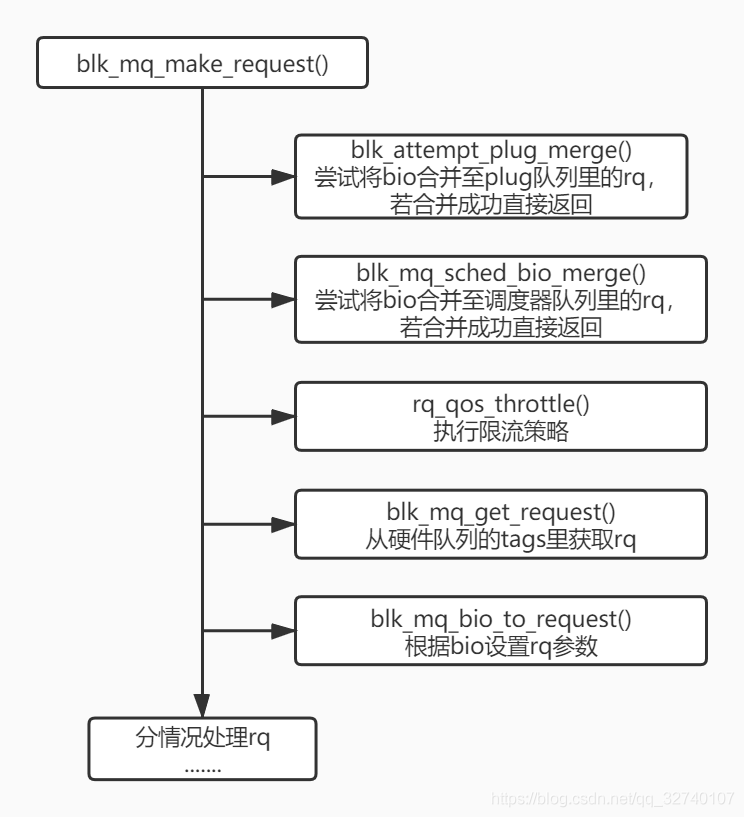
IO提交/转换request
IO请求的入口为blk_mq_make_request(),其中首先判断IO是否可以跟其他request合并,若无法合并再将IO转换为request进一步处理。
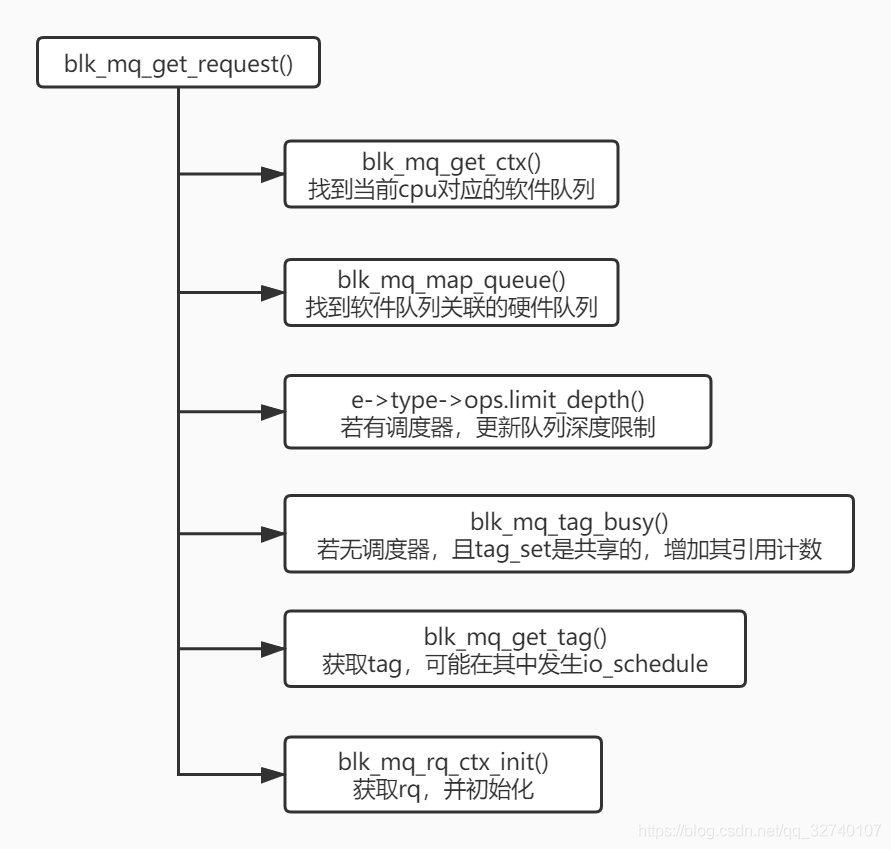
request获取
request是事先在硬件队列的tags或者sched_tags中分配好的,通过blk_mq_get_request()获取,期间有可能会因获取不到request而被io_schedule,进入iowait状态。(扩展阅读IOwait 到底在wait什么)
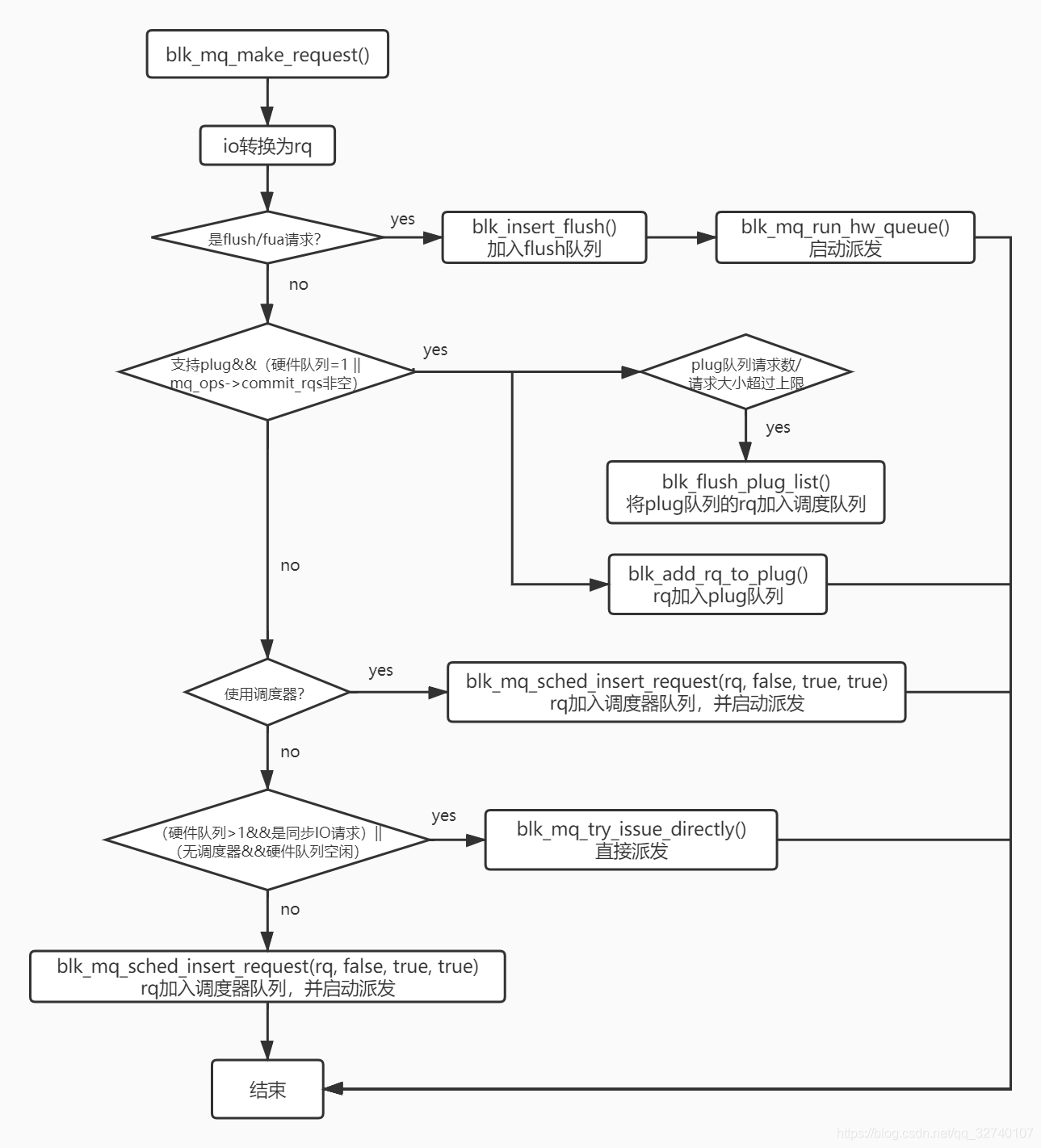
request加入队列
IO在blk_mq_make_request()中转换成request后,根据不同情况做处理,最终去向主要有三种:加入plug队列,加入调度队列,直接派发。
request派发
blk_mq_run_hw_queue() 用来启动一个硬件队列的request派发,触发派发的情况很多,大致归纳下是:需要直接处理request,plug/调度队列flush,硬件队列启动/停止,blk_mq_get_tags中获取不到tags,kyber_domain_wake等等。

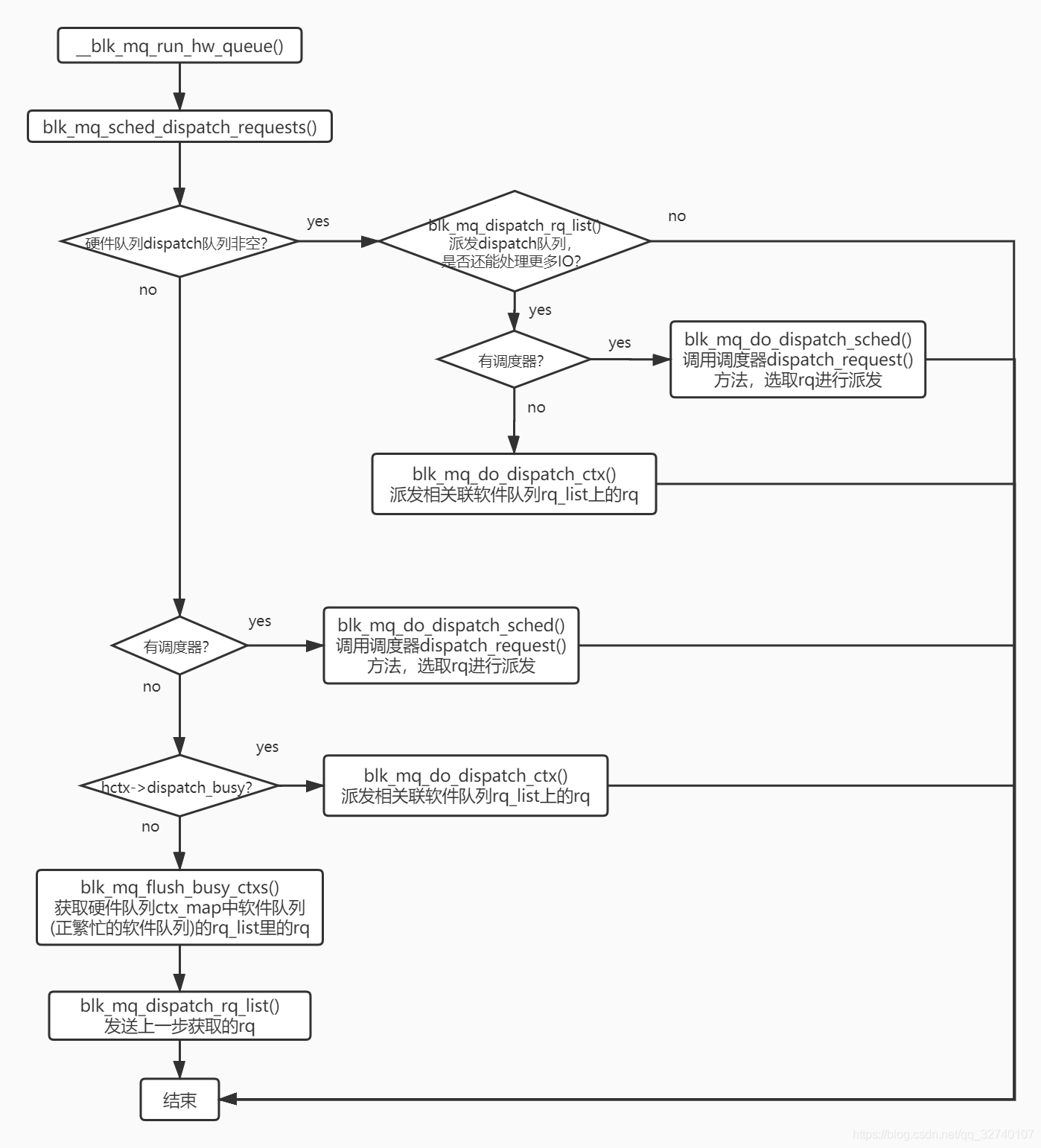
调用__blk_mq_run_hw_queue() 从可能的三个队列中选取request进行派发,他们是:硬件队列的dispatch,request_queue的调度器队列,硬件队列关联的软件队列的rq_list。最终在blk_mq_dispatch_rq_list()中调用q->mq_ops->queue_rq()完成向下层驱动派发request。
request完成
硬件驱动完成一个IO请求后,调用scsi_cmnd->scsi_done回调,针对block multi-queue 实现了统一接口scsi_mq_done()。处理IO完成中断的CPU与发起request的CPU可能不一致,scsi_mq_done()中的策略是尽量在发起request的CPU上处理request完成。

最终都会调用q->mq_ops->complete回调对request进行完成处理,统一实现的接口是scsi_softirq_done()。其中主要调用路径是scsi_softirq_done()->scsi_finish_command()->scsi_io_completion()->scsi_end_request()->__blk_mq_end_request()... ,执行request提交过程中注册的各种回调,最终释放request,完成一次IO请求。
机制
plug/unplug
Linux块设备层早期就引入了plug/unplug机制,为每个task分配一个plug list,当task提交IO时不立马处理,而是积攒一定量再统一加入下一级派发队列,减少对派发队列的竞争,从而提高性能,block multi-queue也继承了这一机制,与单队列的实现基本一致,网络上已有大量分析,这里就不再赘述。
IO 合并
request由bio转化而来,最初一个request内只包含一个bio,若有新提交的bio与已经在排队等待处理的request物理上连续,就直接将该bio合入request。推荐这篇文章https://blog.csdn.net/juS3Ve/article/details/80576965,已经分析的十分透彻了。block multi-queue 新增的部分是,当不使用调度器时request会在软件队列的rq_list上等待派发,提交IO时也会尝试与rq_list中的request进行合并。对于block mulit-queue架构,可能发生IO合并的队列有三个:plug list ,调度器内部队列(使用调度器),软件队列的rq_list(不使用调度器)。
软硬件队列映射
在之前的数据结构分析中提到block multi-queue的软硬件映射关系是由硬件相关的blk_mq_tag_set->map决定,设置其映射关系的函数为blk_mq_map_queues()。
int blk_mq_map_queues(struct blk_mq_queue_map *qmap)
{unsigned int *map = qmap->mq_map;unsigned int nr_queues = qmap->nr_queues;unsigned int cpu, first_sibling, q = 0;for_each_possible_cpu(cpu)map[cpu] = -1;/** Spread queues among present CPUs first for minimizing* count of dead queues which are mapped by all un-present CPUs*/for_each_present_cpu(cpu) {//优先映射online的cpuif (q >= nr_queues)//若硬件队列数量不够直接跳出break;map[cpu] = queue_index(qmap, nr_queues, q++);}for_each_possible_cpu(cpu) {//检查所有cpuif (map[cpu] != -1)continue;/** First do sequential mapping between CPUs and queues.* In case we still have CPUs to map, and we have some number of* threads per cores then map sibling threads to the same queue* for performance optimizations.*/if (q }
具体映射策略是:
- 优先保障online的cpu映射到不同的硬件队列
- 若cpu数量大于硬件队列,将同一硬件核的cpu映射到同一硬件队列
- 没有同硬件核的cpu顺序轮转映射硬件队列
并发管理
block multi-queue通过控制request的获取,来限制一个硬件队列在block层最大并发request数量。由之前的数据结构分析可知,request是预先分配好的保存在struct blk_mq_tags结构中。运行时根据是否使用调度器,决定从硬件队列的tags或是sched_tags中获取request,所以最大并发request数也要分是否使用调度器来讨论。获取request的函数为blk_mq_get_request()。
使用调度器流程:
- 找到当前软件队列映射的硬件队列
- 调用调度器limit_depth方法(若有实现),设置shallow_depth
- sched_tags有空闲的request且分配的request总数
- 若分配不成功,调用blk_mq_run_hw_queue()启动request派发,再重试获取request,期间可能进入iowait
不使用调度器流程:
- 找到当前软件队列映射的硬件队列
- 若硬件blk_mq_tag_set支持共享,增加tags的active_queues
- 若硬件blk_mq_tag_set支持共享,且当前硬件队列已分配的request超过均分上限,分配失败
- tags有空闲的request,分配成功
- 若分配不成功,调用blk_mq_run_hw_queue()启动request派发,再重试获取request,期间可能进入iowait
总结一下,每个硬件队列的最大并发request数是:
使用调度器:request_queue的nr_request,与调度器limit_depth方法返回值的较小值。
不使用调度器且不支持共享tag_set:硬件队列queue_depth。
不使用调度器支持共享tag_set:queue_depth个request,各active_queue均分。
调度器
block multi-queue最开始是不支持调度器的,调度器只在单队列中生效,随着单队列代码逐步移出内核,而调度器对于hdd这种慢速设备又很有必要,调度器框架也加入了block multi-queue。从代码也能看出multi-queue框架中是否使用调度器,处理流程差异很大。Linux5.x后支持mq-deadline,bfq,kyber三种调度器,其中只有kyber有针对multi-queue框架中的多软硬队列做了处理,也被称为是真正意义上的多队列调度器。











 京公网安备 11010802041100号
京公网安备 11010802041100号