作者:berryhu | 来源:互联网 | 2022-07-09 20:50
这篇文章主要介绍了python正则爬取某段子网站前20页段子(request库)过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
首先还是谷歌浏览器抓包对该网站数据进行分析,结果如下:
该网站地址:http://www.budejie.com/text
该网站数据都是通过html页面进行展示,网站url默认为第一页,http://www.budejie.com/text/2为第二页,以此类推
对网站的内容段子所处位置进行分析,发现段子内容都是在一个 a 标签中

坑还是有的,这是我第一次写的正则:
content_list = re.findall(r'(.+?)', html_str)
之后发现竟然匹配到了一些推荐的内容,最后我把正则改变下面这样,发现没有问题了,关于正则的知识这里就不做过多解释了
content_list = re.findall(r'\s*
(.+?)', html_str)
现在要的是爬取前20页的段子并保存到本地,已经知道翻页的规律和匹配内容的正则,就直接可以写代码了
代码如下,整体思路还是和前两排爬虫博客一样,面向对象的写法:
import requests
import re
import json
class NeihanSpider(object):
"""内涵段子,百思不得其姐,正则爬取一页的数据"""
def __init__(self):
self.temp_url = 'http://www.budejie.com/text/{}' # 网站地址,给页码留个可替换的{}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
def pass_url(self, url): # 发送请求,获取响应
print(url)
respOnse= requests.get(url, headers=self.headers)
return response.content.decode()
def get_first_page_content_list(self, html_str): # 提取第一页的数据
content_list = re.findall(r'\s*
(.+?)', html_str) # 非贪婪匹配
return content_list
def save_content_list(self, content_list):
with open('neihan.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False))
f.write('\n') # 换行
print('成功保存一页!')
def run(self): # 实现主要逻辑
for i in range(20): # 只爬取前20页数据
# 1. 构造url
# 2. 发送请求,获取响应
html_str = self.pass_url(self.temp_url.format(i+1))
# 3. 提取数据
content_list = self.get_first_page_content_list(html_str)
# 4. 保存
self.save_content_list(content_list)
if __name__ == '__main__':
neihan = NeihanSpider()
neihan.run()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
推荐阅读
-
文章目录简介HTTP请求过程HTTP状态码含义HTTP头部信息Cookie状态管理HTTP请求方式简介HTTP协议(超文本传输协议)是用于从WWW服务 ...
[详细]
蜡笔小新 2023-10-15 14:59:43
-
本文介绍了使用正则表达式来爬取36Kr网站首页所有新闻的操作步骤和代码示例。通过访问网站、查找关键词、编写代码等步骤,可以获取到网站首页的新闻数据。代码示例使用Python编写,并使用正则表达式来提取所需的数据。详细的操作步骤和代码示例可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-12 19:16:21
-
-
最近在学Python,看了不少资料、视频,对爬虫比较感兴趣,爬过了网页文字、图片、视频。文字就不说了直接从网页上去根据标签分离出来就好了。图片和视频则需要在获取到相应的链接之后取做下载。以下是图片和视 ...
[详细]
蜡笔小新 2023-10-15 09:28:43
-
1.创建Scrapy项目scrapystartprojectCrawlMeiziTuscrapygenspiderMeiziTuSpiderhttps:movie.douban.c ...
[详细]
蜡笔小新 2023-10-14 15:02:27
-
目录爬虫06scrapy框架1.scrapy概述安装2.基本使用3.全栈数据的爬取4.五大核心组件对象5.适当提升scrapy爬取数据的效率6.请求传参爬虫06scrapy框架1. ...
[详细]
蜡笔小新 2023-10-13 22:01:54
-
博主使用代理IP来自于网上免费提供高匿IP的这个网站用到的库frombs4importBeautifulSoupimportrandomimporturllib.re ...
[详细]
蜡笔小新 2023-10-13 18:52:58
-
本文介绍了ECMA262规定的typeof操作符对不同类型的变量的返回值,以及instanceof操作符的使用方法。同时还提到了在不同浏览器中对正则表达式应用typeof操作符的返回值的差异。 ...
[详细]
蜡笔小新 2023-12-10 17:31:51
-
一、用户行为三剑客以下3个CSS属性:user-select属性可以设置是否允许用户选择页面中的图文内容;user-modify属性可以设置是否允许输入 ...
[详细]
蜡笔小新 2023-10-17 14:35:15
-
篇首语:本文由编程笔记#小编为大家整理,主要介绍了正则表达式python相关的知识,希望对你有一定的参考价值。 ...
[详细]
蜡笔小新 2023-10-13 18:34:35
-
蜡笔小新 2023-10-13 12:38:39
-
在Android中解析Gson解析json数据是很方便快捷的,可以直接将json数据解析成java对象或者集合。使用Gson解析json成对象时,默认将json里对应字段的值解析到java对象里对应字段的属性里面。然而,当我们自己定义的java对象里的属性名与json里的字段名不一样时,我们可以使用@SerializedName注解来将对象里的属性跟json里字段对应值匹配起来。本文介绍了使用@SerializedName注解解析json数据的方法,并给出了具体的使用示例。 ...
[详细]
蜡笔小新 2023-12-11 19:04:09
-
本文介绍了响应式页面的概念和实现方式,包括针对不同终端制作特定页面和制作一个页面适应不同终端的显示。分析了两种实现方式的优缺点,提出了选择方案的建议。同时,对于响应式页面的需求和背景进行了讨论,解释了为什么需要响应式页面。 ...
[详细]
蜡笔小新 2023-12-11 12:37:10
-
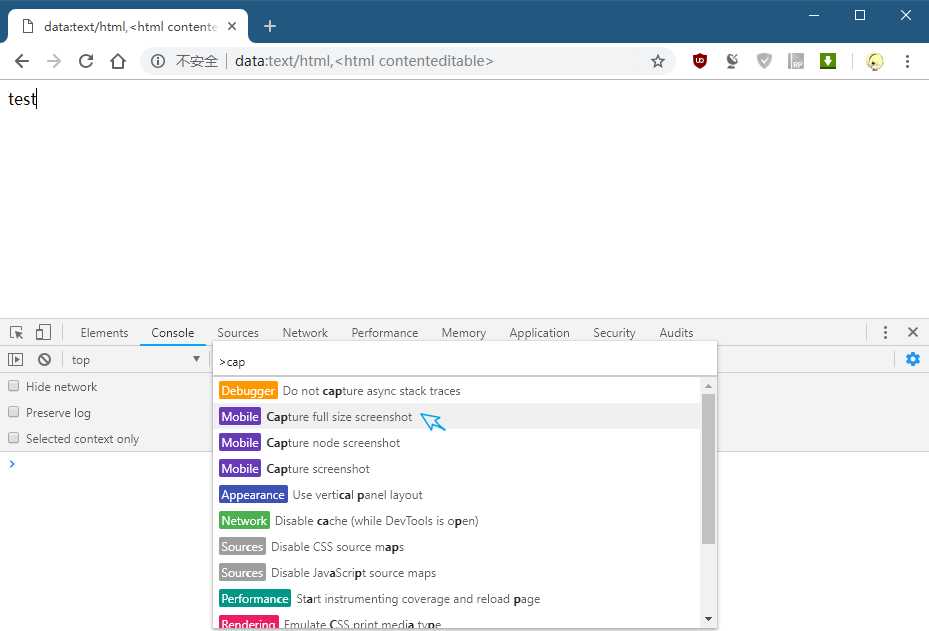
本文介绍了在chrome浏览器中使用编辑器实现网页截图功能的方法。通过在地址栏中输入特定命令,打开控制台并调用命令面板,用户可以方便地进行网页截图操作。 ...
[详细]
蜡笔小新 2023-12-10 15:50:00
-
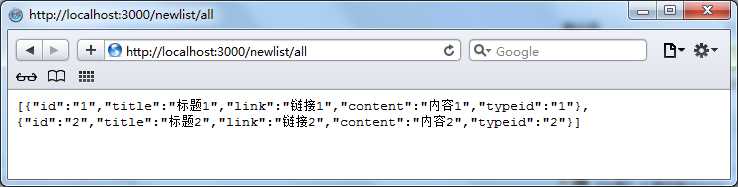
本文介绍了在express工程中如何调用json数据,包括建立app.js文件、创建数据接口以及获取全部数据和typeid为1的数据的方法。 ...
[详细]
蜡笔小新 2023-12-10 13:09:24
-
本文整理了常用的CSS属性及用法,包括背景属性、边框属性、尺寸属性、可伸缩框属性、字体属性和文本属性等,方便开发者查阅和使用。 ...
[详细]
蜡笔小新 2023-12-09 03:01:43
-






 京公网安备 11010802041100号
京公网安备 11010802041100号