作者:pbird | 来源:互联网 | 2023-08-23 20:58
python数据分析-第三次笔记–1.交叉分析–2.分组分析1.交叉分析交叉分析的含义是在纵向分析法和横向分析法的基础上,从交叉、立体的角度出发,由浅入深、由低级到高级的一种分析方
python数据分析 -第三次笔记
–1.交叉分析
–2.分组分析
1.交叉分析
交叉分析的含义是在纵向分析法和横向分析法的基础上,从交叉、立体的角度出发,由浅入深、由低级到高级的一种分析方法。这种方法虽然复杂,但它弥补了“各自为政”分析方法所带来的偏差。
其实主要的用法是:用于分析两个变量之间的关系。
交叉分析一定要和假设检验连用会更好
首先,作者的理解是:交叉分析,一定是二维的,需要两个因子,要不无法交叉,那既然交叉了,就可以做成透视表,这两个因子一个为行,一个为列,然后做假设检验,判断P值是否小于0.0.5,这样就更加清晰明了
编程实现:
采用的是T检验假设
*第一步,提取数据
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
#设置图片的字体 font_scale
sns.set_context(font_scale=1.5)
df=pd.read_csv("./data/HR.csv")
#分组indices获得分组后的数据的索引,下标
#'''
dp_indices=df.groupby(by="department").indices
#取出left的sales的值
#loc : 通过行标签索引行数据
#iloc : 通过行号索引行数据
sales_values=df["left"].iloc[dp_indices["sales"]].values
#取出left的technical的值
technical_values=df["left"].iloc[dp_indices["technical"]].values
*第二步,T检验
#输出这两个变量的t检验的P值 ss.ttest_ind()[1]
print(ss.ttest_ind(sales_values,technical_values)[1])
#然后分组后的department数据,按组为一个因子两两求P值
#取出department分组后的keys键名称
dp_keys=list(dp_indices.keys())
#初始化一个dp_t_mat的矩阵
dp_t_mat=np.zeros([len(dp_keys),len(dp_keys)])
#便利每一个数据
for i in range(len(dp_keys)):
for j in range(len(dp_keys)):
#t检验
p_value=ss.ttest_ind(df["left"].iloc[dp_indices[dp_keys[i]]].values,\
df["left"].iloc[dp_indices[dp_keys[j]]].values)[1]
#t检验的P值小于0.05赋-1,就是让heatmap绘出的图形,更加具有区分性
if p_value<0.05:
dp_t_mat[i][j]=-1
else:
#把P值赋给dp_t_mat矩阵
dp_t_mat[i][j] = p_value
*第三步,绘图
#画图
sns.heatmap(dp_t_mat,xticklabels=dp_keys,yticklabels=dp_keys)
plt.show()
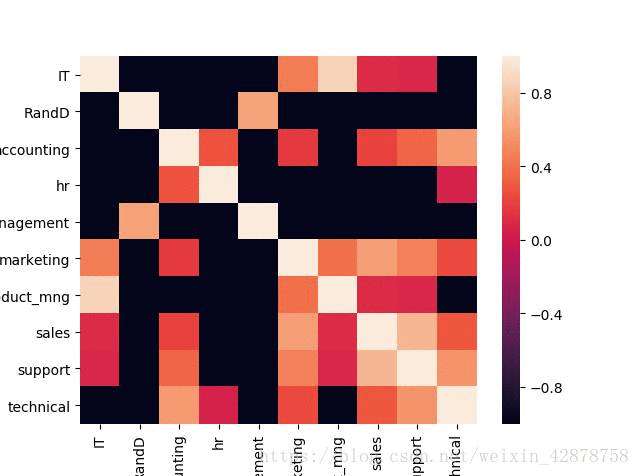
*利用透视表,交叉分析
#建一个透视表pd.pivot_table()
#values="left"我们看得值是left,横坐标index设置为promotion_last_5years,再指定一个salary,
#纵坐标columns 表示Work_accident,聚合方法aggfunc,设为平均数,是一个函数
piv_tb=pd.pivot_table(df,values="left",index=["promotion_last_5years","salary"],\
columns=["Work_accident"],aggfunc=np.mean)
#画图,透视表,填入这张表piv_tb,最小值vmin,最大值vmax,颜色cmap
sns.heatmap(piv_tb,vmin=0,vmax=1,cmap=sns.color_palette("Reds",n_colors=256))
plt.show()

2.分组分析
*分组分析的含义:是指将客体(问卷、特征、现实)按研究要求进行分类编组,使得同组客体之间的差别小于各种客体之间的差别,进而进行分析研究的方法。
分组分析,一般是利用条形图绘制的,绘制条形图主要是利用seaborn模块的barplot()和countplot()条形图函数。
这里讲一下barplot()和countplot()之间的区别:
*barplot(条形图)
条形图表示数值变量与每个矩形高度的中心趋势的估计值,并使用误差线提供关于该估计值附近的不确定性的一些指示。具体用法如下:
*countplot()绘制
一个计数图可以被认为是一个分类直方图,而不是定量的变量。基本的api和选项与barplot()相同,因此您可以比较嵌套变量中的计数。(工作原理就是对输入的数据分类,条形图显示各个分类的数量)具体用法如下:
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
注:countplot参数和barplot基本差不多,可以对比着记忆,有一点不同的是countplot中不能同时输入x和y,且countplot没有误差棒。
*分组分析的编程实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#设置图片的字体 font_scale
sns.set_context(font_scale=1.5)
df=pd.read_csv("./data/HR.csv")
#离散分组
#绘条形图
#sns.barplot(x="salary",y="left",hue="department",data=df)
#plt.show()
#连续分组
sl_s=df["satisfaction_level"]
sns.barplot(list(range(len(sl_s))), sl_s.sort_values())
plt.show()
绘图结果

*第二种,利用不纯度(Gini系数)
#可能平方和
def getProbSS(s):
if not isinstance(s,pd.core.series.Series):
s=pd.Series(s)
prt_ary = pd.groupby(s, by=s).count().values / float(len(s))
return sum(prt_ary**2)
#求Gini的值
def getGini(s1,s2):
d=dict()
for i in list(range(len(s1))):
d[s1[i]]=d.get(s1[i],[]) + [s2[i]]
return 1-sum([getProbSS(d[k])*len(d[k]) / float(len(s1)) for k in d])
print("getGini",getGini(s1,s2))









 京公网安备 11010802041100号
京公网安备 11010802041100号