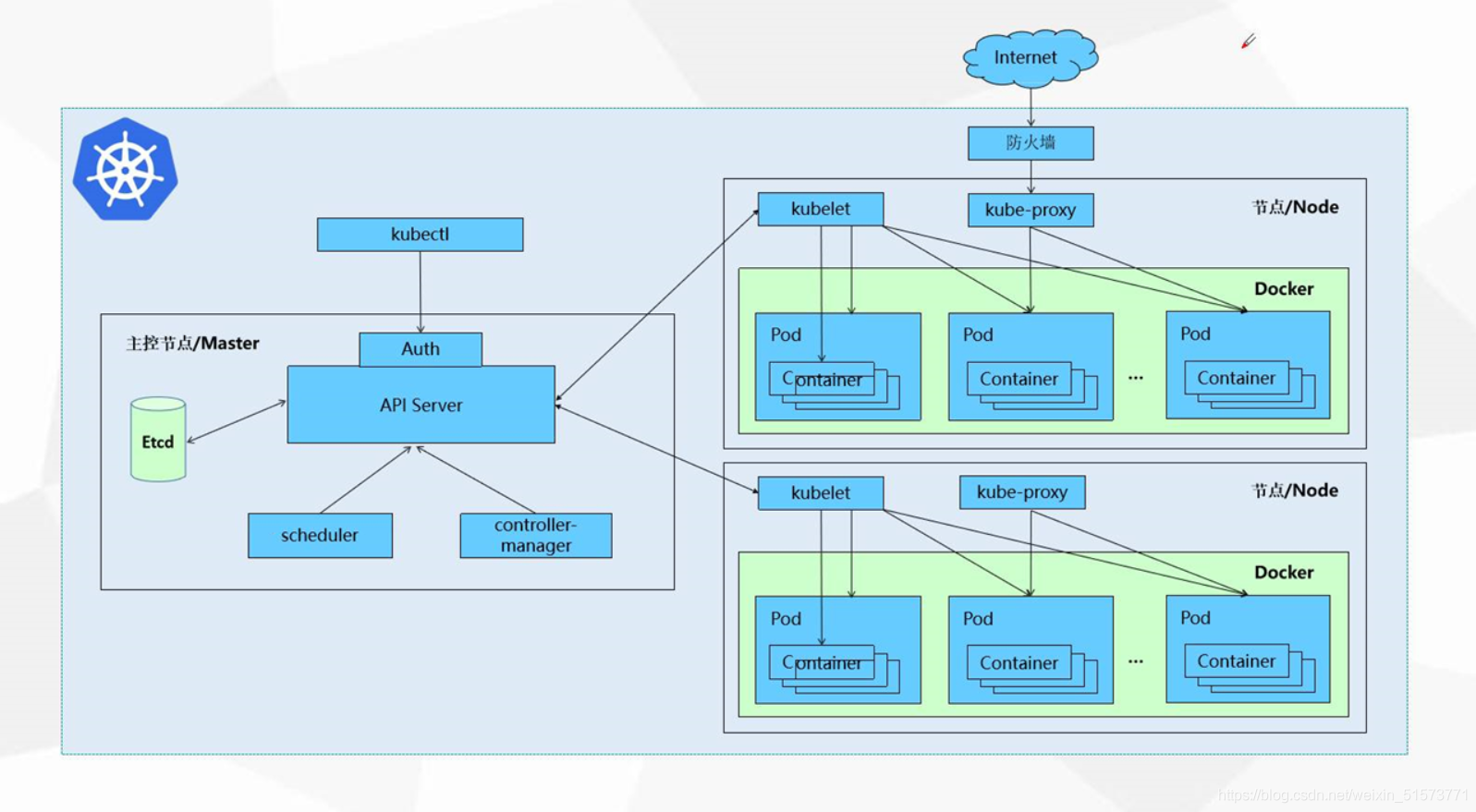
MR解析 Mapper/Reducer封装了应用程序的数据处理逻辑。 所有存储在底层分布式文件系统上的数据均要解释成key/value的形式。并交给MR中的map/reduce函数处理,产生另外一些key/value。 Mapper 1)初始化 Mapper继承了JobConfigurable接口。该config方法允许通
Mapper/Reducer封装了应用程序的数据处理逻辑。
所有存储在底层分布式文件系统上的数据均要解释成key/value的形式。并交给MR中的map/reduce函数处理,产生另外一些key/value。
Mapper继承了JobConfigurable接口。该config方法允许通过JobConf参数对Mapper进行初始化。
MapReduce会通过InputFormat中RecordReader从InputSplit获取一个key/value对,并交给map()函数处理:
void map(K1 key,V2 value,OutputCollector
Mapper通过继承Colseable获得close方法,用户可通过实现该方法对Mapper进行清理。
ChainMapper 链式作业;IdentityMapper对于输入不进行任何处理,直接输出;InvertMapper 交换key/value位置;
RegexMapper 正则表达式字符串分割;TokenMapper 将字符串分割成若干个token,可用作wordCount的Mapper;
LongSumReducer:以key为组,对long类型的value求累加和。
新的Mapper由接口变为抽象类;不再继承JobConfigurable和Closeable,而是直接在类中添加了setup和cleanup两个方法进行初始化和清理工作。
将参数封装到Context对象中,接口具有良好扩展性。
去掉MapRunnable接口,在Mapper中添加run方法,以方便用户定制map()函数的调用方法。
新API中,Reducer遍历value的迭代器类型变为Iterable
void reduce(KEYIN key,Iteratable values,Context context) throws IOException,InterrupteException{for(VALUEIN value:values){ context.write((KEYOUT) key,(VALUEOUT) value);}}
Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一个Reducer处理,它直接影响Reduce阶段的负载均衡。
只包含一个待实现的方法getPartition。该方法包含3个参数,均由框架自传入,前面2个参数是key/value,第三个参数numPartitions表示每个Mapper的分片数,
也就是Reducer的个数。
HashPartitioner和TotalOrderPartitioner。其中HashPartitioner是默认实现:public int getPartition(K2 key,V2 value,int numReduceTasks){return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks ;}在client端通过采样获取分片的分割点。
采样数据:b,abc,abd,bcd,abcd,efg,hii,afd,rrr,mnk
排序后:abc,abcd,abd,afd,b,bcd,efg,hii,mnk,rrr
如果有4个Reduce Task,则采样数据的四等分点为abd,bcd,mnk
Mapper可采用IdentityMapper直接将输入数据输出,TotalOrderPartitioner将步骤1中获取的分割点保存到trie树中以便快速定位任意一个记录所在的区间,这样每个
Map Task产生R个区间,且区间中间有序。
每个Reducer对分配到的区间数据进行局部排序,最终得到全排序数据。
TotalOrderPartitioner有2个典型应用实例;TeraSort和HBase。
HBase内部数据有序,Region之间也有序。
原文地址:深入解析MapReduce架构设计与实现原理–读书笔记(4)MR及Partitioner, 感谢原作者分享。
![[翻译]微服务设计模式5. 服务发现服务端服务发现](https://img7.php1.cn/3cdc5/ca23/525/3af55d7cf19345b9.jpeg)









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有