| 全文共8155字,建议阅读时长8分钟 |
本文由《开放教育研究》授权发布
作者:冯翔 邱龙辉 郭晓然
摘要
分析学生学习过程产生的反馈文本,是发现其学业情绪的重要方式。传统的学业情绪测量方法主要包括使用学业情绪测量问卷和访谈分析,但这两种方法难以大规模地应用于在线教育环境。本研究旨在通过构建学业情绪自动预测模型,对大量学生反馈文本进行快速有效的学业情绪分类。研究首先利用词向量训练工具,将文本转化为多维向量;然后基于深度学习网络LSTM构建学业情绪预测模型,以文本的多维向量作为模型输入;最后经过多轮训练,优化模型参数。实验显示,上述模型可快速有效识别学生反馈文本中所包含的学业情绪,该模型在测试数据集上的学业情绪识别准确率可达89%。
关键词:人工智能教育应用;学业情绪;LSTM;自然语言处理
在线学习平台上记录了大量基于文本的学生评论反馈,如何挖掘这些评论文本中隐含的有效信息,受到众多研究者的关注。情绪分析是文本挖掘的重要研究方向,近年来已应用于众多领域。与网络舆论、商品评论等领域不同,学生评论中还隐藏了学业情绪,包含积极高唤醒、消极高唤醒、积极低唤醒、消极低唤醒四类学业情绪(Pekrun et al.,2011)。这些学业情绪影响着学生的身心健康、认知过程等(Ainley et al.,2005;Pekrun et al.,2002)。关注学生的学业情绪对学生的认知提升、身心健康的发展都有重要意义。传统的学业情绪测量方法主要基于访谈和测量问卷,但由于规模限制,这种测量方法难以广泛应用于实际教学。随着人工智能技术的快速发展,采用机器学习的方法自动化、智能化地识别学业情绪是一种新的发展趋势。本研究基于深度学习中的长短期记忆网络(Long Short- Term Memory,简称LSTM)构建教育领域学业情绪识别模型,通过将LSTM模型与教育领域深度融合,快速发现学生反馈文本中的学业情绪类型,为自动化识别学业情绪提供一种新的手段和方法。
一、研究综述
(一)学业情绪
学生在学习过程中能够体会到不同的情绪,例如对一门课程或知识点掌握后的愉快感、考试过程中的焦虑感等。这些学习体验与课堂教学、课外学习和学业成就有直接关系。2002年,德国心理学家佩克伦等(Pekrun et al.,2002)将学习过程所有环节中与学生学业学习活动体验相关的各种情绪统称为学业情绪。俞国良等人(2005)将学业情绪的范围进一步扩大,认为它不仅包括学生在获悉学业成功或失败后所体验到的各种情绪,还包括在课堂学习、日常完成作业过程中以及在考试期间的情绪体验等。
学业情绪对学生成长的重要性不容忽视。美国教育研究联合会在1998年召开了主题为“情绪在学生与学业成就中的关系”的年度学术会议,突出了情绪研究对学生与学业的重要性。佩克伦等(Pekrun et al.,2002)指出学业情绪与学业动机、兴趣、意愿和努力等联系密切。情感、情绪、态度等因素对问题解决能力也有重要影响(魏雪峰,2017)。诸多实证研究(王瑞红,2009;俞国良,董妍,2005)表明,学业情绪在很大程度上能够预测学生的学业成就。海亚特等人(Hayat et al.,2018)通过收集800名医学院学生的学业情绪相关数据,发现积极的学业情绪(如希望、自豪等)与学业成绩有显著的正相关关系,享受、希望、骄傲和羞愧的学业情绪可以预测学生学业成绩的差异。王瑞红(2010)通过对398名高职院校的学生进行问卷调查和学业成绩测量,发现学生学业情绪各量表分数与学业成绩之间存在相关关系。
目前的研究大多关注学生面部表情所体现的学业情绪,如江波等(2018)基于在线教辅系统,提出种针对面部表情的困惑类学业情绪检测方法,为智能教学系统中教学干预提供参考价值。然而,学业情绪不仅体现在面部表情,也体现在课程评论、交流讨论文本等学习反馈文本中。对文本中学业情绪的挖掘,能够为教师优化教学内容与课程设计提供指导方向,从而提高学生在线学习体验,降低网络学习的辍学率。
(二)学业情绪的分类
早期对学业情绪的研究主要集中在负面情绪,教师希望掌握学生在考试过程中所经历的焦虑、学习过程中的学业倦怠。在学业情绪的分类上多数学者将其分为积极和消极两个维度,如正性负性情绪自评量表(The Positive and Negative Affect Scale),但这种分类方法难以包含学生学习过程中经历的所有情绪体验。
佩克伦等(Pekrun et al.,2011)在学业情绪理论的基础上,以愉悦度和唤醒水平为分类标准进行研究后发现,不同年龄段学生所经历的学业情绪也会有细微差别。1993年,布莱恩·派崔克(Bian Patrick)及其研究团队研究了儿童在学习活动中所经历的学业情绪,发现积极情绪(兴趣、高兴、放松)、厌倦、痛苦和生气四类情绪是学习活动中主要的情绪体验(Patrick et al.,1993)。董妍等(2007)基于莱因哈德等人的研究,以青少年为研究对象,将学业情绪划分为四个维度:积极高唤醒、积极低唤醒、消极高唤醒、消极低唤醒。其中,积极高唤醒包括自豪、高兴、希望等情绪,积极低唤醒包括满足、平静、放松等情绪,消极高唤醒包括焦虑、羞愧、生气等情绪,消极低唤醒包括厌倦、无助、沮丧、疲乏心烦等情绪。马惠霞等(2010)也遵循佩克伦等人的学业情绪理论,将大学生学业情绪分为四个维度:积极高唤醒(兴趣、愉快、希望)、积极低唤醒(自豪和放松)、消极高唤醒(羞愧、焦虑、气愤)、消极低唤醒(失望和厌烦)。
笔者在构建学业情绪标注语料库过程中,综合青少年和大学生学业情绪的表现特点,将其分为四个维度,共15种学业情绪。其中,积极高唤醒学业情绪包含四种:高兴、希望、兴趣、自豪;积极低唤醒学业情绪包含三种:满足、平静、放松;消极高唤醒学业情绪包含三种:焦虑、羞愧、气愤;消极低唤醒学业情绪包含五种:厌倦、无助、沮丧、疲乏、失望。后文构建学业情绪自动化分类的模型,也主要将学业情绪分为四个类别,即积极高唤醒、积极低唤醒、消极高唤醒、消极低唤醒。
(三)学业情绪的测量方法
早在2002年,佩克伦等编制了较完善的测量学业情绪的量表,该量表以九种基本学业情绪为测量目标。国内许多学者基于佩克伦等人的研究,针对不同学龄段,编制了不同的测量问卷。例如董妍等(2007)以中学生为主要群体编制了《青少年学业情绪问卷》,马惠霞(2008)以大学生为主要对象编制了《大学生一般学业情绪量表》。戈瓦特和格雷戈尔(Govaerts & Gregoire,2008)在学生情绪问卷的基础上编制了学业情绪量表。该量表包括26个条目,主要测量六种情绪:高兴、希望、自豪、焦虑、羞愧和挫折。国内也有学者在英文版的学业情绪量表基础上发布了大学生学业情绪量表的中文版(赵淑媛等,2012)。基于测量问卷和量表的学业情绪判断方法需要耗费大量人力物力,难以大规模实施。随着自然语言处理等技术的发展,自动化测量文本中的学业情绪成为可能。朱祖林等(2011)使用文本挖掘的方法,判断文本中所包含的学业情绪。自动化识别方法能够节省大量时间,为教师发现学生学业情绪并进行干预提供支持。
(四)情绪分析方法
情绪分析属于情感分析的范畴,是对文本进行更细致的情绪分类,而不仅限于文本的情感倾向,如积极、消极或中性的情感。情绪自动化分类方法常用于Twitter微博、电影评论的分析(郑啸等,2018 Rajan,et al.,2014;Singh,et al.,2013)。情绪的自动化分析方法主要有基于情绪词典资源和规则的分析方法及基于机器学习的方法。
1.基于情绪词典的分析方法
情绪分析的无监督学习方法,主要包含基于词典和基于规则的方法。这两种方法基于语言学的思想,只需给定数据资源和设置语句的分析规则就能识别出句子的情绪。文本情绪集中体现于某些情绪词中,如“这节课的知识点我已经掌握了,很开心”这句文本中,情绪主要体现在“开心”一词中,使用基于词典的方法能够快速识别文本句子中所体现的情绪类别,且准确率非常高。有研究(Quan & Ren,2009)基于大量博客文本构建了情绪语料库,语料库中的词汇包含八种情感类别:期望、喜悦、爱、惊喜、焦虑、悲伤、愤怒和憎恨。也有研究(Taboada et al.,2011)提出了一套更全面的算法和规则,将情感判断对象从形容词、副词扩展到名词、动词等词性,同时引入否定词和强调词等特征辅助判别文本的情感倾向,在众多领域的情感分类语料上都取得较好的效果。
2.基于机器学习的分析方法
基于机器学习的方法,不依赖于情绪词典的容量和质量,通过训练情绪分类模型预测文本的情绪类别。支持向量机、贝叶斯网络、K-最近邻等机器学习算法常被用于自动检测文本中的情绪。如李等人(Li,etal.,2014)使用支持向量机,识别出微博中的愤怒、厌恶、恐惧、快乐、悲伤和惊奇等情绪。
随着深度学习的快速发展,越来越多的研究者基于多层感知机(Multiple Layer Perceptron)构造深度学习网络,实现文本情绪分类任务。索赫等(Socher et al.,2013)使用递归神经网络(Recursive Neutral Network,简称RNN)对文本中的情感信息进行建模,并取得了很好的分类效果。在以往的研究中(於雯,周武能,2018;郑啸等,2018),基于长短期记忆网络的预测模型在其他领域取得了很好的效果,如微博短文本情感分析、电影评论分析、商品评论分析等。此外,卷积神经网络(Convolutional Neural Network,简称CNN)近年来也应用于情感分析领域,有研究者(Santos & Gattit,2014)使用这一技术进行短文本情感分类,并取得显著效果。
自动化识别文本中的学业情绪是未来发展趋势,将情绪自动化识别方法应用于教育领域,能够改善教育领域情绪识别方法的不足。
二、学业情绪自动化识别方法
(一)学业情绪自动识别框架
本文基于LSTM模型设计学业情绪自动化识别框架(见图1)。这一框架包含数据的收集与处理、文本词向量的训练、LSTM模型的训练、待判别的学生反馈文本的数据预处理、学业情绪判断五个过程。
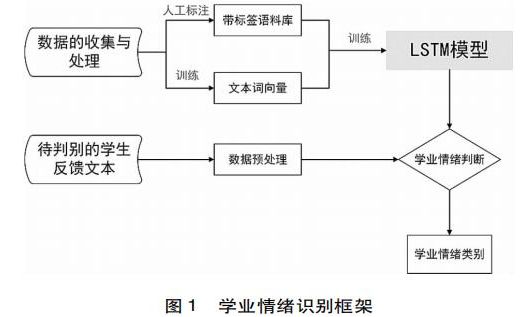
(二)数据的收集与处理
数据的收集与处理是后续过程的基础。本文通过设计爬虫程序获取在线学习平台中的学生反馈文本。数据的预处理阶段主要有两个步骤:第一,去除特殊字符与停用词,减少实验结果的影响;第二,构建标注语料库。笔者通过设计语料标注系统对学生反馈文本所表达的学业情绪进行人工标注,每条已标注的学生反馈文本都以二元组的形式保存:。如标注文本‘今天听了老师的课,有一种醍醐灌顶的感觉。把思路打开了,继续好好练习,希望这次雅思考试能取得好成绩。’的学业情绪为‘希望’,其保存形式为。
(三)训练文本词向量
神经网络模型的输入是一连串的多维特征。文本特征的表示方法有多种,其中比较著名的有独热码(one-hot)表示方法,即将所有文本中的文字以一个高维度向量表示,向量的维度是文本词表的大小,向量的绝大多数维度都是0,只有一个维度用1表示,这个用1表示的维度代表了当前词。例如:
“教育”用独热码(one-hot)方法表示为:
[000100···000]
但是使用独热码(one-hot)的表示方法中,词与词之间是相互独立的,难以判读两个词汇之间是否具有上下文关系。
为了更好地利用词向量表示上下文之间的关系,托马斯·米科洛夫等(Mikoloy et al.,2013)提:出两种词向量训练模型,连结词袋模型(Continue Bag-of-worf,简称CBOW)和跳跃元语法模型(Skipg-ram)模型。

如图2所示,两种词向量的训练模型都包括三层:输入层、隐藏层和输出层。CBOW模型的主要工作是通过上下文预测当前词出现的概率。Skipg-ram模型则相反,是利用当前词预测上下文。熊富林等(2015)将Word2vec应用于中文处理,发现Skip-gram模型训练的准确率明显比CBOW模型高,且词向量的维度在250维左右为佳。因此,本研究采用skip-gram模型对学生反馈文本进行词向量训练,维度设置为250维。
(四)LSTM模型
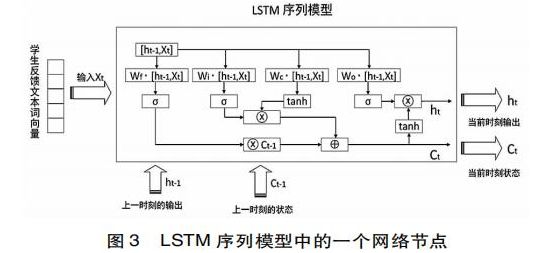
长短期记忆网络(Long short- Term Memory,简称LSTM)是一种基于序列的链式网络结构,LSTM模型解决了循环神经网络中梯度爆炸和梯度消失问题(Kolen & Kremer,2001)。经过众多研究者的优化(Graves,2012),LSTM模型在自然语言处理中取得了很好的效果,并得到了广泛应用。LSTM模型将循环神经网络中的神经元替换为拥有记忆能力的LSTM单元,根据输入序列,所有的记忆单元被连接在一起。在本文中,每个记忆单元的输入为学生反馈文本词向量X,(见图3)。记忆单元包含记忆细胞(Ct)、遗忘门(ft)、输入门(it)、输出门(ot),负责存储历史信息,通过一个状态参数记录和更新历史信息;三个门结构则通过 Sigmoid函数[σ(*)决定信息的取舍,从而作用于记忆细胞。最后通过tanh函数[tanh(*)]对当前时刻的记忆细胞状态进行计算,计算过程为公式(1)-公式(5)。
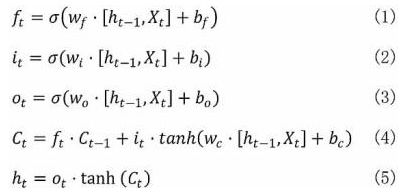
在时刻t,ht是隐藏状态时,每个门结构会接收当前的输入Xt,以及上一个记忆单元输出的隐藏状态h(t-1),并与其权重矩阵相乘,然后加上LSTM记忆单元中各自的偏置量。ωf、ωi、ωo、ωc分别为遗忘门、输入门、输出门、记忆单元的权重矩阵,bf、bi、bo、bc分别为遗忘门、输入门、输出门、记忆单元的偏置量。
(五)学业情绪的分类
为了得到文本的学业情绪分类结果,本研究将LSTM模型的输出作为 softmax层(Softmax回归模型)的输入,通过 softmax函数,将输入映射到(0,1)区间内,得到待分类数据归属各类别的概率,最后根据概率确定待分类文本的情绪预测类别。笔者将文本的4个学业情绪类别以形状为1*4的矩阵表示,经过 softmax层之后,输出结果矩阵得出每个类别的预测概率。预测结果的计算公式:
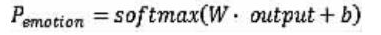
三、实验
(一)数据集
腾讯课堂(https://ke.qq.com/)、网易云课堂(http://study.163.com/)等在线学习平台吸引了众多学习者。本文通过设计爬虫程序,获取了在线平台中学生反馈文本10万余条,总计超过1千万中文字符。
实验过程使用人工标注的方法,共随机标注了8408条学生反馈文本,其中训练文本为6658条,测试文本为1750条。训练文本中各情感分布如图4所示。
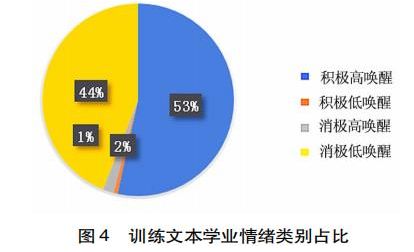
如图4显示,在学业情绪的训练文本中,积极高唤醒和消极低唤醒的文本学业情绪占比97%。从学业情绪类别分布来看,大部分在线课程反馈文本中,学业情绪集中在积极高唤醒和消极低唤醒类别。
(二)词向量训练参数和LSTM实验参数
教育领域词向量的训练过程经过多次参数的优化,通过迭代输出训练结果的方法,笔者选中了其中较优的参数结果。词向量训练过程中的具体参数设置为:向量长度 vector_size=250,窗口大小 window=7,神经网络学习率 alpha=0.025,模型为Negative Sampling的Skip-gram模型,训练的迭代次数为15。
本实验使用双层LSTM模型训练学生评论文本,其模型参数的设置对实验结果至关重要,经过多次实验效果的对比,本实验采用的参数设置为:学习率为learning_rate=0.005,LSTM的层数为2层,批处理条数batch_size=16,节点数num_nodes=128,训练:的迭代次数 num_steps=5000轮。
(三)实验结果与分析
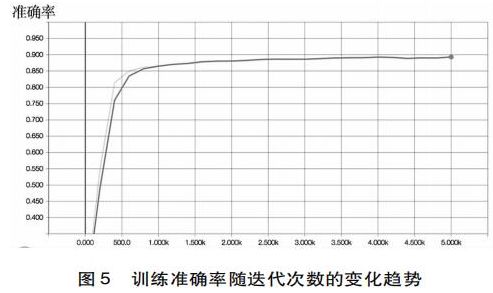
本研究使用1750条人工标记的学业情绪文本对上述训练模型进行测试。经过实验,模型预测的准确率达到89%(见图5)。
学业情绪预测结果归一化后的混淆矩阵如图6所示。在模型预测混淆矩阵中,积极高唤醒和消极低唤醒的预测准确度较高。这是由于该模型在训练过程中,数据集中在积极高唤醒和消极低唤醒文本中,能够较好识别此类文本所包含的学业情绪特征。经过人工标注数据显示,文本集中在积极高唤醒情绪[‘兴趣’,‘高兴’]和消极低唤醒学业情绪[‘失望’]中,这两类学业情绪文本数量在总标记数据中占97%,因此本实验对积极和消极唤醒度的学业情绪识别准确率可达92.2%。

四、结论和未来工作
学业情绪检测是分析学生学习状况的重要方法。和人类的基本情绪一样,学业情绪有多样性和多维度性的特点,传统方法难以很好地在文本中发现所隐含的学业情绪。本文基于深度学习的方法,使用LSTM网络训练模型对学业情绪进行预测。实验表明,该模型识别文本中学业情绪的准确率达到89%。这种自动化的分类方法可以降低分析人员的工作强度,同时为优化课程教学设计、教学内容等提供重要参考维度。
本研究初步验证了基于LSTM模型构建的学业情绪预测模型的效果,但本文所使用的数据集相对较小,且在实际学习环境中,在线学习平台上的学业情绪分布差异较大,即使获取数十万条学生反馈文本,积极低唤醒和消极高唤醒两类文本的占比仍然较低。后续研究首先需要扩大训练的数据集,增加积极低唤醒和消极高唤醒两类文本的数量,使用机器和人工相结合的在线学习方法快速收集和标注数据,以弥补教育训练文本数据集的匮乏。其次,优化神经网络参数可使学业情绪识别模型的准确率更高。不同领域的文本有着不同特点,在教育领域,训练深度学习神经网络的参数也会和其他领域(如商品评论等)有所不同。同时,神经网络中有大量参数,如何优化这些参数得到更好的训练模型是下步研究重点。再次,本研究只是对文本中的学业情绪做了总体的分类,并没有对句子中的情绪实现更细粒度的文本分类,如自豪、满足、焦虑、无助等。本研究后续将对学生反馈文本进行更细致的分类识别,更直观地了解学生在学习过程中的学习情绪体验。





基金项目:教育部在线教育研究中心2017年度在线教育研究基金(全通教育)课题“在线教育系统中学生反馈文本的情感分析技术与应用究”(2017YB126);中央高校基本科研业务费华东师范大学青年预研究项目“课堂环境中基于面部表情识别的师生情感模式及应用研究”(20l7ECNU-YYJ039)上海市科委科技攻关重大项目“上海教字化教育装备工程技术研究中能力提升目”(17DZ2281800)。
作者简介:冯翔(通讯作者),博士,副研究员,上海数字化教育装备工程技术研究中心;邱龙辉,华东师范大学教育信息技术学系硕士研究生;郭晓然,华东师范大学教育信息技术学系硕士研究生。
转载自:《开放教育研究》2019年 4月 第25卷 第2期
排版、插图来自公众号:MOOC(微信号:openonline)
新维空间站相关业务联系:
刘老师 13901311878
刘老师 13810520758
邓老师 17801126118
微信公众号又双叒叕改版啦
快把“MOOC”设为星标
不错过每日好文☟
喜欢我们就多一次点赞多一次分享吧~
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~
《预约、体验——新维空间站》
《【会员招募】“新维空间站”1年100场活动等你来加入》
《有缘的人总会相聚——MOOC公号招募长期合作者》
产权及免责声明本文系“MOOC”公号转载、编辑的文章,编辑后增加的插图均来自于互联网,对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。如果分享内容侵犯您的版权或者非授权发布,请及时与我们联系,我们会及时内审核处理。了解在线教育,
把握MOOC国际发展前沿,请关注:微信公号:openonline公号昵称:MOOC








 京公网安备 11010802041100号
京公网安备 11010802041100号