下载连接器-更多连接器自己去官网查

!注意 把 上面截图jar包放在flink-1.12.0/lib 目录下
启动本地集群
./bin/start-cluster.sh
启动客户端
./bin/sql-client.sh embedded

进入flink-sql 命令行
选择展示样式:
SET execution.result-mode=table;
SET execution.result-mode=changelog;
SET execution.result-mode=tableau;
Flink SQL> SET execution.result-mode=tableau;
[INFO] Session property has been set.
Flink SQL>
mysql 创建两个表
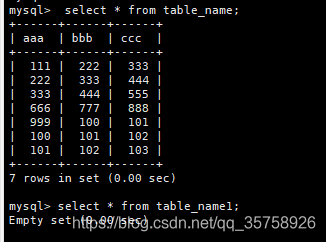
flink 创建同样的表:
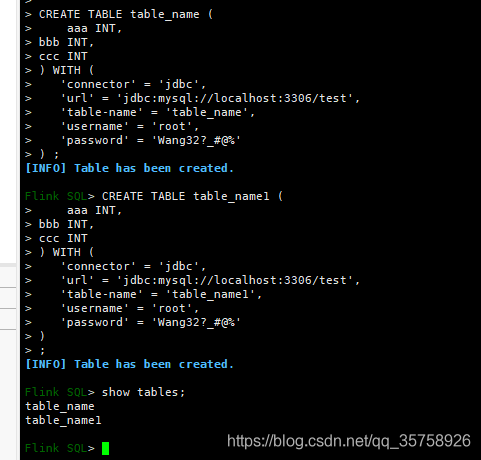
简单的插入任务
Flink SQL> select * from table_name;
+-----+-------------+-------------+-------------+
| +/- | aaa | bbb | ccc |
+-----+-------------+-------------+-------------+
| + | 111 | 222 | 333 |
| + | 222 | 333 | 444 |
| + | 333 | 444 | 555 |
| + | 666 | 777 | 888 |
| + | 999 | 100 | 101 |
| + | 100 | 101 | 102 |
| + | 101 | 102 | 103 |
+-----+-------------+-------------+-------------+
Received a total of 7 rowsFlink SQL> select * from table_name1;
+-----+-------------+-------------+-------------+
| +/- | aaa | bbb | ccc |
+-----+-------------+-------------+-------------+
Received a total of 0 rowsFlink SQL> insert into table_name1 select * from table_name where aaa = 111;
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 43ddc128683d044e6ee757faafb19f5dFlink SQL> select * from table_name1;
+-----+-------------+-------------+-------------+
| +/- | aaa | bbb | ccc |
+-----+-------------+-------------+-------------+
| + | 111 | 222 | 333 |
+-----+-------------+-------------+-------------+
Received a total of 1 rows
一些基础语法使用:
Flink SQL> select aaa,bbb as bbc from table_name t where t.bbb % 2=0;
+-----+-------------+-------------+
| +/- | aaa | bbc |
+-----+-------------+-------------+
| + | 111 | 222 |
| + | 333 | 444 |
| + | 999 | 100 |
| + | 101 | 102 |
+-----+-------------+-------------+
Received a total of 4 rows
Flink SQL> select aaa,bbb from table_name group by aaa,bbb having bbb >=222;
+-----+-------------+-------------+
| +/- | aaa | bbb |
+-----+-------------+-------------+
| + | 111 | 222 |
| + | 222 | 333 |
| + | 333 | 444 |
| + | 666 | 777 |
+-----+-------------+-------------+
Received a total of 4 rows--窗口分组
Flink SQL> select * from table_name;
+-----+-------------+-------------+-------------+-------------------------+
| +/- | aaa | bbb | ccc | time_str |
+-----+-------------+-------------+-------------+-------------------------+
| + | 111 | 222 | 333 | 2020-12-25T18:01 |
| + | 111 | 333 | 444 | 2020-12-25T18:02:01 |
| + | 111 | 444 | 555 | 2020-12-25T18:03:02 |
| + | 666 | 777 | 888 | 2020-12-25T18:04:03 |
| + | 111 | 100 | 101 | 2020-12-25T18:05:04 |
| + | 100 | 101 | 102 | 2020-12-25T18:06:05 |
| + | 111 | 102 | 103 | 2020-12-25T18:07:06 |
+-----+-------------+-------------+-------------+-------------------------+
Received a total of 7 rows
--第一行数据除外,按着时间,aaa分组,每两分钟分一组聚合计算
Flink SQL> SELECT aaa,sum(bbb) as bbc FROM table_name GROUP BY TUMBLE(time_str, INTERVAL '2' MINUTE),aaa;
+-----+-------------+-------------+
| +/- | aaa | bbc |
+-----+-------------+-------------+
| + | 111 | 222 |
| + | 111 | 777 |
| + | 666 | 777 |
| + | 111 | 100 |
| + | 100 | 101 |
| + | 111 | 102 |
+-----+-------------+-------------+
Received a total of 6 rows--注意窗口操作的时候需要指定时间属性
--注意数据源与flink 数据类型 DATETIME(mysql)-->TIMESTAMP(flink)
CREATE TABLE table_name (aaa INT,bbb INT,ccc INT,time_str TIMESTAMP(3),WATERMARK FOR time_str AS time_str
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:3306/test','table-name' = 'table_name','username' = 'root','password' = 'Wang32?_#@%')
--WATERMARK 定义了表的事件时间属性WATERMARK 定义了表的事件时间属性,其形式为 WATERMARK FOR rowtime_column_name AS watermark_strategy_expression 。Flink 提供了几种常用的 watermark 策略。watermark_strategy_expression 定义了 watermark 的生成策略。它允许使用包括计算列在内的任意非查询表达式来计算 watermark ;表达式的返回类型必须是 TIMESTAMP(3),表示了从 Epoch 以来的经过的时间严格递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column。发出到目前为止已观察到的最大时间戳的 watermark ,时间戳大于最大时间戳的行被认为没有迟到。递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '0.001' SECOND。发出到目前为止已观察到的最大时间戳减 1 的 watermark ,时间戳大于或等于最大时间戳的行被认为没有迟到。有界乱序时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL 'string' timeUnit。
--很多和标准SQL 差不多这里就不 一一敲了 以下语法都是从官方文档复制的。SELECT * FROM OrdersSELECT a, c AS d FROM OrdersSELECT * FROM Orders WHERE b = 'red'SELECT * FROM Orders WHERE a % 2 = 0/*--PRETTY_PRINT 用户自定义函数
--自定义函数必须事先注册到 TableEnvironment 中。
--可阅读 自定义函数文档 以获得如何指定和注册自定义函数的详细信息。*/SELECT PRETTY_PRINT(user) FROM Orders--分组聚合 group
SELECT a, SUM(b) as d
FROM Orders
GROUP BY a--窗口聚合TUMBLE 滚动窗口
SELECT user, SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' DAY), user--Over Window aggregation
--ORDER BY 必须指定于单个的时间属性。
--ROWS BETWEEN 2 PRECEDING AND CURRENT ROW 指定范围 前两行到当前行
SELECT COUNT(amount) OVER (PARTITION BY userORDER BY proctimeROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
FROM Orders--窗口
SELECT COUNT(amount) OVER w, SUM(amount) OVER w
FROM Orders
WINDOW w AS (PARTITION BY userORDER BY proctimeROWS BETWEEN 2 PRECEDING AND CURRENT ROW) SELECT DISTINCT users FROM Orders--流式 Grouping sets、Rollup 以及 Cube 只在 Blink planner 中支持。
SELECT SUM(amount)
FROM Orders
GROUP BY GROUPING SETS ((user), (product)) --having
SELECT SUM(amount)
FROM Orders
GROUP BY users
HAVING SUM(amount) > 50--用户自定义UDF
SELECT MyAggregate(amount)
FROM Orders
GROUP BY users--等值链接 目前只支撑等值
/*注意事项
目前仅支持 equi-join ,即 join 的联合条件至少拥有一个相等谓词。
不支持任何 cross join 和 theta join。
注意: Join 的顺序没有进行优化,join 会按照 FROM 中所定义的顺序依次执行。
请确保 join 所指定的表在顺序执行中不会产生不支持的 cross join (笛卡儿积)以至查询失败。
*/SELECT *
FROM Orders INNER JOIN Product ON Orders.productId = Product.id--左链接,右链接,全链接Outer Equi-join
SELECT *
FROM Orders LEFT JOIN Product ON Orders.productId = Product.idSELECT *
FROM Orders RIGHT JOIN Product ON Orders.productId = Product.idSELECT *
FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id--Interval join (时间区间关联)必须要有一个时间作为关联条件
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.orderId ANDo.ordertime BETWEEN s.shiptime - INTERVAL '4' HOUR AND s.shiptime--Expanding arrays into a relation 将数组展开为一个关系
SELECT users, tag
FROM Orders CROSS JOIN UNNEST(tags) AS t (tag)--Join 表函数 (UDTF)
/*
Inner Join
将表与表函数的结果进行 join 操作。
左表(outer)中的每一行将会与调用表函数所产生的所有结果中相关联行进行 join 。
*/
SELECT users, tag
FROM Orders, LATERAL TABLE(unnest_udtf(tags)) AS t(tag)--当前仅支持文本常量 TRUE 作为针对横向表的左外部联接的谓词。
SELECT users, tag
FROM Orders LEFT JOIN LATERAL TABLE(unnest_udtf(tags)) AS t(tag) ON TRUE---Temporal Tables 是跟随时间变化而变化的表。
SELECTo_amount, r_rate
FROMOrders,LATERAL TABLE (Rates(o_proctime))
WHEREr_currency = o_currency--Join Temporal Tables
/*
Temporal Tables 是随时间变化而变化的表。 Temporal Table 提供访问指定时间点的 temporal table 版本的功能。仅支持带有处理时间的 temporal tables 的 inner 和 left join。下述示例中,假设 LatestRates 是一个根据最新的 rates 物化的 Temporal Table 。
*/
--仅 Blink planner 支持。
SELECTo.amout, o.currency, r.rate, o.amount * r.rate
FROMOrders AS oJOIN LatestRates FOR SYSTEM_TIME AS OF o.proctime AS rON r.currency = o.currency--集合操作--集合操作--集合操作--Union
SELECT *
FROM ((SELECT user FROM Orders WHERE a % 2 = 0)UNION(SELECT user FROM Orders WHERE b = 0)
)--UnionAll
SELECT *
FROM ((SELECT user FROM Orders WHERE a % 2 = 0)UNION ALL(SELECT user FROM Orders WHERE b = 0)
)--Intersect 交集 / Except 除了
SELECT *
FROM ((SELECT user FROM Orders WHERE a % 2 = 0)INTERSECT(SELECT user FROM Orders WHERE b = 0)
)SELECT *
FROM ((SELECT user FROM Orders WHERE a % 2 = 0)EXCEPT(SELECT user FROM Orders WHERE b = 0)
)--in
/*
在流查询中,这一操作将会被重写为 join 和 group 操作。
该查询所需要的状态可能会由于不同的输入行数而导致无限增长。
请在查询配置中提合理的保留间隔以避免产生状态过大。
*/
SELECT user, amount
FROM Orders
WHERE product IN (SELECT product FROM NewProducts
)--Exists
SELECT user, amount
FROM Orders
WHERE product EXISTS (SELECT product FROM NewProducts
)--OrderBy & Limit
SELECT *
FROM Orders
ORDER BY orderTimeSELECT *
FROM Orders
ORDER BY orderTime
LIMIT 3--TOP-N
/*
Top-N 的唯一键是分区列和 rownum 列的结合,另外 Top-N 查询也可以获得上游的唯一键。
以下面的任务为例,product_id 是 ShopSales 的唯一键,然后 Top-N 的唯一键是 [category, rownum] 和 [product_id]
*/
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownumFROM table_name)
WHERE rownum <= N [AND conditions]--去重
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]ORDER BY time_attr [asc|desc]) AS rownumFROM table_name)
WHERE rownum = 1--一些辅助函数---注意: 辅助函数必须使用与 GROUP BY 子句中的分组窗口函数完全相同的参数来调用.
Table result1 = tableEnv.sqlQuery("SELECT user, " +" TUMBLE_START(rowtime, INTERVAL &#39;1&#39; DAY) as wStart, " +" SUM(amount) FROM Orders " +"GROUP BY TUMBLE(rowtime, INTERVAL &#39;1&#39; DAY), user")--返回相对应的滚动、滑动和会话窗口范围内的下界时间戳。
TUMBLE_START(time_attr, interval)
HOP_START(time_attr, interval, interval)
SESSION_START(time_attr, interval)/*
返回相对应的滚动、滑动和会话窗口范围以外的上界时间戳。注意: 范围以外的上界时间戳不可以 在随后基于时间的操作中,作为 行时间属性 使用,比如 interval join 以及 分组窗口或分组窗口上的聚合。
*/
TUMBLE_END(time_attr, interval)
HOP_END(time_attr, interval, interval)
SESSION_END(time_attr, interval)/*
返回相对应的滚动、滑动和会话窗口范围以内的上界时间戳。返回的是一个可用于后续需要基于时间的操作的时间属性(rowtime attribute),比如interval join 以及 分组窗口或分组窗口上的聚合。
*/TUMBLE_ROWTIME(time_attr, interval)
HOP_ROWTIME(time_attr, interval, interval)
SESSION_ROWTIME(time_attr, interval)/*
返回一个可用于后续需要基于时间的操作的 处理时间参数,比如interval join 以及 分组窗口或分组窗口上的聚合.
*/
TUMBLE_PROCTIME(time_attr, interval)
HOP_PROCTIME(time_attr, interval, interval)
SESSION_PROCTIME(time_attr, interval)--模式匹配/*
根据 MATCH_RECOGNIZE ISO 标准在流处理表中搜索给定的模式。 这样就可以在SQL查询中描述复杂的事件处理(CEP)逻辑。更多详情请参考 检测表中的模式.
*/
SELECT T.aid, T.bid, T.cid
FROM MyTable
MATCH_RECOGNIZE (PARTITION BY useridORDER BY proctimeMEASURESA.id AS aid,B.id AS bid,C.id AS cidPATTERN (A B C)DEFINEA AS name = &#39;a&#39;,B AS name = &#39;b&#39;,C AS name = &#39;c&#39;
) AS T--case when 尽量用 FILTER 替换
SELECTday,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT CASE WHEN flag IN (&#39;android&#39;, &#39;iphone&#39;) THEN user_id ELSE NULL END) AS app_uv,COUNT(DISTINCT CASE WHEN flag IN (&#39;wap&#39;, &#39;other&#39;) THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day
--
SELECTday,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT user_id) FILTER (WHERE flag IN (&#39;android&#39;, &#39;iphone&#39;)) AS app_uv,COUNT(DISTINCT user_id) FILTER (WHERE flag IN (&#39;wap&#39;, &#39;other&#39;)) AS web_uv
FROM T
GROUP BY day-----------------creat table -------------------creat table -------------------creat table -------------------creat table -------------------creat table -------------------creat table -------------------creat table --
--创建表
CREATE TABLE [catalog_name.][db_name.]table_name({
{{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]*/
/*
注意事项:列里面计算不能有子查询,达式可以包含物理列、常量、函数或变量的任意组合定义在一个数据源表( source table )上的计算列会在从数据源读取数据后被计算,它们可以在 SELECT 查询语句中使用。
计算列不可以作为 INSERT 语句的目标,在 INSERT 语句中,SELECT 语句的 schema 需要与目标表不带有计算列的 schema 一致。
*/
-----一些实列--------一些实列--------一些实列--------一些实列--------一些实列---
CREATE TABLE Orders (user BIGINT,product STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL &#39;5&#39; SECOND
) WITH ( . . . );--主键 PRIMARY KEY flink 不作存储数据,他不会检查是否唯一,需要用户自己保证
--分区 PARTITIONED BY 根据指定的列对已经创建的表进行分区。若表使用 filesystem sink ,则将会为每个分区创建一个目录。--WATERMARK 定义了表的事件时间属性,其形式为 WATERMARK FOR rowtime_column_name AS watermark_strategy_expression /*
WITH OPTIONS
表属性用于创建 table source/sink ,一般用于寻找和创建底层的连接器。
*/--LIKE 子句可以基于现有表的定义去创建新表,并且可以扩展或排除原始表中的某些部分CREATE TABLE Orders (user BIGINT,product STRING,order_time TIMESTAMP(3)
) WITH ( &#39;connector&#39; = &#39;kafka&#39;,&#39;scan.startup.mode&#39; = &#39;earliest-offset&#39;
);--这里用like 创建了一个新表并增加了一些属性
CREATE TABLE Orders_with_watermark (-- 添加 watermark 定义WATERMARK FOR order_time AS order_time - INTERVAL &#39;5&#39; SECOND
) WITH (-- 改写 startup-mode 属性&#39;scan.startup.mode&#39; = &#39;latest-offset&#39;
)
LIKE Orders;--等效语句
CREATE TABLE Orders_with_watermark (user BIGINT,product STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL &#39;5&#39; SECOND
) WITH (&#39;connector&#39; = &#39;kafka&#39;,&#39;scan.startup.mode&#39; = &#39;latest-offset&#39;
);/*
表属性的合并逻辑可以用 like options 来控制。
可以控制合并的表属性如下:
CONSTRAINTS - 主键和唯一键约束
GENERATED - 计算列
OPTIONS - 连接器信息、格式化方式等配置项
PARTITIONS - 表分区信息
WATERMARKS - watermark 定义
并且有三种不同的表属性合并策略:
INCLUDING - 新表包含源表(source table)所有的表属性,如果和源表的表属性重复则会直接失败,例如新表和源表存在相同 key 的属性。
EXCLUDING - 新表不包含源表指定的任何表属性。
OVERWRITING - 新表包含源表的表属性,但如果出现重复项,则会用新表的表属性覆盖源表中的重复表属性,例如,两个表中都存在相同 key 的属性,则会使用当前语句中定义的 key 的属性值。
*/--instance
-- 存储在文件系统的源表
CREATE TABLE Orders_in_file (user BIGINT,product STRING,order_time_string STRING,order_time AS to_timestamp(order_time))
PARTITIONED BY user
WITH ( &#39;connector&#39; = &#39;filesystem&#39;&#39;path&#39; = &#39;...&#39;
);-- 对应存储在 kafka 的源表
CREATE TABLE Orders_in_kafka (-- 添加 watermark 定义WATERMARK FOR order_time AS order_time - INTERVAL &#39;5&#39; SECOND
) WITH (&#39;connector&#39;: &#39;kafka&#39;...
)
LIKE Orders_in_file (-- 排除需要生成 watermark 的计算列之外的所有内容。-- 去除不适用于 kafka 的所有分区和文件系统的相关属性。EXCLUDING ALLINCLUDING GENERATED
);---创建目录--
CREATE CATALOG catalog_nameWITH (key1=val1, key2=val2, ...)---创建数据库
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name[COMMENT database_comment]WITH (key1=val1, key2=val2, ...)/*
IF NOT EXISTS
若数据库已经存在,则不会进行任何操作。
WITH OPTIONS
数据库属性一般用于存储关于这个数据库额外的信息。 表达式 key1=val1 中的键和值都需要是字符串文本常量。
*/ ---创建视图
CREATE [TEMPORARY] VIEW [IF NOT EXISTS] [catalog_name.][db_name.]view_name[{columnName [, columnName ]* }] [COMMENT view_comment]AS query_expression/*
TEMPORARY
创建一个有 catalog 和数据库命名空间的临时视图,并覆盖原有的视图。
IF NOT EXISTS
若该视图已经存在,则不会进行任何操作。
*/ ---创建一个函数
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION[IF NOT EXISTS] [[catalog_name.]db_name.]function_nameAS identifier [LANGUAGE JAVA|SCALA|PYTHON]/*
如果 language tag 是 JAVA 或者 SCALA ,则 identifier 是 UDF 实现类的全限定名。关于 JAVA/SCALA UDF 的实现,请参考 自定义函数。
如果 language tag 是 PYTHON ,则 identifier 是 UDF 对象的全限定名,例如 pyflink.table.tests.test_udf.add。关于 PYTHON UDF 的实现,请参考 Python UDFs。TEMPORARY
创建一个有 catalog 和数据库命名空间的临时 catalog function ,并覆盖原有的 catalog function 。TEMPORARY SYSTEM
创建一个没有数据库命名空间的临时系统 catalog function ,并覆盖系统内置的函数。IF NOT EXISTS
若该函数已经存在,则不会进行任何操作。LANGUAGE JAVA|SCALA|PYTHON
Language tag 用于指定 Flink runtime 如何执行这个函数。目前,只支持 JAVA, SCALA 和 PYTHON,且函数的默认语言为 JAVA。
*/---------drop------------drop------------drop------------drop------------drop------------drop------------drop--------
--删除表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name--删除数据库:
/*
RESTRICT
当删除一个非空数据库时,会触发异常。(默认为开)CASCADE
删除一个非空数据库时,把相关联的表与函数一并删除。
*/
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]--删除视图
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name--删除函数
/*
TEMPORARY
删除一个有 catalog 和数据库命名空间的临时 catalog function。TEMPORARY SYSTEM
删除一个没有数据库命名空间的临时系统函数。
*/
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER-----ALTER---重命名表
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name--修改表的属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)---修改数据库属性
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)---修改函数
/*
TEMPORARY
修改一个有 catalog 和数据库命名空间的临时 catalog function ,并覆盖原有的 catalog function 。TEMPORARY SYSTEM
修改一个没有数据库命名空间的临时系统 catalog function ,并覆盖系统内置的函数。IF EXISTS
若函数不存在,则不进行任何操作。LANGUAGE JAVA|SCALA|PYTHON
Language tag 用于指定 Flink runtime 如何执行这个函数。目前,只支持 JAVA,SCALA 和 PYTHON,且函数的默认语言为 JAVA。
*/
ALTER [TEMPORARY|TEMPORARY SYSTEM] FUNCTION[IF EXISTS] [catalog_name.][db_name.]function_nameAS identifier [LANGUAGE JAVA|SCALA|PYTHON]----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT----INSERT
--语法
/*
OVERWRITE
INSERT OVERWRITE 将会覆盖表中或分区中的任何已存在的数据。否则,新数据会追加到表中或分区中。--这个需要实现底层的一个方法INSERT OVERWRITE requires that the underlying DynamicTableSink of table &#39;default_catalog.default_database.table_name1&#39; implements the SupportsOverwrite interface.PARTITION
PARTITION 语句应该包含需要插入的静态分区列与值。
*/
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name [PARTITION part_spec] select_statementpart_spec:(part_col_name1=val1 [, part_col_name2=val2, ...])--实例 -- 创建一个分区表
CREATE TABLE country_page_view (user STRING, cnt INT, date STRING, country STRING)
PARTITIONED BY (date, country)
WITH (...)-- 追加行到该静态分区中 (date=&#39;2019-8-30&#39;, country=&#39;China&#39;)
INSERT INTO country_page_view PARTITION (date=&#39;2019-8-30&#39;, country=&#39;China&#39;)SELECT user, cnt FROM page_view_source;-- 追加行到分区 (date, country) 中,其中 date 是静态分区 &#39;2019-8-30&#39;;country 是动态分区,其值由每一行动态决定
INSERT INTO country_page_view PARTITION (date=&#39;2019-8-30&#39;)SELECT user, cnt, country FROM page_view_source;-- 覆盖行到静态分区 (date=&#39;2019-8-30&#39;, country=&#39;China&#39;)
INSERT OVERWRITE country_page_view PARTITION (date=&#39;2019-8-30&#39;, country=&#39;China&#39;)SELECT user, cnt FROM page_view_source;-- 覆盖行到分区 (date, country) 中,其中 date 是静态分区 &#39;2019-8-30&#39;;country 是动态分区,其值由每一行动态决定
INSERT OVERWRITE country_page_view PARTITION (date=&#39;2019-8-30&#39;)SELECT user, cnt, country FROM page_view_source;--直接插入值
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name VALUES values_row [, values_row ...]values_row:: (val1 [, val2, ...])--实例
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);INSERT INTO studentsVALUES (&#39;fred flintstone&#39;, 35, 1.28), (&#39;barney rubble&#39;, 32, 2.32);--------------------SQL Hints--------------------SQL Hints--------------------SQL Hints--------------------SQL Hints--------------------SQL Hints--------------------SQL Hints
/*
禁止使用默认的动态表选项,因为它可能会更改查询的语义。
您需要将config选项table.dynamic-table-options.enabled设置为true显式(默认为false)。
有关如何设置config选项的详细信息-PY
# instantiate table environment
t_env = ...# access flink configuration
cOnfiguration= t_env.get_config().get_configuration();
# set low-level key-value options
configuration.set_string("table.exec.mini-batch.enabled", "true");
configuration.set_string("table.exec.mini-batch.allow-latency", "5 s");
configuration.set_string("table.exec.mini-batch.size", "5000");具体选项见官方文档
*/--语法
table_path /*+ OPTIONS(key=val [, key=val]*) */key:stringLiteral
val:stringLiteral--实例:具体有那些选项看,官方Table API & SQL 配置
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);-- override table options in query source
select id, name from kafka_table1 /*+ OPTIONS(&#39;scan.startup.mode&#39;=&#39;earliest-offset&#39;) */;-- override table options in join
select * fromkafka_table1 /*+ OPTIONS(&#39;scan.startup.mode&#39;=&#39;earliest-offset&#39;) */ t1joinkafka_table2 /*+ OPTIONS(&#39;scan.startup.mode&#39;=&#39;earliest-offset&#39;) */ t2on t1.id = t2.id;-- override table options for INSERT target table
insert into kafka_table1 /*+ OPTIONS(&#39;sink.partitioner&#39;=&#39;round-robin&#39;) */ select * from kafka_table2;----查看表字段
DESCRIBE [catalog_name.][db_name.]table_name---查看执行计划
EXPLAIN PLAN FOR
USE CATALOG catalog_name
USE [catalog_name.]database_name---show ---show ---show ---show ---show ---show ---show ---show ---show
Flink SQL> SHOW CATALOGS
SHOW CURRENT CATALOG
SHOW DATABASES
SHOW CURRENT DATABASE
SHOW TABLES
SHOW VIEWS
SHOW FUNCTIONS--beta版本
Flink SQL> SHOW MODULES;----------------函数的一些概念----------------函数的一些概念----------------函数的一些概念----------------函数的一些概念----------------函数的一些概念/*Flink 中的函数有两个划分标准
一个划分标准是:系统(内置)函数和 Catalog 函数。
系统函数没有名称空间,只能通过其名称来进行引用。
Catalog 函数属于 Catalog 和数据库,因此它们拥有 Catalog 和数据库命名空间。
用户可以通过全/部分限定名(catalog.db.func 或 db.func)或者函数名 来对 Catalog 函数进行引用。另一个划分标准是:临时函数和持久化函数。
临时函数始终由用户创建,它容易改变并且仅在会话的生命周期内有效。
持久化函数不是由系统提供,就是存储在 Catalog 中,它在会话的整个生命周期内都有效。Flink 4 种函数临时性系统函数系统函数临时性 Catalog 函数Catalog 函数--临时优先有持久化--系统优先 Catalog--具体用到什么函数请查官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/functions/systemFunctions.html
*/--精确函数引用:精确函数引用允许用户跨 Catalog,跨数据库调用 Catalog 函数
/*
解析顺序如下:临时性 catalog 函数
Catalog 函数
模糊函数引用
*/
select mycatalog.mydb.myfunc(x) from mytable select mydb.myfunc(x) from mytable--模糊函数引用:在模糊函数引用中,用户只需在 SQL 查询中指定函数名
/*
解析顺序如下:临时性系统函数
系统函数
临时性 Catalog 函数, 在会话的当前 Catalog 和当前数据库中
Catalog 函数, 在会话的当前 Catalog 和当前数据库中
*/
select myfunc(x) from mytable-----SQL客户端配置--------SQL客户端配置--------SQL客户端配置--------SQL客户端配置--------SQL客户端配置--------SQL客户端配置--------SQL客户端配置--------SQL客户端配置-----启动客户端 embedded 嵌入式
--SQL 客户端将从 ./conf/sql-client-defaults.yaml 中读取配置
./bin/sql-client.sh embedded--检查启动是否正确
SELECT &#39;Hello World&#39;;--客户端命令行展示模式选择: 3种ingmoshi,一般选择tableau
SET execution.result-mode=table;
SET execution.result-mode=changelog;
SET execution.result-mode=tableau;------------一些中间件概念------------------一些中间件概念------------------一些中间件概念------------------一些中间件概念------------------一些中间件概念------Debezium 是一个 CDC(Changelog Data Capture,变更数据捕获)的工具,
可以把来自 MySQL、PostgreSQL、Oracle、Microsoft SQL Server 和许多其他数据库的更改实时流式传输到 Kafka 中。
Debezium 为变更日志提供了统一的格式结构,并支持使用 JSON 和 Apache Avro 序列化消息。Canal是一个CDC(ChangeLog数据捕获,变更日志数据捕获)工具,
可以实时地将MySQL变更传输到其他系统。Canal为变更日志提供了统一的数据格式,
并支持使用JSON或protobuf序列化消息(Canal默认使用protobuf)。Maxwell是CDC(Changelog数据捕获)工具,
可以将MySQL中的更改实时流式传输到Kafka,
Kinesis和其他流式连接器中。
Maxwell为变更日志提供了统一的格式架构,并支持使用JSON序列化消息。
希望能帮到想学习flink的小伙伴。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有